微服務架構(gòu)的可觀察性設(shè)計模式

可觀察性是監(jiān)控的超集。除了提供對隱式故障模式的詳細洞察之外,它還提供了系統(tǒng)健康狀況的高級概述。此外,可觀察系統(tǒng)還提供了有關(guān)其內(nèi)部運作的儲備,能夠發(fā)現(xiàn)更深層次的系統(tǒng)性問題。
一旦服務部署到生產(chǎn)環(huán)境中,我們想知道它每秒請求數(shù)、資源利用率等方面的執(zhí)行情況。此外,如果出現(xiàn)問題,希望能得到即時警報,例如服務實例失敗或者磁盤空間不足,最好是在影響用戶體驗之前得到警報。如果出現(xiàn)問題,我們需要能夠排除故障并進行 RCA(根本原因分析)。
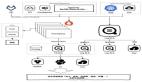
作為服務開發(fā)人員,我們應該實現(xiàn)幾種模式,讓服務管理和故障排除更容易。以下五種模式可以幫助我們設(shè)計可觀察的服務:
- 健康檢查API: 提供一個返回服務健康狀況的端點。
- 日志聚合:您可以記錄服務活動并將日志存儲在集中式日志服務器中,該服務器提供警報和搜索功能。
- 分布式跟蹤:使用唯一ID 識別每個外部請求,并在請求服務之間流動時對其進行跟蹤。
- 異常跟蹤:應將異常報告給異常跟蹤服務,該服務對異常進行重復數(shù)據(jù)刪除、提醒開發(fā)人員并跟蹤它們是如何解決的。
- 應用程序指標:諸如計數(shù)器和儀表之類的指標由服務維護并暴露給指標服務器。
- 審計日志:跟蹤用戶操作
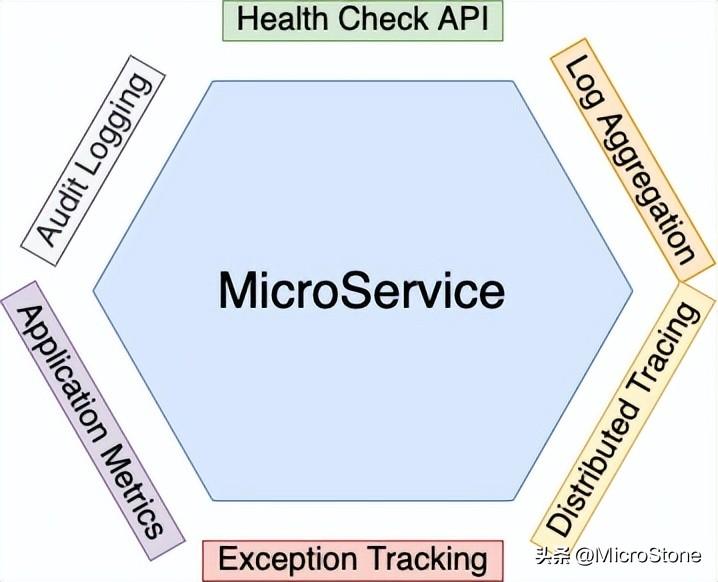
一、健康檢查 API 模式
有時,服務可能正在運行但無法處理請求。新啟動的服務實例可能仍在初始化并進行一些健全性檢查,然后才能處理請求。部署基礎(chǔ)架構(gòu)在準備好處理 HTTP 請求之前,將其路由到服務實例是沒有意義的。
也可能出現(xiàn)服務實例沒有終止就失敗的情況,例如所有的DB連接都用完了,無法訪問數(shù)據(jù)庫。部署基礎(chǔ)設(shè)施不應將請求路由到失敗但仍在運行的服務實例;如果服務實例無法恢復,則必須終止它,并創(chuàng)建一個新實例。服務實例必須能夠告訴部署基礎(chǔ)設(shè)施它是否能夠處理請求。您可以使用實現(xiàn)健康端點的Spring Boot Actuator來為您的服務實現(xiàn)健康檢查端點。
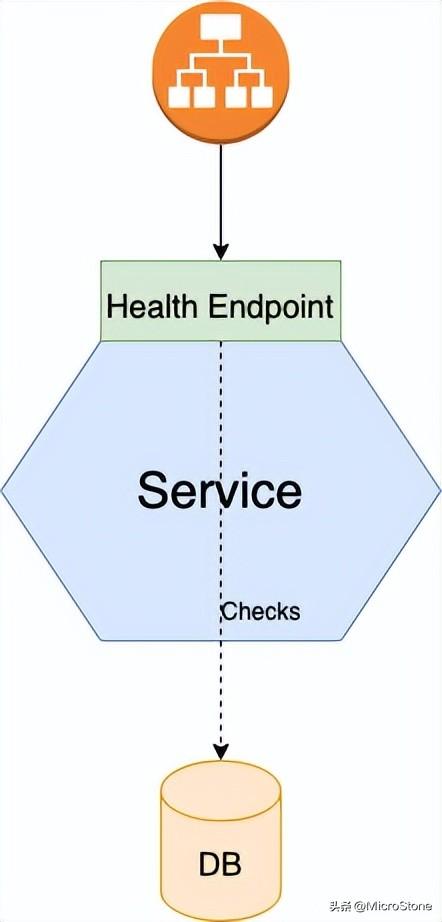
二、日志聚合模式
日志聚合模式可以進行故障排除。如果您想確定應用程序出了什么問題,日志文件是一個很好的起點。登錄微服務架構(gòu)可能具有挑戰(zhàn)性,因為日志內(nèi)容分散在不同服務的日志文件中。
日志聚合是解決方案。日志聚合服務將所有服務實例的日志發(fā)送到集中式日志服務器。當日志被日志服務器存儲時,它們可以被查看、搜索和分析。還可以設(shè)置在日志中出現(xiàn)某些消息時觸發(fā)警報。
日志基礎(chǔ)設(shè)施負責聚合日志、存儲日志,并使用它進行搜索。許多流行的工具都提供了日志聚合,例如Splunk、Fluentd、ELK stack、Graylog等。
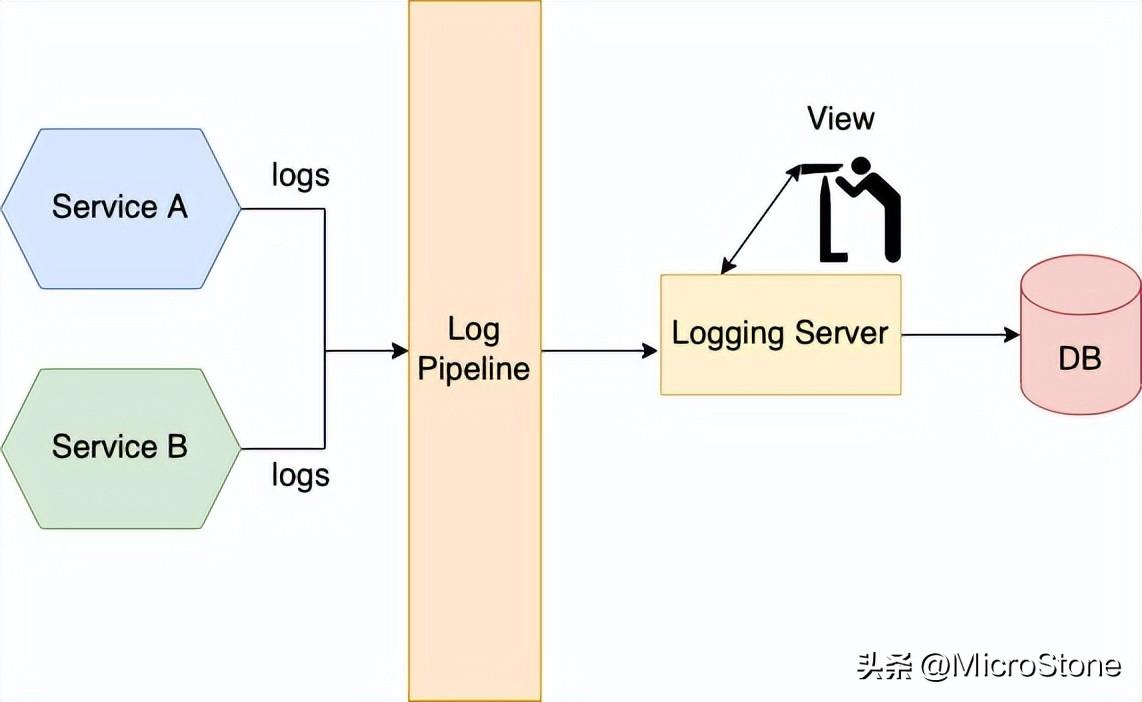
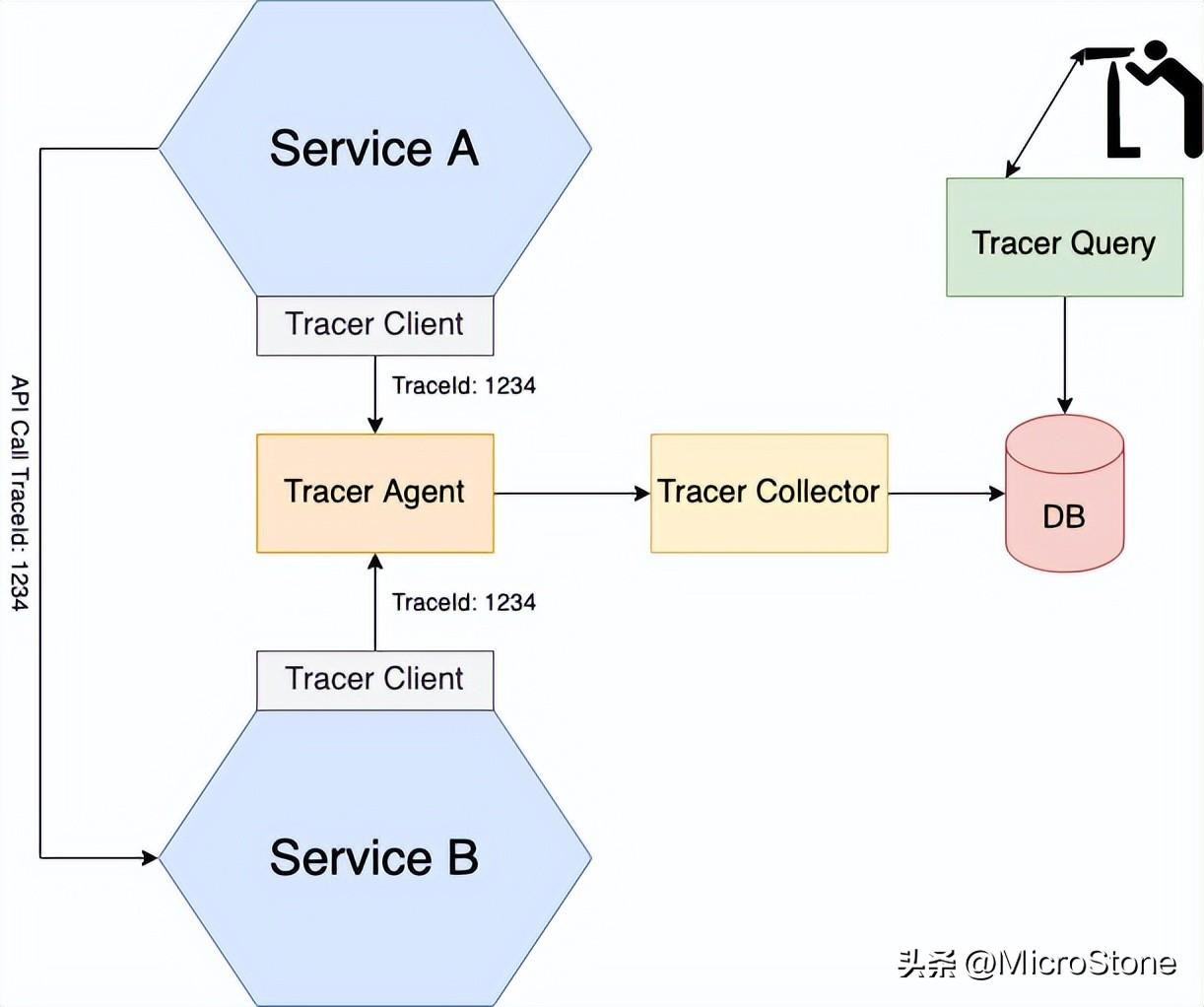
三、分布式跟蹤模式
假設(shè)您正在對 API 響應緩慢進行故障排除,這個 API 可能涉及多個服務。使用分布式跟蹤可以深入了解應用程序正在做什么。分布式跟蹤器類似于單體應用程序中的性能分析器。記錄有關(guān)處理請求時進行的服務調(diào)用的信息。然后,您可以看到服務在處理外部請求期間如何交互,以及在每個服務上花費了多少時間。
每個外部請求都被分配一個唯一的 ID,并在它從一個服務流向另一個提供可視化和分析的集中式服務器上進行跟蹤。分布式追蹤服務器包括Zipkin、Jaeger、OpenTracing、OpenCensus、New Relic等。
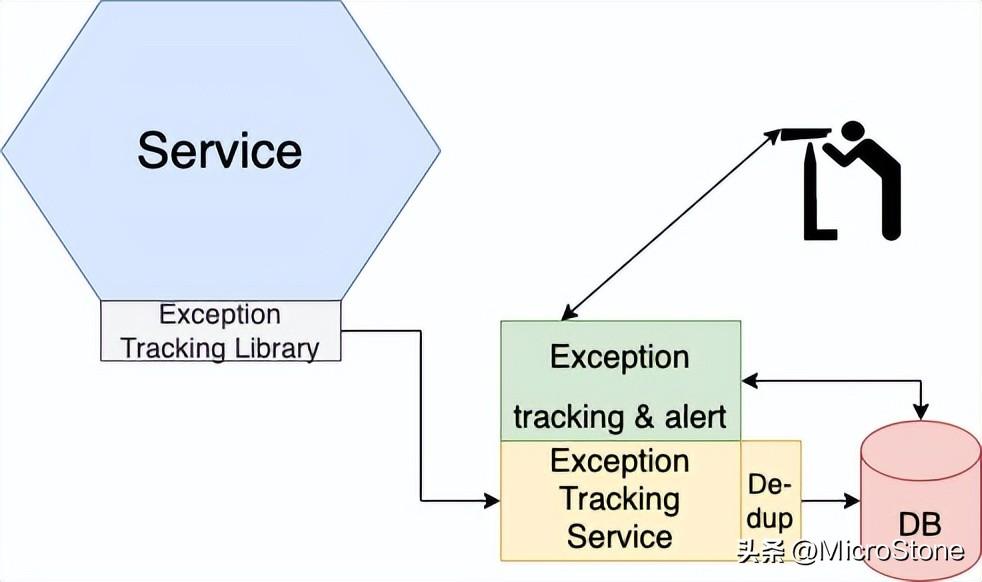
四、異常跟蹤模式
服務記錄異常,幫忙確定原因很重要。異常表示存在問題或程序錯誤。日志用于查看異常,甚至可以配置日志服務器,方便在異常時提醒運維人員。然而有幾個缺點需要注意:
- 日志文件由單行日志條目組成,而異常有多行。
- 在日志文件中,沒有跟蹤異常解決的機制。需要手動將異常復制/粘貼到問題跟蹤器中。
- 目前沒有辦法自動將重復的異常視為一個異常。
異常跟蹤服務是一種非常好的異常跟蹤方法。服務向集中式服務報告異常,該服務對異常進行重復數(shù)據(jù)刪除、生成警報和異常管理。可以使用Honeybadger和Sentry等實現(xiàn)異常跟蹤服務。
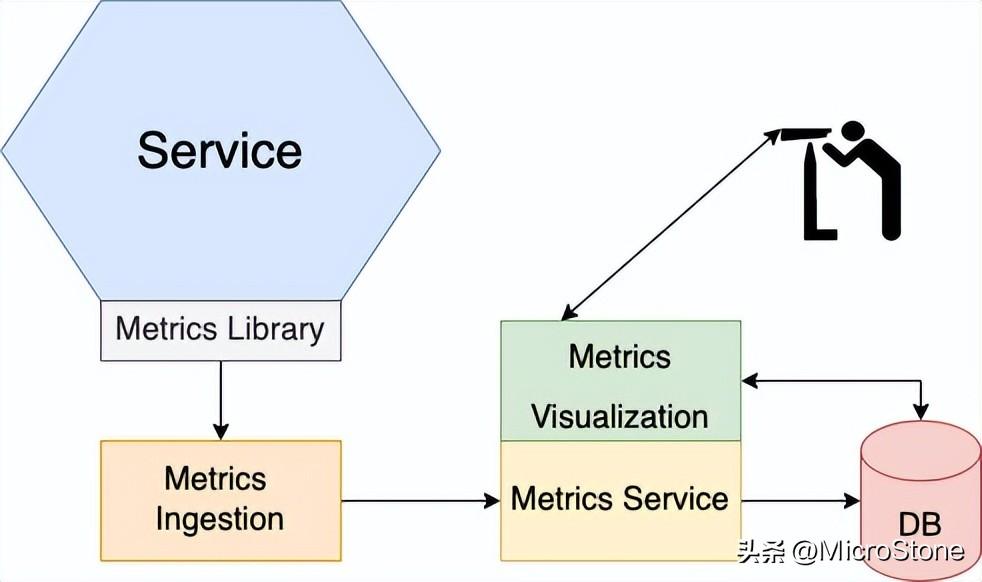
五、應用度量模式
監(jiān)控和警報是生產(chǎn)環(huán)境的關(guān)鍵組件。監(jiān)控系統(tǒng)從其技術(shù)堆棧的所有部分收集提供有關(guān)應用程序運行狀況的關(guān)鍵信息的指標。這些指標的范圍從基礎(chǔ)架構(gòu)級別的指標(例如 CPU、內(nèi)存和磁盤利用率)到應用程序級別的指標(例如服務請求延遲和處理的請求數(shù)量)。
度量標準是服務開發(fā)人員的責任,有兩種方式。首先必須檢測服務,收集有關(guān)行為指標。其次,必須將這些服務指標以及來自 JVM 和應用程序框架的指標公開給指標服務器。應用程序指標服務可以像 AWS CloudWatch 服務或Prometheus服務器一樣輪詢端點以檢索指標。Grafana是一種數(shù)據(jù)可視化工具,可用于在 Prometheus 中查看指標。
六、審計日志模式
每個用戶的操作都被審計日志記錄下來。通常,審核日志用于提供客戶支持、確保合規(guī)性和檢測可疑活動。審計日志條目記錄用戶的身份、他們執(zhí)行的操作以及涉及的業(yè)務對象。審計日志通常存儲在數(shù)據(jù)庫表中。
審計日志可以通過幾種不同的方式實現(xiàn):
- 將審計日志代碼添加到業(yè)務邏輯:每個服務方法都可以創(chuàng)建一個審計日志條目并將其保存到數(shù)據(jù)庫中。
- 面向切面的編程 (AOP):可以使用 AOP 框架(如 Spring AOP)定義攔截每個服務方法調(diào)用并保留審計日志條目的建議。
- 利用事件溯源:默認情況下,事件溯源提供了用于創(chuàng)建和更新操作的審計日志。
根據(jù)定義,可觀察性模式不是關(guān)于日志、指標或跟蹤,而是關(guān)于在調(diào)試期間由數(shù)據(jù)驅(qū)動并使用反饋來迭代和改進產(chǎn)品。