百億流量全鏈路99.99%高可用架構優秀實踐

一、前情回顧
上篇文章(《?億流量大考(4):自研ES+HBase+純內存的高性能毫秒級查詢引擎?》),聊了一下系統架構中的查詢平臺。
我們采用冷熱數據分離:
- 冷數據基于HBase+Elasticsearch+純內存自研的查詢引擎,解決了海量歷史數據的高性能毫秒級的查詢。
- 熱數據基于緩存集群+MySQL集群做到了當日數據的幾十毫秒級別的查詢性能。
最終,整套查詢架構抗住每秒10萬的并發查詢請求,都沒問題。
本文作為這個架構演進系列的最后一篇文章,我們來聊聊高可用這個話題。所謂的高可用是啥意思呢?
簡單來說,就是如此復雜的架構中,任何一個環節都可能會故障,比如MQ集群可能會掛掉、KV集群可能會掛掉、MySQL集群可能會掛掉。那你怎么才能保證說,你這套復雜架構中任何一個環節掛掉了,整套系統可以繼續運行?
?這就是所謂的全鏈路99.99%高可用架構,因為我們的平臺產品是付費級別的,付費級別,必須要為客戶做到最好,可用性是務必要保證的!
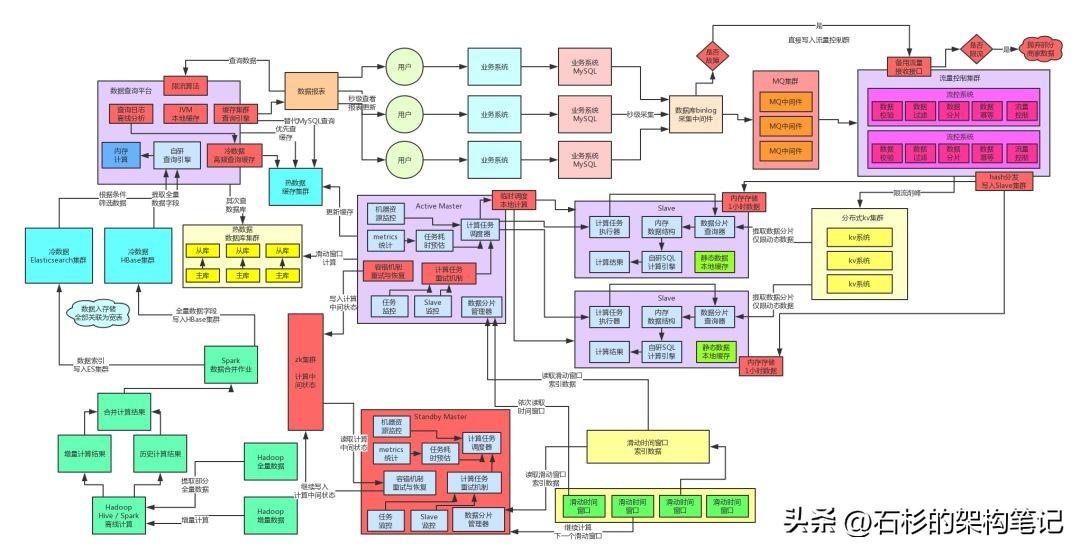
我們先來看看目前為止的架構是長啥樣子的。?
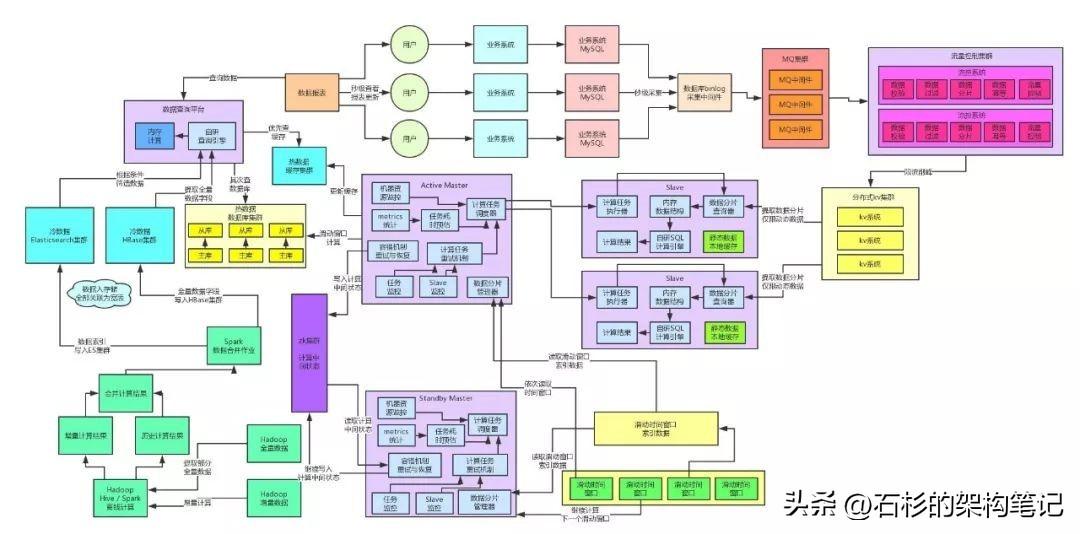
二、MQ集群高可用方案
異步轉同步 + 限流算法 + 限制性丟棄流量
MQ集群故障其實是有概率的,而且挺正常的,因為之前就有的大型互聯網公司,MQ集群故障之后,導致全平臺幾個小時都無法交易,嚴重的會造成幾個小時公司就有數千萬的損失。我們之前也遇到過MQ集群故障的場景,但是并不是這個系統里。
大家想一下,如果這個鏈路中,萬一MQ集群故障了,會發生什么?
看看右上角那個地方,數據庫binlog采集中間件就無法寫入數據到MQ集群了啊,然后后面的流控集群也無法消費和存儲數據到KV集群了。這套架構將會徹底失效,無法運行。
這個是我們想要的效果嗎?那肯定不是的,如果是這樣的效果,這個架構的可用性保障也太差了。
因此在這里,我們針對MQ集群的故障,設計的高可用保障方案是:異步轉同步 + 限流算法 + 限制性丟棄流量。
簡單來說,數據庫binlog采集環節一旦發現了MQ集群故障,也就是嘗試多次都無法寫入數據到MQ集群,此時就會觸發降級策略。不再寫入數據到MQ集群,而是轉而直接調用流控集群提供的備用流量接收接口,直接發送數據給流控集群。
但是流控集群也比較尷尬,之前用MQ集群就是削峰的啊,高峰期可以稍微積壓一點數據在MQ集群里,避免流量過大,沖垮后臺系統。
所以流控集群的備用流量接收接口,都是實現了限流算法的,也就是如果發現一旦流量過大超過了閾值,直接采取丟棄的策略,拋棄部分流量。
但是這個拋棄部分流量也是有講究的,你要怎么拋棄流量?如果你不管三七二十一,胡亂丟棄流量,可能會導致所有的商家看到的數據分析結果都是不準確的。因此當時選擇的策略是,僅僅選擇少量商家的數據全量拋棄,但是大部分商家的數據全量保存。
也就是說,比如你的平臺用戶有20萬吧,可能在這個丟棄流量的策略下,有2萬商家會發現看不到今天的數據了,但是18萬商家的數據是不受影響,都是準確的。但是這個總比20萬商家的數據全部都是不準確的好吧,所以在降級策略制定的時候,都是有權衡的。
這樣的話,在MQ集群故障的場景下,雖然可能會丟棄部分流量,導致最終數據分析結果有偏差,但是大部分商家的數據都是正常的。
大家看看下面的圖,高可用保障環節全部選用淺紅色來表示,這樣很清晰。
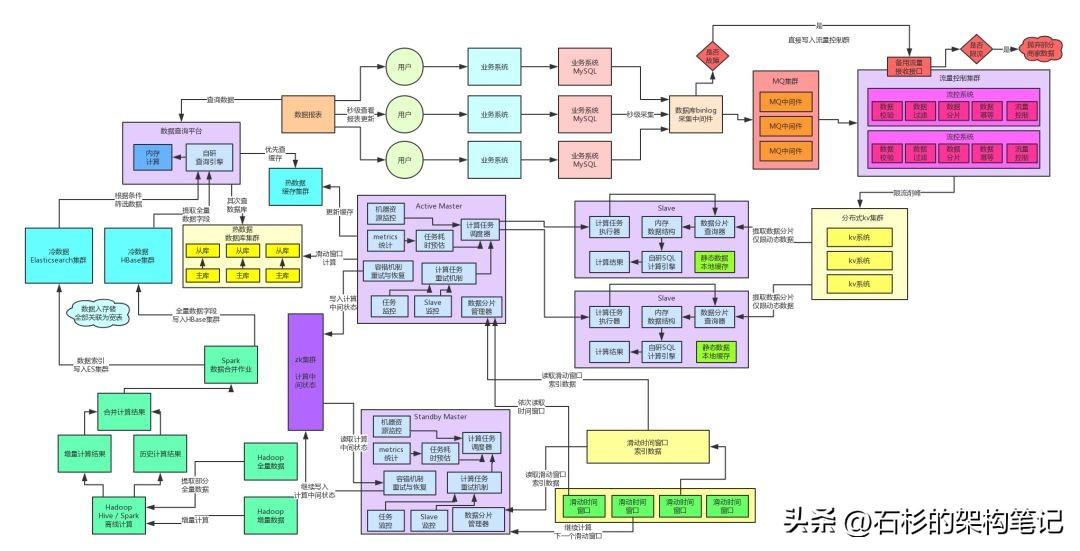
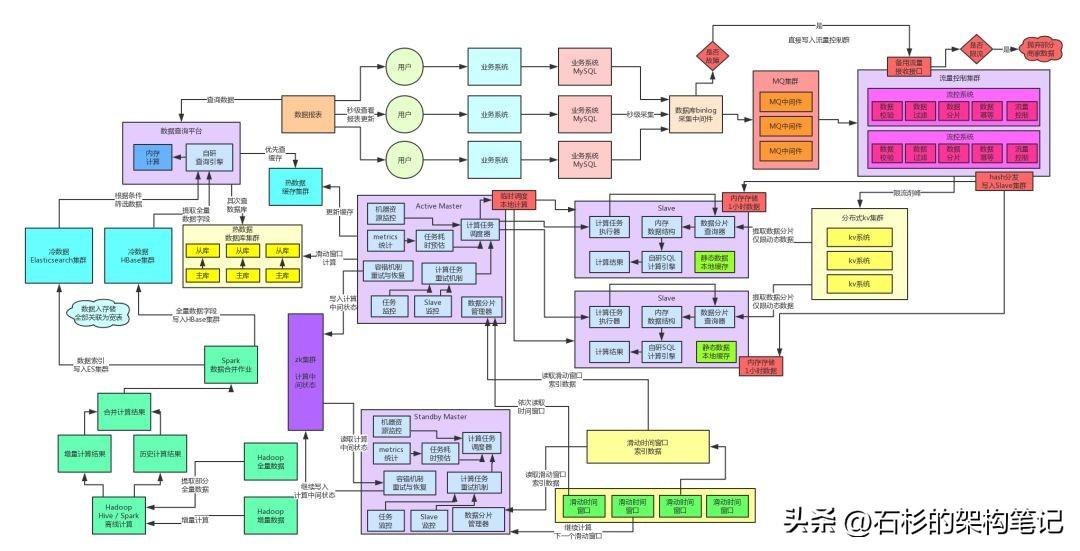
三、KV集群高可用保障方案
臨時擴容Slave集群 + 內存級分片存儲 + 小時級數據粒度
下一個問題,如果KV集群掛了怎么辦?這個問題我們還真的遇到過,不過也不是在這個系統里,是在另外一個我們負責過的核心系統里,KV集群確實出過故障,直接從持續好多個小時,導致公司業務都幾近于停擺,損失也是幾千萬級別的。
?大家看看那個架構圖的右側部分,如果KV集群掛了咋辦?那也是災難性的,因為我們的架構選型里,直接就是基于kv集群來進行海量數據存儲的,要是KV掛了,沒任何高可用保障措施的話,會導致流控集群無法把數據寫入KV集群,此時后續環節就無法繼續計算了。
我們當時考慮過要不要引入另外一套存儲進行雙寫,比如引入一套hbase集群,但是那樣依賴會搞的更加的復雜,打鐵還需自身硬,還是要從自身架構來做優化。
因此,當時選擇的一套kv集群降級的預案是:臨時擴容Slave集群 + 小時級數據粒度 + 內存級分片存儲。
簡單來說,就是一旦發現kv集群故障,直接報警。我們收到報警之后,就會立馬啟動臨時預案,手動擴容部署N倍的Slave?計算集群。
接著同樣會手動打開流控集群的一個降級開關,然后流控集群會直接按照預設的hash算法分發數據到各個Slave計算節點。
這就是關鍵點,不要再基于kv集群存數據了,本身我們的Slave集群就是分布式計算的,那不是剛好可以臨時用作分布式存儲嗎!直接流控集群分發數據到Slave集群就行了,Slave節點將數據留存在內存中即可。
然后Master節點在分發數據計算任務的時候,會保證計算任務分發到某個Slave節點之后,他只要基于本地內存中的數據計算即可。
將Master節點和Slave節點都重構一下,重構成本不會太高,但是這樣就實現了本地數據存儲 + 本地數據計算的效果了。
但是這里同樣有一個問題,要知道當日數據量可是很大的!如果你都放Slave集群內存里還得了?
所以說,既然是降級,又要做一個balance了。我們選擇的是小時級數據粒度的方案,也就是說,僅僅在Slave集群中保存最近一個小時的數據,然后計算數據指標的時候,只能產出每個小時的數據指標。
但是如果是針對一天的數據需要計算出來的數據指標,此時降級過后就無法提供了,因為內存中永遠只有最近一個小時的數據,這樣才能保證Slave集群的內存不會被撐爆。
對用戶而言,就是只能看當天每個小時的數據指標,但是全天匯總的暫時就無法看到。
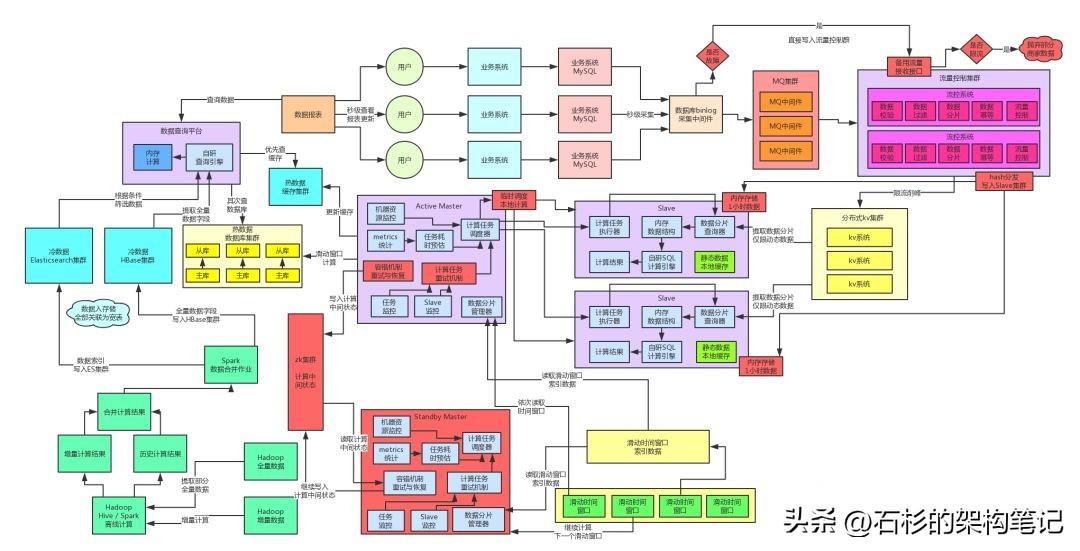
四、實時計算鏈路高可用保障方案
計算任務重分配 + 主備切換機制
下一塊就是實時計算鏈路的高可用保障方案了,其實這個之前給大家說過了,實時計算鏈路是一個分布式的架構,所以要么是Slave節點宕機,要么是Master節點宕機。
其實這個倒沒什么,因為Slave節點宕機,Master節點感知到了,會重新分配計算任務給其他的計算節點;如果Master節點宕機,就會基于Active-Standby的高可用架構,自動主備切換。
咱們直接把架構圖里的實時計算鏈路中的高可用環節標成紅色就可以了。
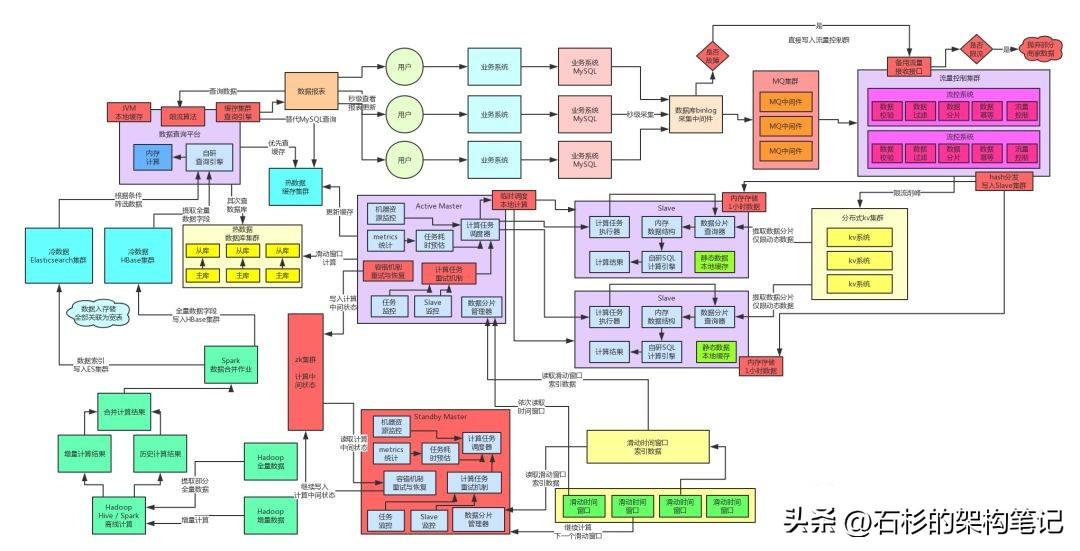
五、熱數據高可用保障方案
自研緩存集群查詢引擎 + JVM本地緩存 + 限流機制
接著咱們來看左側的數據查詢那塊,熱數據也就是提供實時計算鏈路寫入當日數據的計算結果的,用的是MySQL集群來承載主體數據,然后前面掛載一個緩存集群。
?如果出現故障,只有兩種情況:一種是MySQL集群故障,一種是緩存集群故障。
咱們分開說,如果是MySQL集群故障,我們采取的方案是:實時計算結果直接寫入緩存集群,然后因為沒有MySQL支撐,所以沒法使用SQL來從MySQL中組裝報表數據。?
因此,我們自研了一套基于緩存集群的內存級查詢引擎,支持簡單的查詢語法,可以直接對緩存集群中的數據實現條件過濾、分組聚合、排序等基本查詢語義,然后直接對緩存中的數據查詢分析過后返回。
但是這樣唯一的不好,就是緩存集群承載的數據量遠遠沒有MySQL集群大,所以會導致部分用戶看不到數據,部分用戶可以看到數據。不過這個既然是降級 ,那肯定是要損失掉部分用戶體驗的。
?如果是緩存集群故障,我們會有一個查詢平臺里的本地緩存,使用ehcache等框架就可以實現,從mysql中查出來的數據在查詢平臺的jvm本地緩存里cache一下,也可以用作一定的緩存支撐高并發的效果。而且查詢平臺實現限流機制,如果查詢流量超過自身承載范圍,就限流,直接對查詢返回異常響應。
六、冷數據高可用保障方案
收集查詢日志 + 離線日志分析 + 緩存高頻查詢
其實大家看上面的圖就知道,冷數據架構本身就比比較復雜,涉及到ES、HBase等東西,如果你要是想做到一點ES、HBase宕機,然后還搞點兒什么降級方案,還是挺難的。
你總不能ES不能用了,臨時走Solr?或者HBase不能用了,臨時走KV集群?都不行。那個實現復雜度太高,不合適。
所以當時我們采取的方法就是,對最近一段時間用戶發起的離線查詢的請求日志進行收集,然后對請求日志在每天凌晨進行分析,分析出來那種每個用戶會經常、多次、高頻發起的冷數據查詢請求,然后對這個特定的查詢(比如特殊的一組條件,時間范圍,維度組合)對應的結果,進行緩存。
這樣就直接把各個用戶高頻發起的冷數據查詢請求的結果每天動態分析,動態放入緩存集群中。比如有的用戶每天都會看一下上周一周的數據分析結果,或者上個月一個月的數據分析結果,那么就可以把這些結果提前緩存起來。
一旦ES、HBase等集群故障,直接對外冷數據查詢,僅僅提供這些提前緩存好的高頻查詢即可,非高頻無緩存的查詢結果,就是看不到了。
七、最終總結
上述系統到目前為止,已經演進到非常不錯的狀態了,因為這套架構已經解決了百億流量高并發寫入,海量數據存儲,高性能計算,高并發查詢,高可用保障,等一系列的技術挑戰。線上生產系統運行非常穩定,足以應對各種生產級的問題。
其實再往后這套系統架構還可以繼續演進,因為大型系統的架構演進,可以持續N多年,比如我們后面還有分布式系統全鏈路數據一致性保障、高穩定性工程質量保障,等等一系列的事情,不過文章就不再繼續寫下去了,因為文章承載內容量太少,很難寫清楚所有的東西。
其實有不少同學跟我反饋說,感覺看不懂這個架構演進系列的文章,其實很正常,因為文章承載內容較少,這里有大量的細節性的技術方案和落地的實施,都沒法寫出來,只能寫一下大型系統架構不斷演進,解決各種線上技術挑戰的一個過程。
我覺得對于一些年輕的同學,主要還是了解一下系統架構演進的過程,對于一些年長已經做架構設計的兄弟,應該可以啟發一些思路。