雙11剛過,你的系統該怎么抗高并發還能高可用?

一、概述
??上一篇??文章講了一個朋友公司使用Spring Cloud架構遇到問題的一個真實案例,雖然不是什么大的技術問題,但如果對一些東西理解的不深刻,還真會犯一些錯誤。
如果沒看過上一篇文章的朋友,建議先看看:??我進了新公司結果不會用SpringCloud,人生第一次被辭退了??
因為本文的案例背景會基于上一篇文章。
這篇文章我們來聊聊在微服務架構中,到底如何保證整套系統的高可用?
排除掉一些基礎設施的故障,比如說Redis集群掛了,Elasticsearch集群故障了,MySQL宕機。
微服務架構本身最最核心的保障高可用的措施,就是兩點:
- 一個是基于Hystrix做資源隔離以及熔斷;
- 另一個是做備用降級方案。
如果資源隔離和降級都做的很完善,那么在雙11這種高并發場景下,也許可能會出現個別的服務故障,但是絕不會蔓延到整個系統全部宕機。
這里大家如果忘了如何基于hystrix做資源隔離、熔斷以及降級的話,可以回顧一下之前的文章: ??用SpringCloud的時候胡亂寫配置的兄弟們,事故加班一定很多??
二、業務場景介紹
大家首先回顧一下下面這張圖,這是上篇文章中說到的一個公司的系統。
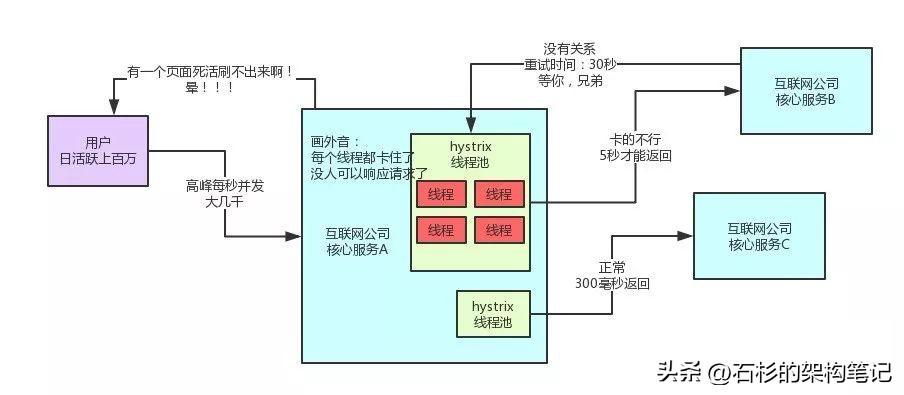
如上圖,核心服務A調用了核心服務B和C,在核心服務B響應過慢時,會導致核心服務A的某個線程池全部卡死。
但是此時因為你用了hystrix做了資源隔離,所以核心服務A是可以正常調用服務C的,那么就可以保證用戶起碼是可以使用APP的部分功能的,只不過跟服務B關聯的頁面刷不出來,功能無法使用罷了。
當然這種情況在生產系統中,是絕對不被允許的,所以大家不要讓上述情況發生。
在上一篇文章中,我們最終把系統優化成了下圖這樣:
- 要保證一個hystrix線程池可以輕松處理每秒鐘的請求。
- 同時還有合理的超時時間設置,避免請求太慢卡死線程。

三、線上經驗—如何設置Hystrix線程池大小
好,現在問題來了,在生產環境中,我們到底應該如何設置服務中每個hystrix線程池的大小?
下面是我們在線上經過了大量系統優化后的生產經驗總結:
假設你的服務A,每秒鐘會接收30個請求,同時會向服務B發起30個請求,然后每個請求的響應時長經驗值大概在200ms,那么你的hystrix線程池需要多少個線程呢?
計算公式是:30(每秒請求數量) * 0.2(每個請求的處理秒數) + 4(給點緩沖buffer) = 10(線程數量)。
如果對上述公式存在疑問,不妨反過來推算一下,為什么10個線程可以輕松抗住每秒30個請求?
一個線程200毫秒可以執行完一個請求,那么一個線程1秒可以執行5個請求,理論上,只要6個線程,每秒就可以執行30個請求。
也就是說,線程里的10個線程中,就6個線程足以抗住每秒30個請求了。剩下4個線程都在玩兒,空閑著。
那為啥要多搞4個線程呢?很簡單,因為你要留一點buffer空間。
萬一在系統高峰期,系統性能略有下降,此時不少請求都耗費了300多毫秒才執行完,那么一個線程每秒只能處理3個請求了,10個線程剛剛好勉強可以hold住每秒30個請求。所以你必須多考慮留幾個線程。
老規矩,給大家來一張圖,直觀的感受一下整個過程。

四、線上經驗—如何設置請求超時時間
線程數量OK了,那么請求的超時時間設置為多少?答案是300毫秒。
為啥呢?很簡單啊,如果你的超時時間設置成了500毫秒,想想可能會有什么后果?
考慮極端情況,如果服務B響應變慢,要500毫秒才響應,你一個線程每秒最多只能處理2個請求了,10個線程只能處理20個請求。
而每秒是30個請求過來,結局會如何?
咱們回看一下第一張圖就知道了,大量的線程會全部卡死,來不及處理那么多請求,最后用戶會刷不出來頁面。
還是有點不理解?再給你一張圖,讓你感受一下這個不合理的超時時間導致的問題!

如果你的線程池大小和超時時間沒有配合著設置好,很可能會導致服務B短暫的性能波動,瞬間導致服務A的線程池卡死,里面的線程要卡頓一段時間才能繼續執行下一個請求。
哪怕一段時間后,服務B的接口性能恢復到200毫秒以內了,服務A的線程池里卡死的狀況也要好一會兒才能恢復過來。
你的超時時間設置的越不合理,比如設置的越長,設置到了1秒、2秒,那么這種卡死的情況就需要越長的時間來恢復。
所以說,此時你的超時時間得設置成300毫秒,保證一個請求300毫秒內執行不完,立馬超時返回。
這樣線程池里的線程不會長時間卡死,可以有條不紊的處理多出來的請求,大不了就是300毫秒內處理不完立即超時返回,但是線程始終保持可以運行的狀態。
這樣當服務B的接口性能恢復到200毫秒以內后,服務A的線程池里的線程很快就可以恢復。
這就是生產系統上的hystrix參數設置優化經驗,你需要考慮到各種參數應該如何設置。
否則的話,很可能會出現上文那樣的情況,用了高大上的Spring Cloud架構,結果跟黑盒子一樣,莫名其妙系統故障,各種卡死,宕機什么的。
好了,我們繼續。如果現在這套系統每秒有6000請求,然后核心服務A一共部署了60臺機器,每臺機器就是每秒會收到100個請求,那么此時你的線程池需要多少個線程?
很簡單,10個線程抗30個請求,30個線程抗100請求,差不多了吧。
這個時候,你應該知道服務A的線程池調用服務B的線程池分配多少線程了吧?超時時間如何設置應該也知道了!
其實這個東西不是固定死的,但是你要知道他的計算方法。
根據服務的響應時間、系統高峰QPS、有多少臺機器,來計算出來,線程池的大小以及超時時間!
五、服務降級
設置完這些后,就應該要考慮服務降級的事了。
如果你的某個服務掛了,那么你的hystrix會走熔斷器,然后就會降級,你需要考慮到各個服務的降級邏輯。
舉一些常見的例子:
- 如果查詢數據的服務掛了,你可以查本地的緩存。
- 如果寫入數據的服務掛了,你可以先把這個寫入操作記錄日志到比如mysql里,或者寫入MQ里,后面再慢慢恢復。
- 如果redis掛了,你可以查mysql。
- 如果mysql掛了,你可以把操作日志記錄到es里去,后面再慢慢恢復數據。
具體用什么降級策略,要根據業務來定,不是一成不變的。
六、總結
最后總結一下,排除那些基礎設施的故障,你要玩兒微服務架構的話,需要保證兩點:
- 首先你的hystrix資源隔離以及超時這塊,必須設置合理的參數,避免高峰期,頻繁的hystrix線程卡死。
- 其次,針對個別的服務故障,要設置合理的降級策略,保證各個服務掛了,可以合理的降級,系統整體可用!