如何在 BGP 模式下完美融合 Calico 與 MetalLB

最近我司業務擴展在機房新開了一個區域,折騰了一段時間的 Calico BGP,為了能將整個過程梳理得更簡單明了,我還是決定將這個過程記錄下來。不管是對當下的總結還是未來重新審視方案都是值得的。大家都知道,云原生下的網絡架構在 Kubernetes 里可以算是百花齊放,各有所長,這無形中也導致網絡始終是橫在廣大 K8S 愛好者面前邁向高階管理的幾座大山之一。
通常大家在公有云上使用廠家提供的 CNI 組件可能還感受不到其復雜,但一旦要在 IDC 自建集群時,就會面臨 Kubernetes 網絡架構選型的問題。Calico 作為目前 Kubernetes 上用途最廣的 Kubernetes CNI 之一,自然也有很多追隨者。而本篇便是在自建機房內 BGP 組網下的一次總結。
關于 CNI 選型
云原生 CNI 組件這么多,諸如老牌的 Flannel、Calico、WeaveNet、Kube-Router 以及近兩年興起的 Antrea、 Kube-OVN 和 Cilium。它們都在各自的場景下各有所長,在選擇前我們可以先對其做一個簡單的功能性的比較:
Flannel | Calico | Cilium | WeaveNet | Antrea | Kube-OVN | |
部署模式 | DaemonSet | DaemonSet | DaemonSet | DaemonSet | DaemonSet | DaemonSet |
包封裝與路由 | VxLAN | IPinIP,BGP,eBPF | VxLAN,eBPF | VxLAN | Vxlan | Vlan/Geneve/BGP |
網絡策略 | No | Yes | Yes | Yes | Yes | Yes |
存儲引擎 | Etcd | Etcd | Etcd | No | Etcd | Etcd |
傳輸加密 | Yes | Yes | Yes | Yes | Yes | No |
運營模式 | 社區 | Tigera | 社區 | WeaveWorks | VMware | 靈雀云 |
- 說明:傳輸加密主要以支持 WireGuard 或 IPSec 來評估
此外關于CNI 性能部分,我們也可以透過一份 2020 年的 CNI 性能測試報告《Benchmark results of Kubernetes network plugins (CNI) over 10Gbit/s network》 來選擇。
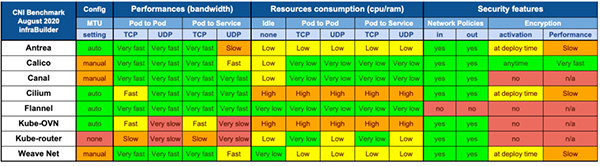
- 上述性能測試原始數據:https://docs.google.com/spreadsheets/d/12dQqSGI0ZcmuEy48nA0P_bPl7Yp17fNg7De47CYWzaM/edit?ouid=118246426051561359914&usp=sheets_home&ths=true
為什么選擇 Calico
在對我司機房新區域的網絡選型上,我們最終選擇了 Calico 作為云端網絡解決方案,在這里我們簡單闡述下為什么選擇 Calico 的幾點原因:
- 支持 BGP 廣播,Calico 通過 BGP 協議廣播路由信息,且架構非常簡單。在 kubernetes 可以很容易的實現 mesh to mesh 或者 RR 模式,在后期如果要實現容器跨集群網絡通信時,實現也很容易。
- Calico配置簡單,且配置都是通過 Kubernetes 中的 CRD 來進行集中式的管理,通過操作 CR 資源,我們可以直接對集群內的容器進行組網和配置的實時變更
- 豐富的功能及其兼容性,考慮到集群內需要與三方應用兼容,例如配置多租戶網絡、固定容器 IP 、網絡策略等功能又或者與 Istio、MetalLB、Cilium 等組件的兼容,Calico 的的表現都非常不錯
- 高性能, Calico 的數據面采用 HostGW 的方式,由于是一個純三方的數據通信,所以在實際使用下性能和主機資源占用方面不會太差,至少也能排在第一梯隊
結合我司機房新區域采購的是 H3C S9 系列的交換機,支持直接在接入層的交換機側開啟路由反射器。所以最終我們選擇Calico 并以 BGP RR 的模式作為 Kubernetes 的 CNI 組件便水到渠成。
關于 MetalLB
在講 MetalLB 之前,先回顧下應用部署在 Kubernetes 中,它的下游服務是如何訪問的吧。通常有如下幾種情況
集群內請求:
直接通過 Kubernetes 的 Service 訪問應用。
集群外請求:
- 通過 NodePort 在主機上以 nat 方式將流量轉發給容器,優點配置簡單且能提供簡單的負載均衡功能, 缺點也很明顯下游應用只能通過主機地址+端口來做尋址
- 通過 Ingress-nginx 做應用層的 7 層轉發,優點是路由規則靈活,且流量只經過一層代理便直達容器,效率較高。缺點是 ingress-nginx 本身的服務還是需要通過 NodePort 或者 HostNetwork 來支持
可以看到在沒有外部負載均衡器的引入之前,應用部署在 kubernetes 集群內,它對南北向流量的地址尋址仍然不太友好。也許有的同學就說了,我在公有云上使用 Kubernetes 時,將 Service 類型設置成 LoadBalancer,集群就能自動為我的應用創建一條帶負載均衡器地址的 IP供外部服務調用,那我們自己部署的 Kubernetes 集群有沒有類似的東西來實現呢?
當然有!MetalLB 就是在裸金屬服務器下為 Kubernetes 集群誕生的一個負載均衡器項目。
- 事實上當然不止 MetalLB,開源界里面還有其他諸如PureLB、OpenELB等負載均衡產品。不過本文旨在采用 BGP 協議來實現負載均衡,所以重點會偏向 MetelLB
簡單來說,MetalLB包含了兩個組件,Controler用于操作 Service 資源的變更以及IPAM。Speaker用于外廣播地址以及 BGP 的連接。它支持兩種流模式模式即:layer2 和 BGP。
- Layer2 模式
又叫ARP/NDP模式,在此模式下,Kubenretes集群中運行 Speaker 的一臺機器通過 leader 選舉,獲取 Service 的 LoadBalancer IP 的所有權,并使用 ARP 協議將其 IP 和 MAC 廣播出去,以使這些 IP 能夠在本地網絡上可訪問。使用 Layer2 的模式對現有網絡并沒有太多的要求,甚至不需要路由器的支持。不過缺點也顯而易見,LoadBalancer IP 所在的 Node 節點承載了所有的流量,會產生一定的網絡瓶頸。
此外,我們可以簡單的將 Layer2 模式理解為與 Keepalived 原理相似,區別僅為 Layer2 的lead 選舉并不是使用 VRRP 組播來通信。
- BGP 模式
MabelLB 在 BGP 模式下,集群中的所有運行 Speaker 的主機都將與上層交換機建立一條BGP 連接,并廣播其 LoadBalancer 的IP 地址。優點是真正的實現了網絡負載均衡,缺點就是配置相對而言要復雜許多,且需上層路由器支持BGP。
MetalLB with Calico
通過上述的介紹,你可能發現了一個問題:在 BGP 模式的場景下,Calico 和 MetalLB 都需要運行一個 DaemonSet 的 bgp 客戶端在主機上與上層路由器建立 bgp peer,在 Calico 中是 Bird ,MetalLB 中是 Speaker。這就會引出來它們使用上的一些問題。
- BGP 只允許每個節點建立一個會話,如果使用 Calico 并建立了 BGP 路由器會話,MetalLB 無法建立自己的會話。因為這條 BGP會話會被路由器認為是相沖突而拒絕連接
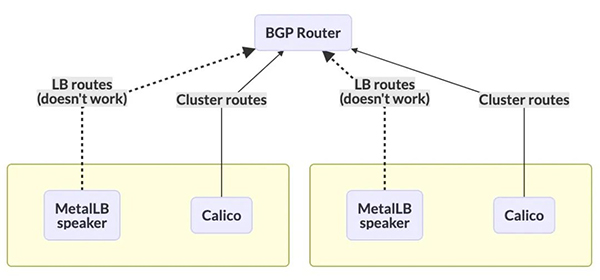
事實上我們傳統的 Fabric 網絡在運用上述方案也遇到此問題,MetalLB 社區也給了 3 個方案來解決:
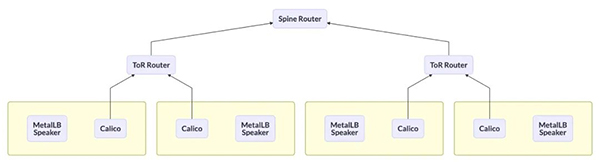
- BGP 與 Tor 交換機連接
- 此方案即 MetalLB 放棄在 Node 節點上部署 Speaker 服務,關于主機上 BGP 路由的廣播統一交給 Calico Bird 處理。這也是 Calico 社區建議采取的方案。
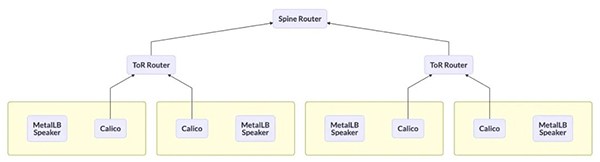
- BGP 與 Spine 交換機連接
此方案讓 MetalLB Speaker 的 BGP Peer 繞過 Tor 路由,直達上層核心路由器。雖然解決了 BGP 連接問題,但是額外帶來了配置的復雜性,以及損失了BGP 連接的擴展性,在大型的數據中心是不被認可的!
- 開啟 VRF-虛擬路由轉發
如果你的網絡硬件支持 VRF(虛擬路由轉發),那就可以將通過虛擬化的方式分別為 Calico Bird 和 MetalLB Speaker 創建獨立的路由表,并建立 BGP 連接。然后再在兩個 VRF 內部之間進行路由
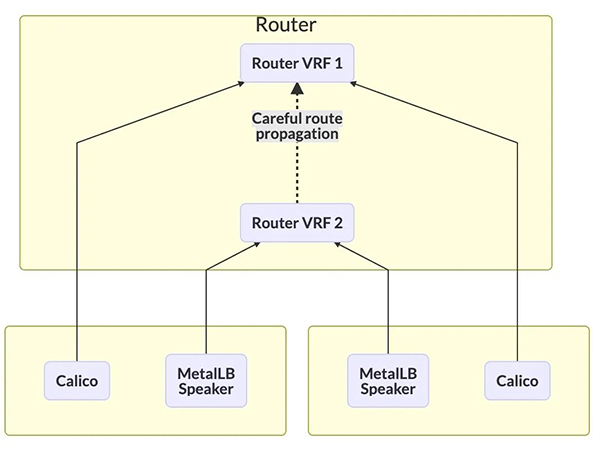
此方案理論上可行,但筆者的數據中心并沒有支持 VRF 功能的路由器,且受限于不同網絡設備廠家的實現方式不同而帶來的操作差異也不可控。所以具體的實現還需每個用戶自行決定。
具體操作
前面談了大段話關于 Calico 和 MetalLB 的使用,本節我們就簡單的部署與配置來完成前面的所說的內容。
網絡上面的一些基本信息:
規劃CIDR | 用途 | 關聯服務 |
10.52.1.0/24 | Kubernetes 主機物理網絡,同時也是 IBGP 連接的承載網絡 | Kubernetes,Calico |
10.59.0.0/16 | Kubernetes 容器默認使用的 IP 地址池 | Calico |
10.96.0.0/12 | Kubenretes Service 內部地址池,即 ClusterIP 區域 | Kubernetes |
10.60.0.0/21 | Kubenretes Service 負載均衡器地址池,即 LoadBalancer IP 區域 | Calico, MetalLB |
IDC 中心的 BGP 信息
BGP | 信息 |
AS 域 | 65001 |
BGP peer | 10.52.1.253,10.52.1.254 |
Calico 部分
- 下載并部署 Calico Manifest 文件,并將文件內容中關于 POD CIDR修改為自己環境下的配置
curl https://projectcalico.docs.tigera.io/manifests/calico.yaml -O
----
containers:
- image: harbor.cloudminds.com/kubegems/calico-node:v3.22.1
name: calico-node
env:
- name: CALICO_IPV4POOL_CIDR
value: 10.59.0.0/16
- 配置 BGP Peering,可根據機房規模選擇 Global BGP Peer和Per-Node Peer。它們之間區別為Global BGP Peer的連接拓撲呈星狀,所有的節點都在一個 AS 域內。Per-Node Peer則可以利用主機標簽進行靈活的接入。
這里由于我們服務器規模不大(<50)可直接采用全局 BGP 連接模式。
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: tor-router-253
spec:
peerIP: 10.52.1.253
asNumber: 65001
---
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: tor-router-254
spec:
peerIP: 10.52.1.254
asNumber: 65001
考慮到 BGP 連接的冗余,實際在使用上,我們可以創建兩個 BGP Peer,防止路由器單點故障。
如果你需要按照機架來劃分 AS 域的話,可以采用 Per-Node Peer 模式,通過 nodeSelector 來實現個性化的連接配置。
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: rack1-tor
spec:
peerIP: 192.20.30.40
asNumber: 64567
nodeSelector: rack == 'rack-1'
- 禁用 Calico NodeToNodeMesh
calicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": false}}'
- 禁用 ipipMode 和vxlan Mode
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
allowedUses:
- Workload
blockSize: 26
cidr: 10.59.0.0/16
ipipMode: Never
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
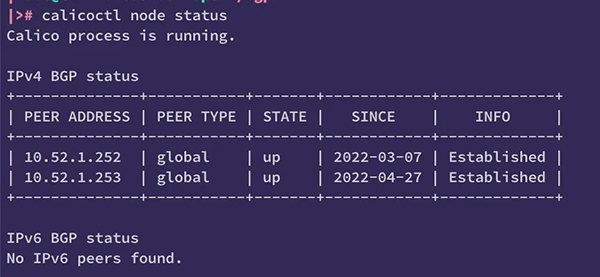
此時,我們使用calicoctl 來查看 BGP 狀態,如果 STATE 為 up,就代表集群內主機的 BGP 連接正常。
MetalLB 部分
- Kube-Proxy 采用 IPVS 的話,需開啟嚴格的 ARP 學習設置。
kubectl edit configmap -n kube-system kube-proxy
----
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:
strictARP: true
如果多臺用戶主機同時向設備發送大量ARP報文,或者攻擊者向設備發送偽造的ARP報文,會出現以下問題:
- 處理 ARP 報文會消耗大量 CPU 資源。設備學習到很多無效的ARP表項,耗盡了ARP表項資源,導致設備無法學習到來自授權用戶的ARP報文的ARP表項,造成用戶的通信被中斷。
- 設備收到偽造的ARP報文后,錯誤地修改了ARP表項。造成用戶無法相互通信。
為避免上述問題,開啟 strictARP 后,設備對發送的ARP請求報文只學習ARP回復報文的ARP表項。這樣,設備就可以防御大部分的ARP攻擊。
- 下載并安裝 MetalLB
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
注意,由于我們不需要 MetalLB 的 Speaker 服務,所以當 MetalLB Controller 運行成功后,可以將 speaker 服務刪除。
kubectl delete daemonset speaker -n metallb-system- 配置 MetalLB 中需要廣播的 BGP 地址范圍,也就是后面 Kubernetes Service 中 LoadBalancer 的地址。
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: bgp
addresses:
- 10.60.0.0/21
Calico 廣播 Kubernetes 服務地址(包含 MetalLB 地址)
得益于 BGP 的使用,Calico 可以很容易的將 Kubernetes 集中的 Service IP 地址像 Pod IP一樣發布到內網。通過使用ECMP(等價多路徑路由)來實現真正的負載均衡。
通常Kubenretes中 Service 中的地址涉及到 3 種類型,即 ClusterIP、ExternalIP 和 LoadBalancerIP。
考慮到我們僅需要將有限的服務通過LoadBalancerIP方式暴露出來。(雖然直接發布 ClusterIP 很酷,但它在某些網絡限制嚴格的場景下是不被接受的)。所以對 Calico 的 BGP 僅需如下配置。
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false
asNumber: 65001
serviceLoadBalancerIPs:
- cidr: 10.60.8.0/21
如果我們需要將 Kubernetes 的控制節點從廣播中排除開來,那么僅需要為控制平面的主機添加如下標簽即可:
kubectl label node control-plane-01 node.kubernetes.io/exclude-from-external-load-balancers=true
路由器
原則上說,在路由器上開啟 BGP 協議是上述所有操作中最先應該開始的工作。但由于每位讀者所在環境中支持BGP 的交換機廠家不盡相同,所以我將此部分挪到最后來說明。我并不是網絡上的專家,這里我只對我們 Calico BGP 網絡的架構做一個簡單說明,讀者在規劃自己的 BGP 網絡時,可與網絡工程師一起合作完成。
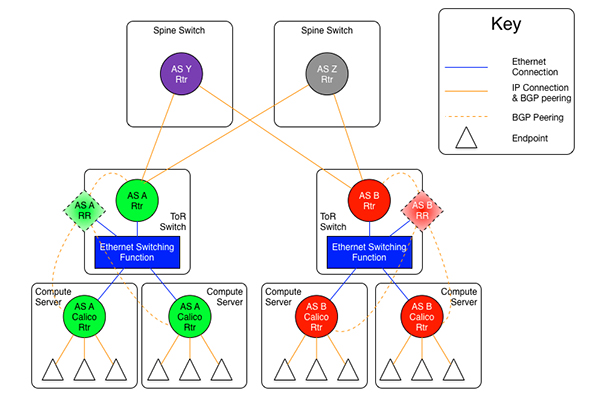
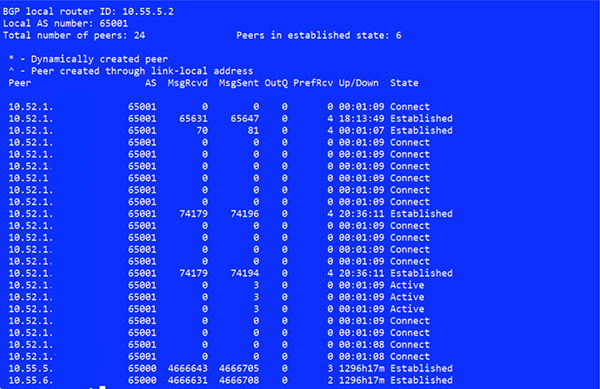
最終當交換機上的路由反射器和 BGP 鄰居創建完成后,Calico 的 Bird 服務便能與反射器建立對等連接,此時連接的狀態如下
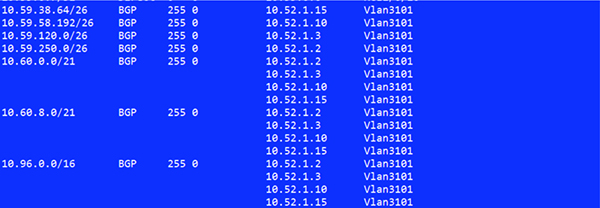
路由表信息如下

可以看到此時,容器的子網路由都明確了下一跳的主機地址,以及公布的LoadBalancer CIRD下一跳地址。
關于 EMCP
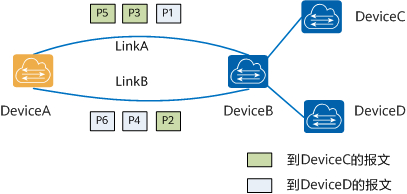
等價多路徑路由ECMP(Equal-Cost Multi-Path routing)實現了等價多路徑負載均衡和鏈路備份的目的。多用于 Layer 3 的負載均衡,用于解決“負載均衡服務器”的單點和擴縮容的問題。既然我們在內部采用了 BGP 網絡,當然也可以在路由器上啟用此功能。
當啟用此功能后,我們在路由表中便可以看到對訪問目標地址是LoadBalancer CIRD網段的路由,下一跳地址可以是多個 Calico 的 Node 主機。
不過在決定啟用 ECMP 之前,你需了解它的背后仍然面臨一些應用上的限制。
當我們使用 BGP 做Layer 3層的負載均衡時,當某一臺主機出現故障后,交換機上通過連接三元組/五元組作為 hash key 進行負載均衡的數據包會被重新發到新的主機上去,由于目的地址變化,當數據包到達新主機時會被直接丟棄,導致連接斷開。這是反應在應用層上的現象就是“Connection reset by peer”
當然我們可以使用一些其他方法來規避和縮小上述現象的影響范圍,例如:
- 路由器上調整更穩定的等價多路徑路由 ECMP(Equal-Cost Multi-Path routing)算法。當后端集群發生變化時而受到影響較少的連接數。
a. 逐包負載分擔可以提高ECMP的帶寬利用率,使等價多路徑路由分擔更均勻,但存在數據包亂序的問題,需要確保流量接收的設備或終端支持報文亂序組包的功能,實際使用場景很少。
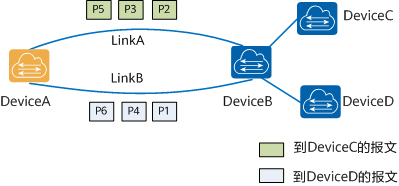
b. 逐流負載分擔能保證包的順序,保證了同一數據流的幀在同一條下一跳路由轉發,而不同數據流在不同的下一跳路由上轉發。
- 服務部署調度時,盡量選擇固定到更小的范圍、或者更穩定的主機組。
- 上層應用需支持網絡連接斷開重試邏輯
- 在 MeltalLB和應用之間再加一層流量控制器(如 ingress-nginx),以此來維護連接狀態的一致性。這樣只有當 ingress-nginx 的規模產生變換時,才會出現上述問題。
總結
本文主要講述在傳統的自建數據中心,利用 Calico 和 MetalLB 來組件內部的 BGP 網絡。并以此來為 Kubernetes 提供 Pod - Pod 、Node - Pod 和 Node - Loadbalancer網絡互訪的能力。