基于 Flink CDC 實現海量數據的實時同步和轉換
?摘要:本文整理自 Apache Flink Committer、Flink CDC Maintainer、阿里巴巴高級開發工程師徐榜江(雪盡)在 5 月 21 日 Flink CDC Meetup 的演講。主要內容包括:
- Flink CDC 技術
- 傳統數據集成方案的痛點
- 基于 Flink CDC 的海量數據的實時同步和轉換
- Flink CDC 社區發展
01Flink CDC 技術

CDC 是 Change Data Capture 的縮寫,是一種捕獲變更數據的技術,CDC 技術很早就存在,發展至今,業界的 CDC 技術方案眾多,從原理上可以分為兩大類:
- 一類是基于查詢的 CDC 技術 ,比如 DataX。隨著當下場景對實時性要求越來越高,此類技術的缺陷也逐漸凸顯。離線調度和批處理的模式導致延遲較高;基于離線調度做切片,因而無法保障數據的一致性;另外,也無法保障實時性。
- 一類是基于日志的 CDC 技術,比如 Debezium、Canal、 Flink CDC。這種 CDC 技術能夠實時消費數據庫的日志,流式處理的模式可以保障數據的一致性,提供實時的數據,可以滿足當下越來越實時的業務需求。

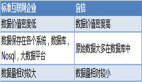
上圖為常見開源 CDC 的方案對比。可以看到 Flink CDC 的機制以及在增量同步、斷點續傳、全量同步的表現都很好,也支持全增量一體化同步,而很多其他開源方案無法支持全增量一體化同步。Flink CDC 是分布式架構,可以滿足海量數據同步的業務場景。依靠 Flink 的生態優勢,它提供了 DataStream API 以及 SQL API,這些 API 提供了非常強大的 transformation 能力。此外,Flink CDC 社區和 Flink 社區的開源生態非常完善,吸引了很多社區用戶和公司在社區開發共建。

Flink CDC 支持全增量一體化同步,為用戶提供實時一致性快照。比如一張表里有歷史的全量數據,也有新增的實時變更數據,增量數據不斷地往 Binlog 日志文件里寫,Flink CDC 會先同步全量歷史數據,再無縫切換到同步增量數據,增量同步時,如果是新增的插入數據(上圖中藍色小塊),會追加到實時一致性快照中;如果是更新的數據(上圖中黃色小塊),則會在已有歷史數據里做更新。
Flink CDC 相當于提供了實時物化視圖,為用戶提供數據庫中表的實時一致性快照,用于可以對這些數據做進一步加工,比如清洗、聚合、過濾等,然后再寫入下游。
02傳統數據集成方案的痛點

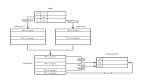
上圖為傳統數據入倉架構 1.0,主要使用 DataX 或 Sqoop 全量同步到 HDFS,再圍繞 Hive 做數倉。
此方案存在諸多缺陷:容易影響業務穩定性,因為每天都需要從業務表里查詢數據;天級別的產出導致時效性差,延遲高;如果將調度間隔調成幾分鐘一次,則會對源庫造成非常大的壓力;擴展性差,業務規模擴大后極易出現性能瓶頸。

上圖為傳統數據入倉 2.0 架構。分為實時和離線兩條鏈路,實時鏈路做增量同步,比如通過 Canal 同步到 Kafka 后再做實時回流;全量同步一般只做一次,與每天的增量在 HDFS 上做定時合并,最后導入到 Hive 數倉里。
此方式只做一次全量同步,因此基本不影響業務穩定性,但是增量同步有定時回流,一般只能保持在小時和天級別,因此它的時效性也比較低。同時,全量與增量兩條鏈路是割裂的,意味著鏈路多,需要維護的組件也多,系統的可維護性會比較差。

上圖為傳統 CDC ETL 分析架構。通過 Debezium、Canal 等工具采集 CDC 數據后,寫入消息隊列,再使用計算引擎做計算清洗,最終傳輸到下游存儲,完成實時數倉、數據湖的構建。

傳統 CDC ETL 分析里引入了很多組件比如 Debezium、Canal,都需要部署和維護, Kafka 消息隊列集群也需要維護。Debezium 的缺陷在于它雖然支持全量加增量,但它的單并發模型無法很好地應對海量數據場景。而 Canal 只能讀增量,需要 DataX 與 Sqoop 配合才能讀取全量,相當于需要兩條鏈路,需要維護的組件也增加。因此,傳統 CDC ETL 分析的痛點是單并發性能差,全量增量割裂,依賴的組件較多。
03基于 Flink CDC 的海量數據的實時同步和轉換
Flink CDC 的方案能夠給海量數據的實時同步和轉換帶來什么改善?

Flink CDC 2.0 在 MySQL CDC 上實現了增量快照讀取算法,在最新的 2.2 版本里 Flink CDC 社區 將增量快照算法抽象成框架,使得其他數據源也能復用增量快照算法。
增量快照算法解決了全增量一體化同步里的一些痛點。比如 Debezium 早期版本在實現全增量一體化同步時會使用鎖,并且且是單并發模型,失敗重做機制,無法在全量階段實現斷點續傳。增量快照算法使用了無鎖算法,對業務庫非常友好;支持了并發讀取,解決了海量數據的處理問題;支持了斷點續傳,避免失敗重做,能夠極大地提高數據同步的效率與用戶體驗。

上圖為全增量一體化的框架。整個框架簡單來講就是將數據庫里的表按 PK 或 UK 切分成 一個個 chunk ,然后分給多個 task 做并行讀取,即在全量階段實現了并行讀取。全量和增量能夠自動切換,切換時通過無鎖算法來做無鎖一致性的切換。切換到增量階段后,只需要單獨的 task 去負責增量部分的數據解析,以此實現了全增量一體化讀取。進入增量階段后,作業不再需要的資源,用戶可以修改作業并發將其釋放。

我們將全增量一體化框架與 Debezium 1.6 版本做 簡單的 TPC-DS 讀取測試對比,customer 單表數據量 6500 萬,在 Flink CDC 用 8 個并發的情況下,吞吐提升了 6.8 倍,耗時僅 13 分鐘,得益于并發讀取的支持,如果用戶需要更快的讀取速度,用戶可以增加并發實現。

Flink CDC 在設計時,也考慮了面向存儲友好的寫入設計。在 Flink CDC 1.x 版本中,如果想實現 exactly-once 同步,需要配合 Flink 提供的 checkpoint 機制,全量階段沒有做切片,則只能在一個 checkpoint 里完成,這會導致一個問題:每個 checkpoint 中間要將這張表的全量數據吐給下游的 writer,writer 會將這張表的全量數據混存在內存中,會對其內存造成非常大的壓力,作業穩定性也特別差。
Flink CDC 2.0 提出了增量快照算法后,通過切片能夠將 checkpoint 粒度降至 chunk, 并且 chunk 大小是用戶可配置的,默認是 8096 條,用戶可以將其調至更小,減輕 writer 的壓力,減少內存資源的使用,提升下游寫入存儲時的穩定性。

全增量一體化之后, Flink CDC 的入湖架構變得非常簡單,且不會影響業務的穩定性;能夠做到分鐘級的產出,也就意味著可以實現近實時或實時分析;并發讀取實現了更高的吞吐,在海量數據場景下有著不俗的表現;鏈路短,組件少,運維友好。

有了 Flink CDC 之后,傳統 CDC ETL 分析的痛點也得到了極大改善,不再需要 Canal、Kafka 消息隊列等組件,只需要依賴 Flink,實現了全增量一體化同步和實時 ETL 加工的能力,且支持并發讀取,整個架構鏈路短,組件少,易于維護。

依托于 Flink DataStream API 以及易用的 SQL API ,Flink CDC 還提供了非常強大完善的 transformation 能力,且在 transformation 過程中能夠保證 changelog 語義。在傳統方案里,在 changelog 上做 transformation 并保證 changelog 語義是非常難以實現的。

海量數據的實時同步和轉換示例 1:Flink CDC 實現異構數據源的集成
這個業務場景是業務表比如產品表和訂單表在 MySQL 數據庫里,物流表存在 PG 數據庫里,要實現異構數據源的集成,并且在集成過程做打寬。需要將產品表、訂單表與物流表做 Streaming Join 之后再將結果表寫入庫里。借助 Flink CDC,整個過程只需要用 5 行 Flink SQL 就能夠實現。這里使用的下游存儲是 Hudi,整個鏈路可以得到分鐘級甚至更低的產出,使圍繞 Hudi 做近實時的分析成為了可能。

海量數據的實時同步和轉換示例 2:Flink CDC 實現分庫分表集成
Flink CDC 對分庫分表做了非常完善的支持,在聲明 CDC 表時支持使用正則表達式匹配庫名和表名,正則表達式意味著可以匹配多個庫以及這多個庫下的多張表。同時提供了 metadata column 的支持,可以知道數據來自于哪個 數據庫、來自于哪張表,寫入下游 Hudi 時,可以帶上 metadata 聲明的兩個列,將 database_name、table_name 以及原始表中的 主鍵(例子中為 id 列)作為新的主鍵,只需三行 Flink SQL 即可實現分庫分表數據的實時集成,非常簡單。

依托于 Flink 豐富的生態,能夠實現很多上下游的擴展,Flink 自身就有豐富的 connector 生態。Flink CDC 加入之后,上游有了更豐富的源可以攝取,下游也有豐富的目的端可以寫入。

海量數據的實時同步和轉換示例 3:三行 SQL 實現單品累計銷量實時排行榜
這個 Demo 演示在無需任何依賴的前提下,通過 3 行 SQL 實現商品的實時排行榜。首先在 Docker 里添加 MySQL 和 ElasticSearch 鏡像, ElasticSearch 是目的端。將 Docker 拉起后,下載 Flink 包以及 MySQL CDC 和 ElasticSearch 的兩個 SQL Connector jar。拉起 Flink 集群和 SQL Client。在 MySQL 內建庫建表,灌入數據,更新后再用 Flink SQL 做一些實時加工和分析,寫入 ES。在 MySQL 的數據庫里構造一張訂單表并插入數據。

上圖第一行 SQL 是創建訂單表,第二行是創建結果表,第三行是做 group by 的查詢實現實時排行榜功能,再寫入到第二行 SQL 創建的 ElasticSearch 表中。

我們在 ElasticSearch 里做了可視化呈現,可以查看到隨著 MySQL 中訂單源源不斷地更新,ElasticSearch 的排行榜會實時刷新。
04Flink CDC 社區發展

在過去的一年多時間,社區發了 4 個大版本, contributor 和 commits數量在不斷增長,社區也越來越活躍。我們一直堅持將核心的 feature 全部提供給社區版,比如 MySQL 的百億級超大表、增量快照框架、MySQL 動態加表等高級功能。

最新的 2.2 版本中同樣新增了很多功能。首先,數據源方面,支持了 OceanBase、PolarDB-X、SqlServer、TiDB。此外,不斷豐富了 Flink CDC 的生態,兼容了 Flink 1.13 和 1.14 集群,提供了增量快照讀取框架。另外,支持了 MySQL CDC 動態加表以及對 MongoDB 做了完善,比如支持指定的集合,通過正則表達式使其更加靈活友好。

除此之外,文檔也是社區特別重要的一部分。我們提供了獨立的版本化社區網站,在網站里不同版本對應不同版本的文檔,提供了豐富的 demo 以及中英文的 FAQ,幫助新手快速入門。

?在社區的多個關鍵指標,比如創建的 issue 數,合并的 PR 數,Github Star 數上,Flink CDC 社區的表現都非常不錯。

Flink CDC 社區的未來規劃主要包含以下三個方面:
- 框架完善:增量快照框架目前只支持 MySQL CDC ,Oracle、PG 和 MongoDB 正在對接中,希望未來所有數據庫都能夠對接到更好的框架上;針對 Schema Evolution 和整庫同步做了一些探索性的工作,成熟后將向社區提供。
- 生態集成:提供更多 DB 和更多版本;數據湖集成方面希望鏈路更通暢;提供一些端到端的方案,用戶無須關心 Hudi 和 Flink CDC 的參數。
- 易用性:提供更多開箱即用的體驗以及完善文檔教程。
Qustions&Answers
Q1:CDC 什么時候能夠支持整庫同步以及 DDL 的同步?
正在設計中,因為它需要考慮到 Flink 引擎側的支持與配合,不是單獨在 Flink CDC 社區內開發就可以實現的,需要與 Flink 社區聯動。
Q2:什么時候支持 Flink 1.15?
目前生產上的 Flink 集群還是以 1.13、1.14 為主。社區計劃在 2.3 版本中支持 Flink 1.15,可以關注 issue:https://github.com/ververica/flink-cdc-connectors/issues/1363,也歡迎貢獻。
Q3:有 CDC 結果表寫入 Oracle 的實踐嗎?
1.14 版本的 Flink 暫不支持,這個是因為 Sink 端的 JDBC Connector 不支持 Oracle dialect,Flink 1.15 版本的 JDBC Connector 已經支持了 Oracle dialect,1.15 版本的 Flink 集群可以支持。
Q4:下個版本能否支持讀取 ES?
還需要考察 transactional log 機制以及它是否適合作為 CDC 的數據源。
Q5:能做到單 job 監控多表 sink 多表嗎?
可以實現單作業監控多表 sink 到多個下游表;但如果是 sink 到多表,需要 DataStream 進行分流,不同的流寫到不同的表。
Q6:Binlog 日志只有最近兩個月的數據,能否支持先全量后增量讀取?
默認支持的就是先全量后增量,一般 binlog 保存七天或兩三天都可以。
Q7:2.2 版本 MySQL 沒有主鍵,全量如何同步?
可以回退到不用增量快照框架;在增量快照框架上,社區已有組件的 issue,預計將在社區 2.3 版本提供支持。?