微服務(wù)架構(gòu)的數(shù)據(jù)設(shè)計(jì)模式

最近參與公司項(xiàng)目研發(fā),在其中發(fā)現(xiàn)對(duì)于數(shù)據(jù)的管理存在一些小問題,根據(jù)以往經(jīng)驗(yàn),在這里記錄下微服務(wù)數(shù)據(jù)設(shè)計(jì)模式。
微服務(wù)架構(gòu)中的服務(wù)是松耦合的,可以獨(dú)立開發(fā)、部署和擴(kuò)展。每個(gè)微服務(wù)都需要不同類型的數(shù)據(jù)和存儲(chǔ)方式,也因?yàn)檫@樣每個(gè)微服務(wù)都有自己的數(shù)據(jù)庫。
一、每個(gè)服務(wù)的數(shù)據(jù)庫
每個(gè)微服務(wù)都有自己的數(shù)據(jù)庫,可以自由選擇如何管理數(shù)據(jù)。
1、每個(gè)服務(wù)都有一個(gè)數(shù)據(jù)庫的好處
- 松耦合,各自服務(wù)可以更加專注自己的專業(yè)領(lǐng)域
- 自由選擇數(shù)據(jù)庫類型,如 MySQL 等 RDBMS、Cassandra 等寬列數(shù)據(jù)庫、MongoDB 等文檔數(shù)據(jù)庫、Redis 等鍵值存儲(chǔ)和 Neo4J 等圖形數(shù)據(jù)庫。
是否需要為每個(gè)服務(wù)使用不同的數(shù)據(jù)庫服務(wù)器?這不是一個(gè)硬性要求。讓我們看看我們能做些什么。
2、如果您使用的是 RDMS,那么就包括以下特性:
- 專用表—每個(gè)服務(wù)擁有一組表,只能由該服務(wù)訪問。
- 專用數(shù)據(jù)庫架構(gòu)—每個(gè)服務(wù)都有一個(gè)私有的數(shù)據(jù)庫架構(gòu)。
- 專用數(shù)據(jù)庫服務(wù)器—每個(gè)服務(wù)都有自己的數(shù)據(jù)庫服務(wù)器。
3、每個(gè)服務(wù)都有一個(gè)數(shù)據(jù)庫的挑戰(zhàn)
需要連接多個(gè)數(shù)據(jù)庫的查詢?—以下數(shù)據(jù)模式可以克服這一挑戰(zhàn)。
- 事件溯源
- API 組成
- 命令查詢職責(zé)分離 (CQRS)
跨多個(gè)數(shù)據(jù)庫事務(wù)?—為了解決這個(gè)問題,我們可以使用Saga 模式。
二、事件溯源
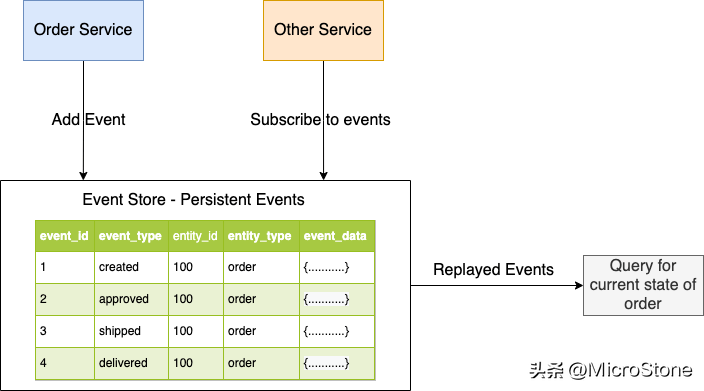
通過事件溯源,業(yè)務(wù)實(shí)體的狀態(tài)由一系列狀態(tài)變化的事件跟蹤。每當(dāng)業(yè)務(wù)實(shí)體的狀態(tài)發(fā)生變化時(shí),都會(huì)將新事件添加到事件列表中。由于保存事件是一個(gè)單一的操作,它本質(zhì)上是原子的。通過重放事件,應(yīng)用程序重建實(shí)體的當(dāng)前狀態(tài)。
應(yīng)用程序?qū)⑹录4嬖谑录鎯?chǔ)中,事件存儲(chǔ)是事件數(shù)據(jù)庫。可以使用其 API 從存儲(chǔ)中添加和檢索事件。事件存儲(chǔ)也充當(dāng)消息代理。服務(wù)可以通過其 API 訂閱事件。當(dāng)服務(wù)在事件存儲(chǔ)中保存一個(gè)事件時(shí),它會(huì)發(fā)送給所有感興趣的訂閱者。當(dāng)實(shí)體有大量事件時(shí),應(yīng)用程序可以定期保存實(shí)體當(dāng)前狀態(tài)的快照以優(yōu)化加載。應(yīng)用程序查找最近的快照以及自該快照以來發(fā)生的事件以重建當(dāng)前狀態(tài)。這減少了要重播的事件的數(shù)量。
1、事件溯源的好處
- 使用它解決了事件驅(qū)動(dòng)架構(gòu)的關(guān)鍵挑戰(zhàn)之一,并使得在狀態(tài)變化時(shí)可靠地發(fā)布事件。
- 避免了對(duì)象關(guān)系阻抗不匹配問題,持久化事件而不是域?qū)ο蟆?/li>
- 對(duì)實(shí)體提供 100% 可靠的審計(jì)日志。
- 允許執(zhí)行確定實(shí)體在任何時(shí)間點(diǎn)的狀態(tài)的時(shí)間查詢。
- 基于事件溯源的業(yè)務(wù)邏輯涉及交換事件的松散耦合實(shí)體。使從單體應(yīng)用程序遷移到微服務(wù)架構(gòu)變得容易得多。
2、事件溯源的缺點(diǎn)
- 有一定學(xué)習(xí)成本,目前還是一種不太成熟的技術(shù)。
- 查詢事件存儲(chǔ)很困難,需要一個(gè)典型的查詢來重建實(shí)體狀態(tài)。可能會(huì)導(dǎo)致低效和復(fù)雜的查詢。因此,應(yīng)用程序必須使用命令查詢職責(zé)分離 (CQRS) 來實(shí)現(xiàn)查詢。反過來,這意味著應(yīng)用程序必須處理最終一致的數(shù)據(jù)。
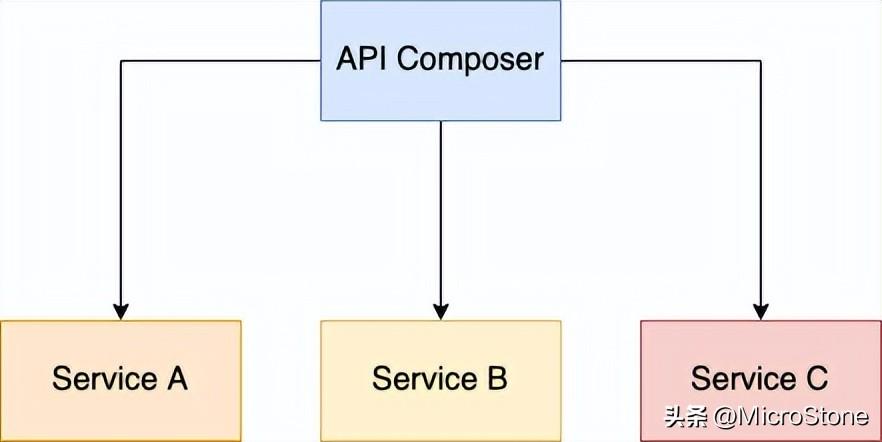
三、API 組成
您可以使用 API 組合模式實(shí)現(xiàn)從多個(gè)服務(wù)中檢索數(shù)據(jù)的查詢操作。在這個(gè)模式中,通過調(diào)用擁有數(shù)據(jù)的服務(wù)然后組合結(jié)果來實(shí)現(xiàn)查詢操作。
1、API 組合的好處
在微服務(wù)架構(gòu)中查詢數(shù)據(jù)的一種便捷方式。
2、API組合的缺點(diǎn)
有時(shí),查詢會(huì)導(dǎo)致大型數(shù)據(jù)集的低效內(nèi)存連接。
四、命令查詢職責(zé)分離 (CQRS)
RDBMS 通常用作記錄事務(wù)系統(tǒng)和文本搜索數(shù)據(jù)庫,例如用于文本搜索查詢的 Elasticsearch 或 Solr。一些應(yīng)用程序通過同時(shí)寫入兩者來保持?jǐn)?shù)據(jù)庫同步。其他人定期將數(shù)據(jù)從 RDBMS 復(fù)制到文本搜索引擎。基于此架構(gòu)構(gòu)建的應(yīng)用程序利用了多個(gè)數(shù)據(jù)庫的優(yōu)勢、RDBMS 的事務(wù)屬性以及文本數(shù)據(jù)庫的查詢能力。CQRS 概括了這種架構(gòu)。
微服務(wù)架構(gòu)在實(shí)現(xiàn)查詢時(shí)面臨三個(gè)常見挑戰(zhàn)。
- 使用 API 組合模式檢索分散在多個(gè)服務(wù)中的數(shù)據(jù),從而導(dǎo)致成本高昂且效率低下的內(nèi)存連接。
- 數(shù)據(jù)以不能有效支持擁有數(shù)據(jù)的服務(wù)所需查詢的格式或數(shù)據(jù)庫中存儲(chǔ)。
- 分離關(guān)注點(diǎn)意味著擁有數(shù)據(jù)的服務(wù)不應(yīng)該負(fù)責(zé)實(shí)現(xiàn)查詢操作。
這三個(gè)問題都可以通過使用 CQRS 模式來解決。
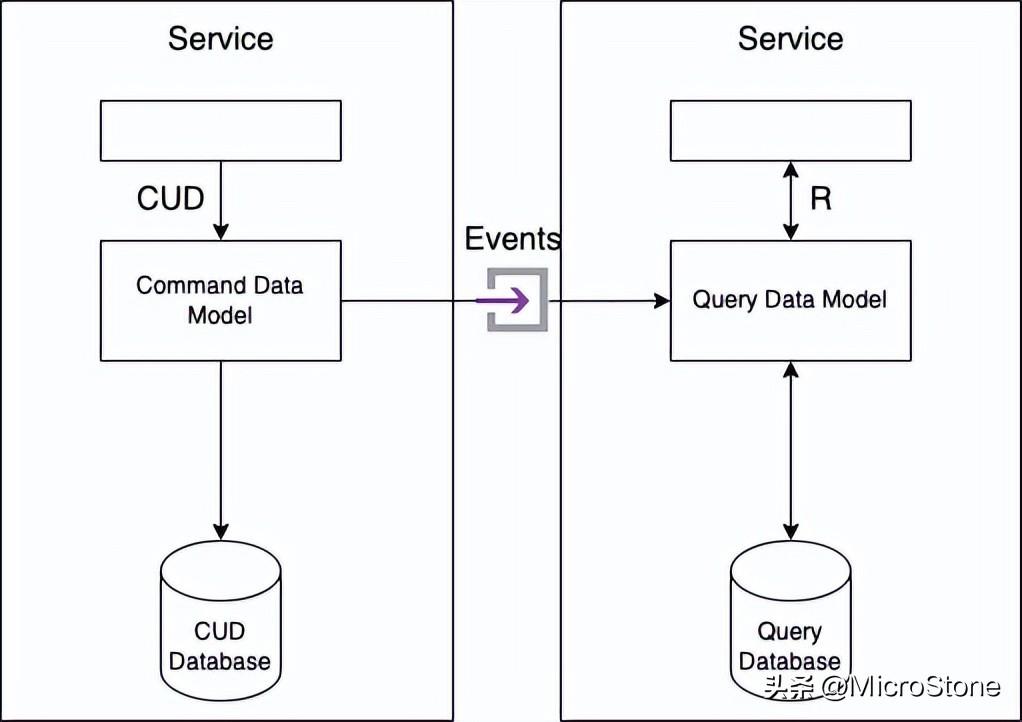
CQRS 的主要目標(biāo)是分離或分離關(guān)注點(diǎn)。因此,持久數(shù)據(jù)模型分為兩部分:命令端和查詢端。
創(chuàng)建、更新和刪除操作由命令端模塊和數(shù)據(jù)模型實(shí)現(xiàn)。查詢由查詢端模塊和數(shù)據(jù)模型實(shí)現(xiàn)。通過訂閱命令行發(fā)布的事件,查詢端保持其數(shù)據(jù)模型與命令端同步
1、CQRS 的好處
- 實(shí)現(xiàn)高效查詢實(shí)現(xiàn)—如果您使用 API 組合模式來實(shí)現(xiàn)查詢,您可能會(huì)遇到大型數(shù)據(jù)集的高成本、低效的內(nèi)存連接。對(duì)于這些查詢,使用預(yù)先來自連接兩個(gè)或更多服務(wù)數(shù)據(jù)的CQRS 視圖更有效。
- 能夠有效實(shí)現(xiàn)多種查詢—通常很難使用單一持久數(shù)據(jù)模型來支持所有查詢。在CQRS 中,定義一個(gè)或多個(gè)視圖有效地實(shí)現(xiàn)特定查詢,消除了單個(gè)數(shù)據(jù)存儲(chǔ)的限制。
- 實(shí)現(xiàn)基于事件溯源的應(yīng)用程序中查詢—CQRS 還克服了事件溯源的一個(gè)重要限制。事件存儲(chǔ)僅支持基于主鍵的查詢。CQRS 模式通過定義一個(gè)或多個(gè)聚合視圖來解決此限制,這些視圖通過訂閱由事件源聚合發(fā)布的事件流來保持最新。
- 關(guān)注點(diǎn)分離改進(jìn)—域模型和持久數(shù)據(jù)模型不支持命令和查詢。CQRS 將服務(wù)的命令和查詢端分離為單獨(dú)的代碼模塊和數(shù)據(jù)庫模式。
2、CQRS 的缺點(diǎn)
- 更復(fù)雜的架構(gòu)—為了更新和查詢視圖,開發(fā)者需要編寫查詢端服務(wù)。應(yīng)用程序可能使用不同類型的數(shù)據(jù)庫,這增加了開發(fā)人員和 DevOps 的復(fù)雜性。
- 處理復(fù)制延遲—在從命令端發(fā)布事件到由查詢端處理事件以及更新視圖之間存在延遲。
五、Saga模式
使用 sagas,您可以在不使用分布式事務(wù)的情況下保持微服務(wù)架構(gòu)中數(shù)據(jù)的一致性。您為跨多個(gè)服務(wù)更新數(shù)據(jù)的每個(gè)命令定義一個(gè) saga。saga 是一系列本地事務(wù)。本地事務(wù)使用ACID事務(wù)框架更新單個(gè)服務(wù)中的數(shù)據(jù)。
Sagas 利用補(bǔ)償事務(wù)來回滾更改。假設(shè)saga的第n個(gè)交易失敗。必須撤消前 (n-1) 個(gè)事務(wù)。結(jié)果,總共 (n-1) 個(gè)補(bǔ)償事務(wù)將被啟動(dòng)以以相反的順序回滾更改。
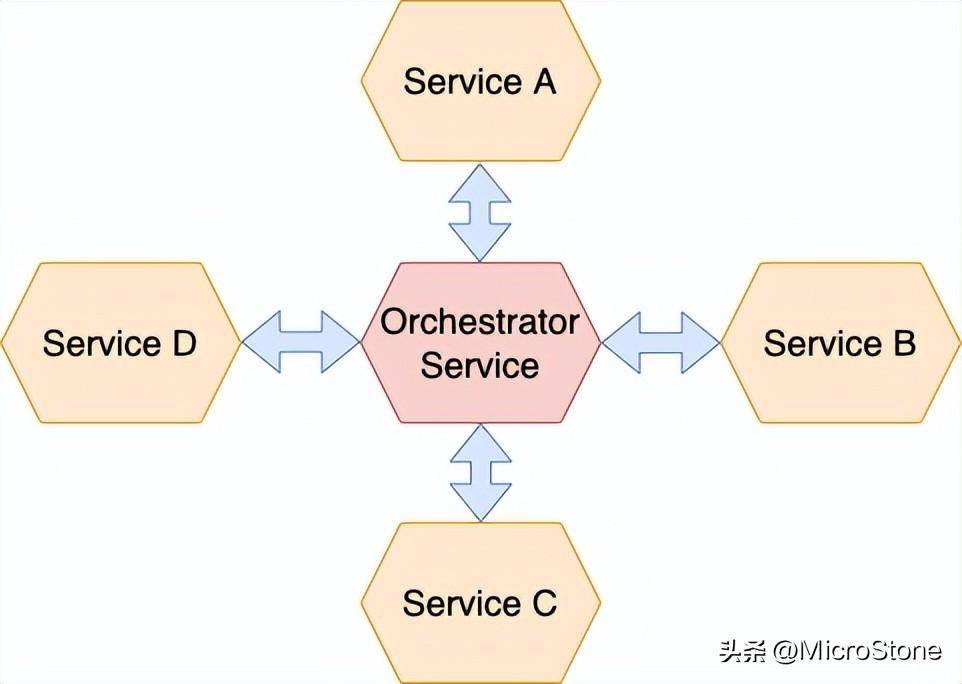
1、Saga協(xié)調(diào)
為了實(shí)現(xiàn)一個(gè) saga,它需要邏輯來協(xié)調(diào)其步驟。一旦系統(tǒng)命令啟動(dòng)了一個(gè) saga,協(xié)調(diào)邏輯必須選擇并指示第一個(gè) saga 執(zhí)行本地事務(wù)。一旦該事務(wù)完成,編排協(xié)調(diào)就會(huì)選擇并調(diào)用下一個(gè) saga 參與者。這個(gè)過程一直持續(xù)到傳奇完成。如果本地事務(wù)失敗,saga 必須以相反的順序執(zhí)行補(bǔ)償事務(wù)。
2、有幾種方法可以構(gòu)建 saga 的協(xié)調(diào)邏輯:
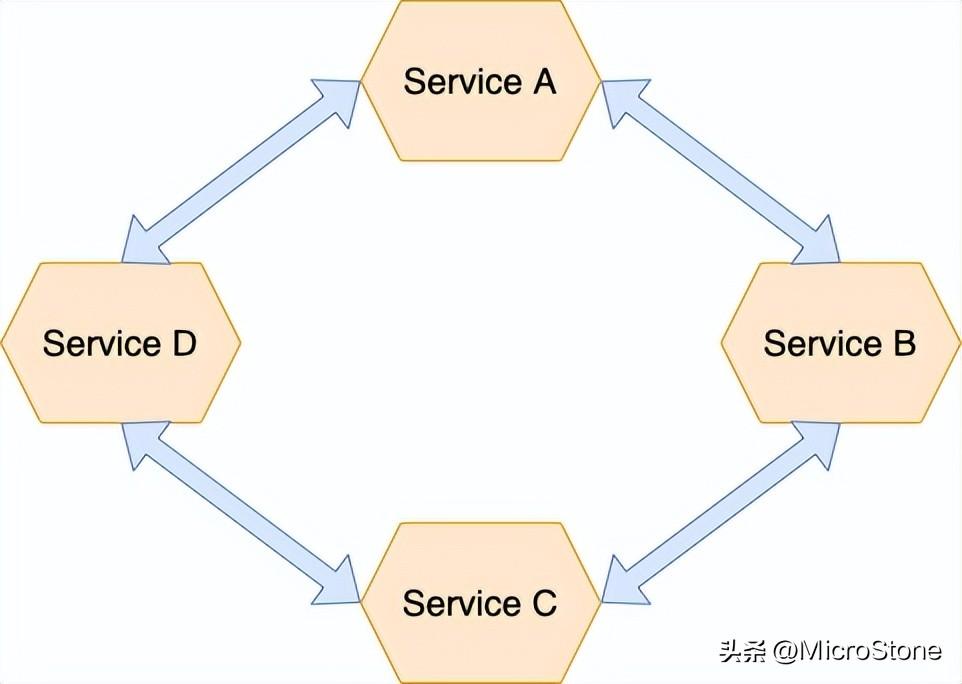
編排?:在saga的參與者之間分配決策和排序。他們主要通過交換事件進(jìn)行通信。
(1)基于編排的saga優(yōu)勢
- 簡單性—當(dāng)創(chuàng)建、更新或刪除業(yè)務(wù)對(duì)象時(shí),服務(wù)會(huì)發(fā)布事件。
- 簡單依賴關(guān)系—不引入循環(huán)依賴關(guān)系。
- 松耦合—服務(wù)實(shí)現(xiàn)由編排器調(diào)用的 API,因此它不需要知道 saga 參與者發(fā)布的事件。
- 簡化業(yè)務(wù)邏輯—在 saga 編排器中,saga 協(xié)調(diào)邏輯是本地化的。領(lǐng)域?qū)ο蟛恢浪鼈兯婕暗?sagas。
(2)基于編排的缺點(diǎn)
- 更難理解—編排將 saga 的實(shí)現(xiàn)分布在服務(wù)之間,每個(gè)服務(wù)都是獨(dú)立的這就需要每個(gè)管理對(duì)每個(gè)服務(wù)都需要了解。
- 服務(wù)之間的循環(huán)依賴—saga 參與者訂閱彼此的事件,這通常會(huì)產(chǎn)生循環(huán)依賴。
- 緊密耦合的風(fēng)險(xiǎn)—saga的參與者必須訂閱所有影響他們的事件。
編排?—一個(gè) saga 的協(xié)調(diào)邏輯應(yīng)該集中在一個(gè) saga 編排器類中。在 saga 期間,編排器向參與者發(fā)送命令消息,告訴他們應(yīng)該執(zhí)行哪些操作。