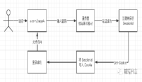
系統回顧深度強化學習預訓練,在線、離線等研究這一篇就夠了
近年來,強化學習 (RL) 在深度學習的帶動下發展迅速,從游戲到機器人領域的各種突破,激發了人們對設計復雜、大規模 RL 算法和系統的興趣。然而,現有 RL 研究普遍讓智能體在面對新的任務時只能從零開始學習,難以利用預先獲取的先驗知識來輔助決策,導致很大的計算開銷。
而在監督學習領域,預訓練范式已經被驗證為有效的獲得可遷移先驗知識的方式,通過在大規模數據集上進行預訓練,網絡模型能夠快速適應不同的下游任務上。相似的思路同樣在 RL 中有所嘗試,尤其是近段時間關于 “通才” 智能體 [1, 2] 的研究,讓人不禁思考是否在 RL 領域也能誕生如 GPT-3 [3] 那樣的通用預訓練模型。
然而,預訓練在 RL 領域的應用面臨著諸多挑戰,例如上下游任務之間的顯著差異、預訓練數據如何高效獲取與利用、先驗知識如何有效遷移等問題都阻礙了預訓練范式在 RL 中的成功應用。同時,過往研究考慮的實驗設定和方法存在很大差異,這令研究者很難在現實場景下設計合適的預訓練模型。
為了梳理預訓練在 RL 領域的發展以及未來可能的發展方向,來自上海交通大學和騰訊的研究者撰文綜述,討論現有 RL 預訓練在不同設定下的細分方法和待解決的問題。

論文地址:https://arxiv.org/pdf/2211.03959.pdf
RL 預訓練簡介
強化學習(RL)為順序決策提供了一個通用的數學形式。通過 RL 算法和深度神經網絡,在不同領域的各種應用上實現了以數據驅動的方式、優化指定獎勵函數學習到的智能體取得了超越人類的表現。然而,雖然 RL 已被證明可以有效地解決指定任務,但樣本效率和泛化能力仍然是阻礙 RL 在現實世界應用中的兩大障礙。在 RL 研究中,一個標準的范式是讓智能體從自己或他人收集的經驗中學習,針對單一任務,通過隨機初始化來優化神經網絡。與之相反,對人類來說,世界先驗知識對決策過程有很大的幫助。如果任務與以前看到的任務有關,人類傾向于復用已經學到的知識來快速適應新的任務,而不需要從頭開始學習。因此,與人類相比, RL 智能體存在數據效率低下問題,而且容易出現過擬合現象。
然而,機器學習其他領域的最新進展積極倡導利用從大規模預訓練中構建的先驗知識。通過對廣泛的數據進行大規模訓練,大型基礎模型 (foundation models) 可以快速適應各種下游任務。這種預訓練 - 微調范式在計算機視覺和自然語言處理等領域已被證明有效。然而,預訓練還沒有對 RL 領域產生重大影響。盡管這種方法很有前景,但設計大規模 RL 預訓練的原則面臨諸多挑戰。1)領域和任務的多樣性;2)有限的數據源;3)快速適應解決下游任務的難度。這些因素源于 RL 的內在特征,需要研究者加以特別考慮。
預訓練對 RL 有很大的潛力,這項研究可以作為對這一方向感興趣的人的起點。本文中,研究者試圖對現有深度強化學習的預訓練工作進行系統的回顧。
近年來,深度強化學習預訓練經歷了幾次突破性進展。首先,基于專家示范的預訓練使用監督學習來預測專家所采取的行動,已經在 AlphaGo 上得到應用。為了追求更少監督的大規模預訓練,無監督 RL 領域發展迅速,它允許智能體在沒有獎勵信號的情況下從與環境的互動中學習。此外,離線強化學習 (offline RL) 發展迅猛,又促使研究人員進一步考慮如何利用無標簽和次優的離線數據進行預訓練。最后,基于多任務和多模態數據的離線訓練方法進一步為通用的預訓練范式鋪平了道路。

在線預訓練
以往 RL 的成功都是在密集和設計良好的獎勵函數下實現的。在諸多領域取得巨大進展的傳統 RL 范式,在擴展到大規模預訓練時面臨兩個關鍵挑戰。首先,RL 智能體很容易過擬合,用復雜的任務獎勵預訓練得到的智能體很難在從未見過的任務上取得很好的性能。此外,設計獎勵函數通常十分昂貴,需要大量專家知識,這在實際中無疑是個很大的挑戰。
無獎勵信號的在線預訓練可能會成為學習通用先驗知識的可用解決方案,并且是無需人工參與的監督信號。在線預訓練旨在在沒有人類監督的情況下,通過與環境的交互來獲得先驗知識。在預訓練階段,智能體被允許與環境進行長時間的交互,但不能獲得外在獎勵。這種解決方案,也被稱為無監督 RL,近年來研究者一直在積極研究。
為了激勵智能體在沒有任何監督信號的情況下從環境中獲取先驗知識,一種成熟的方法是為智能體設計內在獎勵 (intrinsic reward) ,鼓勵智能體通過收集多樣的經驗或掌握可遷移的技能,相應地設計獎勵機制。先前研究已經表明,通過內在獎勵和標準 RL 算法進行在線預訓練,智能體能夠快速適應下游任務。

離線預訓練
盡管在線預訓練在無需人類監督的情況下能夠取得很好的預訓練效果,但對于大規模應用來說,在線預訓練仍然是有限的。畢竟,在線的交互與在大型和多樣化的數據集上進行訓練的需求在一定程度上是互斥的。為了解決這個問題,人們往往希望將數據收集和預訓練環節脫鉤,直接利用從其他智能體或人類收集的歷史數據進行預訓練。
一個可行的解決方案是離線強化學習。離線強化學習的目的是從離線數據中獲得一個獎勵最大化的 RL 策略。其所面臨的一個基本挑戰是分布偏移問題,即訓練數據和測試期間看到的數據之間的分布差異。現有的離線強化學習方法關注如何在使用函數近似時解決這一挑戰。例如,策略約束方法明確要求學到的策略避免采取數據集中未見的動作,價值正則化方法則通過將價值函數擬合到某種形式的下限,緩解了價值函數的高估問題。然而,離線訓練的策略是否能泛化到離線數據集中未見的新環境中,仍然沒有得到充分的探索。
或許,我們可以避開 RL 策略的學習,而是利用離線數據學習有利于下游任務的收斂速度或最終性能的先驗知識。更有趣的是,如果我們的模型能夠在沒有人類監督的情況下利用離線數據,它就有可能從海量的數據中獲益。本文中,研究者把這種設定稱為離線預訓練,智能體可以從離線數據中提取重要的信息(例如,良好的表征和行為先驗)。

邁向通用智能體
在單一環境和單一模態下的預訓練方法主要集中于以上提到的在線預訓練和離線預訓練設定,而在最近,領域內的研究者對建立一個單一的通用決策模型的興趣激增(例如,Gato [1] 和 Multi-game DT [2]),使得同一模型能夠處理不同環境中不同模態的任務。為了使智能體能夠從各種開放式任務中學習并適應這些任務,該研究希望能夠利用不同形式的大量先驗知識,如視覺感知和語言理解。更為重要地是,如果研究者能成功地在 RL 和其他領域的機器學習之間架起一座橋梁,將以前的成功經驗結合起來,或許可以建立一個能夠完成各種任務的通用智能體模型。