迭代vs向量化,如何提升Pandas性能?
在本文中,我們將探討幾種通過迭代和向量化技術來提高Pandas代碼性能的方法。
迭代是遍歷數據結構元素的過程,而向量化是將操作同時應用于整個數組或數據系列的一種方法,利用底層優化來提高效率。
通過有效地使用這些技術,我們可以加速數據分析任務并提高代碼的效率。
理解迭代和向量化的區別
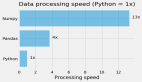
在這個例子中,我們將使用NumPy比較迭代和向量化的性能。
首先,導入所需的庫并創建一個隨機數據集。
import numpy as np
import time
# 創建一個包含1000萬個數據點的隨機數據集
data = np.random.rand(10000000)
data.shape(10000000,)
現在,使用for循環(迭代)來計算數據集中各元素的總和。
start_time = time.time()
sum_iter = 0
for i in data:
sum_iter += i
end_time = time.time()
print("Iteration - Sum:", sum_iter)
Print("Iteration - Time taken:", end_time - start_time, "seconds")(‘Iteration — Time taken:’, 3.507000207901001, ‘seconds’)
接下來,使用NumPy的內置函數(向量化)來計算數據集中各元素的總和。
start_time = time.time()
sum_vec = np.sum(data)
end_time = time.time()
print("Vectorization - Sum:", sum_vec)
print("Vectorization - Time taken:", end_time - start_time, "seconds")(‘Vectorization — Time taken:’, 0.006000041961669922, ‘seconds’)
通過比較兩種方法所需的時間,可以觀察到向量化所實現的性能提升。
使用向量化函數加速操作
在這個例子中,我們將演示如何使用向量化函數來加速Python中的操作。我們將比較使用for循環和向量化函數執行操作所需的時間。
首先,導入必要的庫并創建一個包含隨機數的數組。
import numpy as np
import time
# 創建一個包含100萬個隨機數的數組
data = np.random.rand(1000000)
data.shape(1000000,)
現在,使用for循環執行操作,并計算出所需的時間。
使用for循環
start_time = time.time()
result = []
for value in data:
result.append(value * 2)
end_time = time.time()
for_loop_time = end_time - start_time
print("Time taken using a for loop: ", for_loop_time)(‘Time taken using a for loop: ‘, 0.3400001525878906)
接下來,使用向量化函數執行相同的操作,并計算出所需的時間。
使用向量化函數
start_time = time.time()
result = data * 2
end_time = time.time()
vectorized_time = end_time - start_time
print("Time taken using a vectorized function: ", vectorized_time)(‘Time taken using a vectorized function: ‘, 0.059999942779541016)
最后,比較一下兩種方法所需的時間。
print("Speedup factor: ", for_loop_time / vectorized_time)(‘Speedup factor: ‘, 5.6666746139602155)
正如在示例中所看到的那樣,向量化函數比for循環快得多。這是因為向量化函數利用了底層優化和硬件能力,使它們更加高效地處理大型數據集上的操作。
使用NumPy向量化優化代碼
向量化是將一個逐個處理元素的算法轉換為一個等效的同時處理多個元素的算法的過程。
這可以帶來顯著的性能提升,特別是在處理大型數據集時。
讓我們從創建一個簡單的NumPy數組并使用迭代和向量化進行加法運算開始。
首先,導入所需的庫并創建一個NumPy數組。
import numpy as np
import time
# 創建一個包含1000萬個元素的NumPy數組
arr = np.arange(1, 10000001)
arrarray([ 1, 2, 3, …, 9999998, 9999999, 10000000])
現在,使用迭代(for循環)執行加法運算。
# 使用for循環進行迭代
start_time = time.time()
result = np.zeros(len(arr))
for i in range(len(arr)):
result[i] = arr[i] + 1
print("Time taken for iteration: {} seconds".format(time.time() - start_time))Time taken for iteration: 7.158999681472778 seconds
接下來,使用NumPy向量化執行相同的加法運算。
# 使用NumPy進行向量化
start_time = time.time()
result_vectorized = arr + 1
print("Time taken for vectorization: {} seconds".format(time.time() - start_time))Time taken for vectorization: 0.01999974250793457 seconds
你會注意到向量化所需的時間明顯低于迭代所需的時間。這展示了NumPy向量化在優化代碼性能方面的強大作用。
現在,看另一個使用更復雜的操作的例子——計算兩組點之間的歐幾里得距離。
# 創建兩組點
points_a = np.random.random((1000000, 2))
points_b = np.random.random((1000000, 2))首先,使用迭代法計算歐幾里得距離。
def euclidean_distance_iterative(points_a, points_b):
num_points = len(points_a)
distances = np.zeros(num_points)
for i in range(num_points):
distances[i] = np.sqrt(np.sum((points_a[i] - points_b[i])**2))
return distancesstart_time = time.time()
result_iterative = euclidean_distance_iterative(points_a, points_b)
print("Time taken for iterative Euclidean distance: {} seconds".format(time.time() - start_time))Time taken for iterative Euclidean distance: 7.052000045776367 seconds
現在,使用NumPy向量化計算歐幾里得距離。
def euclidean_distance_vectorized(points_a, points_b):
return np.sqrt(np.sum((points_a - points_b)**2, axis=1))start_time = time.time()
result_vectorized = euclidean_distance_vectorized(points_a, points_b)
print("Time taken for vectorized Euclidean distance: {} seconds".format(time.time() - start_time))Time taken for vectorized Euclidean distance: 0.03600001335144043 seconds
同樣,你會注意到向量化方法所需的時間要比迭代方法低得多。
總之,使用NumPy的向量化可以極大地提高代碼性能,特別是在處理大型數據集時。在處理數值運算時,可以考慮向量化你的代碼,從而獲得更好的性能。