這些常見的反爬蟲手段,你能攻破多少?

在抓取對方網(wǎng)站、APP 應用的相關(guān)數(shù)據(jù)時,經(jīng)常會遇到一系列的方法阻止爬蟲。

網(wǎng)站APP們這么做的原因,一是為了保證服務(wù)的質(zhì)量,降低服務(wù)器負載,二是為了保護數(shù)據(jù)不被獲取。爬蟲與反爬蟲的斗爭經(jīng)久不衰,
這里給大家總結(jié)出了我們在爬取數(shù)據(jù)時常見的反爬蟲手段。
1. User-Agent
網(wǎng)絡(luò)請求中,User-Agent 是表明身份的一種方式,網(wǎng)站可以通過User-Agent來判斷用戶是使用什么瀏覽器訪問。不同瀏覽器的User-Agent是不一樣的
例如,我們在windows上面的Chrome瀏覽器,它的User-Agent是:
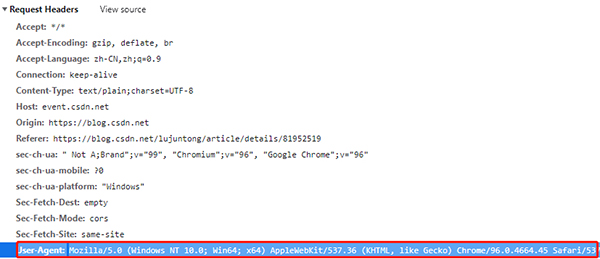
但是如果我們使用Python的Requests直接訪問網(wǎng)站,除了網(wǎng)址不提供其他的信息,那么網(wǎng)站收到的User-Agent是空。
這個時候網(wǎng)站就知道我們不是使用瀏覽器訪問的,于是它就可以拒絕我們的訪問。
from fake_useragent import UserAgent
for i in range(1,11):
ua = UserAgent().random
print(f'第{i}次的ua是', ua)
'''
第1次的ua是 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36
第2次的ua是 Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130401 Firefox/21.0
第3次的ua是 Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; es-es) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27
第4次的ua是 Mozilla/5.0 (X11; CrOS i686 4319.74.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36
第5次的ua是 Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_6; fr-ch) AppleWebKit/533.19.4 (KHTML, like Gecko) Version/5.0.3 Safari/533.19.4
第6次的ua是 Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36
第7次的ua是 Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36
第8次的ua是 Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0
第9次的ua是 Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Zune 3.0)
第10次的ua是 Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36
'''
2. Referer
HTTP Referer是header的一部分,當瀏覽器向web服務(wù)器發(fā)送請求的時候,一般會帶上Referer,表明這個網(wǎng)頁是從哪里跳過來的,是網(wǎng)頁防盜鏈的一種方式
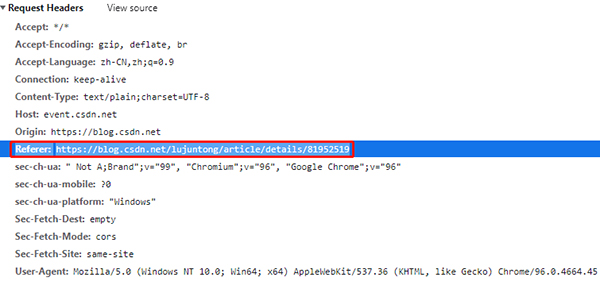
有時也被用于反爬蟲。如果網(wǎng)站會檢查 Referer,請保證你的 Referer 始終是正確的(跳轉(zhuǎn)到此網(wǎng)頁之前的網(wǎng)頁 URL)。
3. Ajax
這個應該不算反爬?當網(wǎng)站使用 ajax 異步獲取數(shù)據(jù)時,我們是無法直接從網(wǎng)頁源代碼中獲取想要的數(shù)據(jù)的,這個時候要借助 Network 工具欄,分析 API 請求,然后使用 Python 模擬調(diào)用 API,直接從 API 中獲取數(shù)據(jù)。(多數(shù)都是 POST 類型的請求,也有小部分 GET 的)
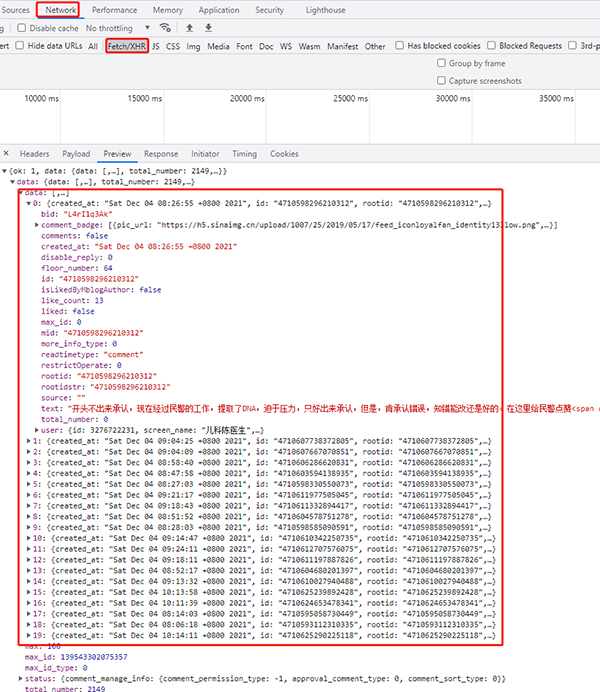
當然,也可以使用 Selenium 等自動化測試工具直接渲染網(wǎng)頁,再從渲染后的網(wǎng)頁源碼中解析數(shù)據(jù)。
4. Cookie
在網(wǎng)站中,http的請求通常是無狀態(tài)的(第一個和服務(wù)器連接并且登錄之后,此時服務(wù)器知道是哪個用戶,但是當?shù)诙握埱蠓?wù)器時,服務(wù)器依然不知道當前請求的是哪個用戶),cookie就是為了解決這個問題。
第一次登錄服務(wù)器后,服務(wù)器會返回與剛剛用戶相關(guān)的數(shù)據(jù)(也就是cookie)給瀏覽器,瀏覽器將cookie保存在本地,當這個用戶第二次請求服務(wù)器時,就會把上次存儲的cookie自動攜帶給服務(wù)器,服務(wù)器通過這個cookie就知道當前是哪個用戶。
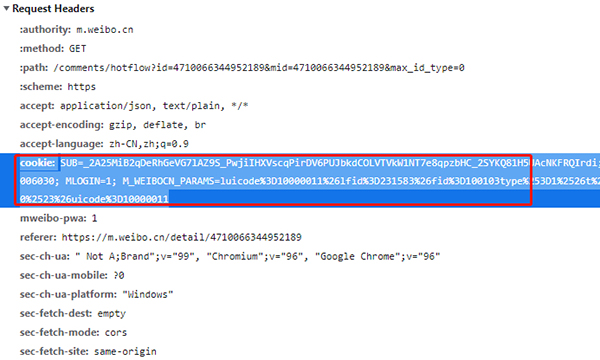
在一些爬蟲中,我們在進入一個頁面之前需要先登錄,比如人人網(wǎng),我們想要在人人網(wǎng)中瀏覽主頁,就要先注冊登錄,然后才能瀏覽,那么在爬蟲時,保持登錄狀態(tài)就需要在請求頭中加入cookie。
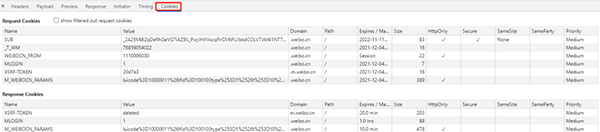
cookies是指網(wǎng)站為了辨別用戶身份,進行會話跟蹤而儲存在本地終端的數(shù)據(jù),cookies一般再電腦中的文件里以文本形式儲存。cookies其實是有鍵值對組成的,如下圖所示:
5. 驗證碼
驗證碼又分很多種,我們說一下比較常見的三種:字母驗證碼、拼圖驗證碼、點選式驗證碼。
字母驗證碼,就是給你一張有若干字母或數(shù)字的圖片,讓你識別出其中內(nèi)容,并在文本框中輸入。比如這個:
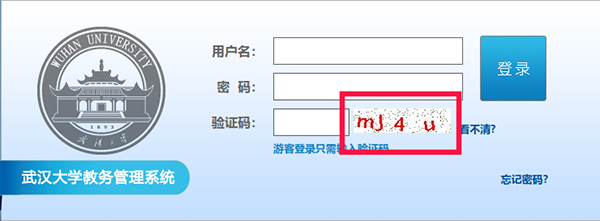
這是最簡單的驗證碼,一般編寫深度學習模型訓練,或直接使用打碼平臺即可解決。
拼圖驗證碼,給定了一張圖片和一個滑動組件。當你拖動滑動組件時,圖片會出現(xiàn)缺口,拖動滑動組件,補全缺口即可過關(guān)。比類似于這種:
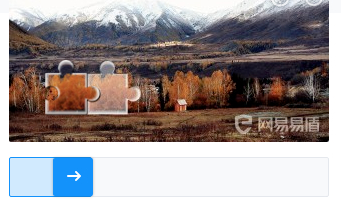
比較常見的做法是,通過圖片之間的對比,計算拼圖缺口的位置,然后使用特定的軌跡拖動滑塊,完成驗證。
你有兩種方法提交驗證,一是使用 Selenium 調(diào)用瀏覽器,二是直接破解 JS,使用 POST 模擬提交。
點選式的驗證碼,會給出一張小圖片(有的是圖片,有的不是,不同驗證碼平臺不一樣),上面順序顯示著幾個漢字。再給出一張大圖片,上面也有這幾個漢字,但漢字的分布是隨機的。要求你按照小圖片中漢字出現(xiàn)的順序,點擊大圖片中的漢字。類似于這種:
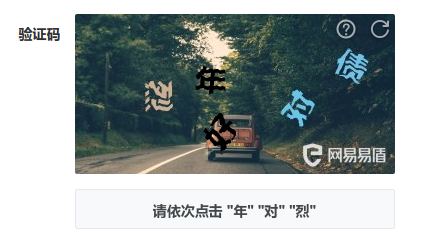
最常見的方法是借助打碼平臺計算相對坐標,然后使用 Selenium 等自動化工具按順序點擊。當然,自己訓練模型也是可行的,但比較麻煩。
對于驗證碼,可以通過OCR來識別圖片,Github上面有很多大神分享的代碼可以用,可以去看看。
簡單的OCR識別驗證碼:
from PIL import Image
import tesserocr
#tesserocr識別圖片的2種方法
img = Image.open("code.jpg")
verify_code1 = tesserocr.image_to_text(img)
#print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")
6. 代理 IP 池
如果你頻繁使用同一個 IP 訪問某個網(wǎng)站,可能會被網(wǎng)站認為是惡意攻擊,進而 ban 掉你的 IP。這個時候,使用代理 IP 池就是一個很好的方案。
在一些網(wǎng)站服務(wù)中,除了對 user-agent 的身份信息進行檢測。
也對客戶端的 ip 地址做了限制。
如果是同一個客戶端訪問此網(wǎng)站服務(wù)器的次數(shù)過多就會將其識別為爬蟲。
因而,限制其客戶端 ip 的訪問。這樣的限制給我們的爬蟲帶來了麻煩,所以使用代理 ip 在爬蟲中是非常有必要的。
這里我給大家提供一下兩個網(wǎng)站供參考。
66代理:http://www.66ip.cn/6.html
快代理:https://www.kuaidaili.com/free/
7. 請求間隔
兩次請求之間,最好設(shè)置一定間隔。理由如下:
請求過于頻繁,遠超出人工頻率,容易被識別出來,請不要給對方服務(wù)器造成太大壓力
且間隔的時間不要定死,在一定范圍內(nèi)波動是個比較合適的選擇。過于機械的間隔時長,也可能會讓網(wǎng)站認為你是爬蟲。
import time
import random
for i in range(1,11):
time = random.random()*5
print(f'第{i}次睡了:', time, 's')
'''
第1次睡了: 0.6327309035891232 s
第2次睡了: 0.037961811128097045 s
第3次睡了: 0.7443093721610153 s
第4次睡了: 0.564336149517787 s
第5次睡了: 0.39922345839757245 s
第6次睡了: 0.13724989845026703 s
第7次睡了: 0.7877693301824763 s
第8次睡了: 0.5641490602064826 s
第9次睡了: 0.05517343036931721 s
第10次睡了: 0.3992618299505627 s
'''
8. 字體反爬
還有一種特殊情況,你在瀏覽器頁面上已經(jīng)看到了你想要的數(shù)據(jù),但是當你查看源碼時,根本找不到相關(guān)數(shù)據(jù)或者數(shù)據(jù)和你看到的不一致。你懷疑這個數(shù)據(jù)是通過接口異步加載的,但你檢查了請求,過程中并沒有異步請求數(shù)據(jù)接口。怎么回事?
你可能遇到了字體反爬。即目標網(wǎng)站通過 CSS 樣式、字體映射等方式,完成了對特定數(shù)據(jù)的隱藏。你無法直接從源碼提取相關(guān)數(shù)據(jù),但卻不會影響網(wǎng)頁的顯示效果。那么,怎么解決呢?
兩種方法,第一種,破解字體的映射關(guān)系,從源碼中提取錯誤的數(shù)據(jù),并通過特定的映射關(guān)系把它翻譯成正確的數(shù)據(jù)。第二種就是偷懶的方法了,使用 Selenium 等自動化測試工具渲染頁面,截取數(shù)據(jù)內(nèi)容圖片,并通過 OCR 程序識別圖像內(nèi)容。
9. 正則表達式
對于頁面解析最強大的當然是正則表達式,這個對于不同網(wǎng)站不同的使用者都不一樣,就不用過多的說明,附兩個比較好的網(wǎng)址:
正則表達式入門:
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
正則表達式在線測試:
http://tool.oschina.net/regex/
其次就是解析庫了,常用的有兩個lxml和BeautifulSoup,對于這兩個的使用介紹兩個比較好的網(wǎng)站:
lxml:http://my.oschina.net/jhao104/blog/639448
BeautifulSoup:http://cuiqingcai.com/1319.html
對于這兩個庫,我的評價是,都是HTML/XML的處理庫,Beautifulsoup純python實現(xiàn),效率低,但是功能實用,
比如能用通過結(jié)果搜索獲得某個HTML節(jié)點的源碼;lxml C語言編碼,高效,支持Xpath。
10. pprint
這個是在pycharm中查看的來看效果吧
print()打印,不知道你感覺如何,我一臉懵逼。
import requests
url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1'
resp = requests.get(url).json()
print(resp)
pprint()打印,這種結(jié)構(gòu)看起來如何呢?
from pprint import pprint
import requests
url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1'
resp = requests.get(url).json()
pprint(resp)

現(xiàn)在除了使用pprint之外,冰淇淋icecream也是很好的選擇