













地址標(biāo)準(zhǔn)化服務(wù)AI深度學(xué)習(xí)模型推理優(yōu)化實(shí)踐
導(dǎo)讀
深度學(xué)習(xí)已在面向自然語言處理等領(lǐng)域的實(shí)際業(yè)務(wù)場景中廣泛落地,對(duì)它的推理性能優(yōu)化成為了部署環(huán)節(jié)中重要的一環(huán)。推理性能的提升:一方面,可以充分發(fā)揮部署硬件的能力,降低用戶響應(yīng)時(shí)間,同時(shí)節(jié)省成本;另一方面,可以在保持響應(yīng)時(shí)間不變的前提下,使用結(jié)構(gòu)更為復(fù)雜的深度學(xué)習(xí)模型,進(jìn)而提升業(yè)務(wù)精度指標(biāo)。
本文針對(duì)地址標(biāo)準(zhǔn)化服務(wù)中的深度學(xué)習(xí)模型開展了推理性能優(yōu)化工作。通過高性能算子、量化、編譯優(yōu)化等優(yōu)化手段,在精度指標(biāo)不降低的前提下,AI模型的模型端到端推理速度最高可獲得了4.11倍的提升。
1. 模型推理性能優(yōu)化方法論
模型推理性能優(yōu)化是AI服務(wù)部署時(shí)的重要環(huán)節(jié)之一。一方面,它可以提升模型推理的效率,充分釋放硬件的性能。另一方面,它可以在保持推理延遲不變的前提下,使得業(yè)務(wù)采用復(fù)雜度更高的模型,進(jìn)而提升精度指標(biāo)。然而,在實(shí)際場景中推理性能優(yōu)化會(huì)遇到一些困難。
1.1 自然語言處理場景優(yōu)化難點(diǎn)
典型的自然語言處理(Natural Language Processing, NLP)任務(wù)中,循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network, RNN)以及BERT[7](Bidirectional Encoder Representations from Transformers.)是兩類使用率較高的模型結(jié)構(gòu)。為了便于實(shí)現(xiàn)彈性擴(kuò)縮容機(jī)制和在線服務(wù)部署的高性價(jià)比,自然語言處理任務(wù)通常部署于例如Intel? Xeon?處理器這樣的x86 CPU平臺(tái)。然而,隨著業(yè)務(wù)場景的復(fù)雜化,服務(wù)的推理計(jì)算性能要求越來越高。以上述RNN和BERT模型為例,其在CPU平臺(tái)上部署的性能挑戰(zhàn)如下:
- RNN
循環(huán)神經(jīng)網(wǎng)絡(luò)是一類以序列(sequence)數(shù)據(jù)為輸入,在序列的演進(jìn)方向進(jìn)行遞歸(recursion)且所有節(jié)點(diǎn)(循環(huán)單元)按鏈?zhǔn)竭B接的遞歸神經(jīng)網(wǎng)絡(luò)。實(shí)際使用中常見的RNN有LSTM,GRU以及衍生的一些變種。在計(jì)算過程中,如下圖所示,RNN結(jié)構(gòu)中每一次的后級(jí)輸出都依賴于相應(yīng)的輸入和前級(jí)輸出。因此,RNN可以完成序列類型的任務(wù),近些年在NLP甚至是計(jì)算機(jī)視覺領(lǐng)域被廣泛使用。RNN相較于與BERT而言,計(jì)算量更少,模型參數(shù)共享,但其計(jì)算時(shí)序依賴性會(huì)導(dǎo)致無法對(duì)序列進(jìn)行并行計(jì)算。
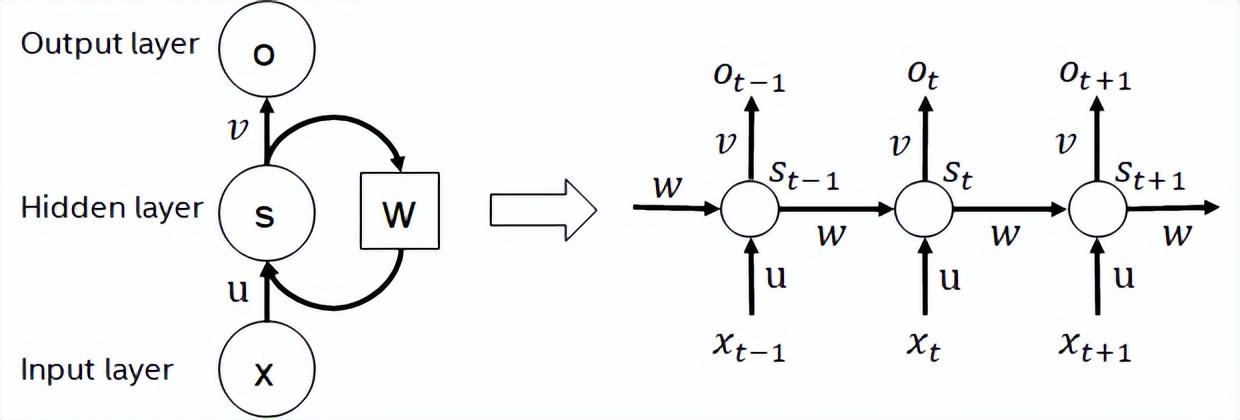
RNN結(jié)構(gòu)示意圖
- BERT
BERT[7]證明了能夠以較深的網(wǎng)絡(luò)結(jié)構(gòu)在大型數(shù)據(jù)集上完成無監(jiān)督預(yù)訓(xùn)練(Unsupervised Pre-training),進(jìn)而供給特定任務(wù)進(jìn)行微調(diào)(finetune)的模型。它不僅提升了這些特定任務(wù)的精度性能,還簡化了訓(xùn)練的流程。BERT的模型結(jié)構(gòu)簡單又易于擴(kuò)展,通過簡單地加深、加寬網(wǎng)絡(luò),即可獲得相較于RNN結(jié)構(gòu)更好的精度。而另一方面,精度提升是以更大的計(jì)算開銷為代價(jià)的,BERT模型中存在著大量的矩陣乘操作,這對(duì)于CPU而言是一種巨大的挑戰(zhàn)。
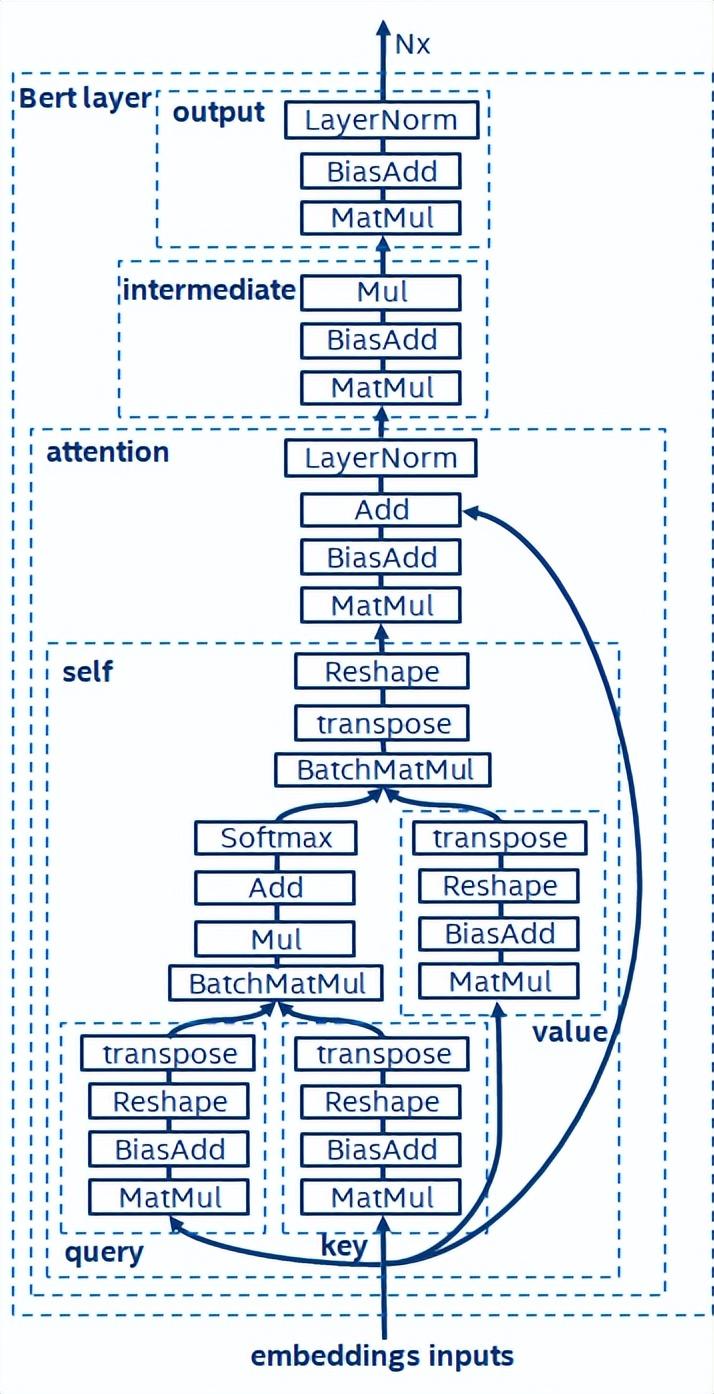
BERT模型結(jié)構(gòu)示意圖
1.2 模型推理優(yōu)化策略
基于上述推理性能挑戰(zhàn)的分析,我們認(rèn)為從軟件棧層面進(jìn)行模型推理優(yōu)化,主要有如下策略:
- 模型壓縮:包括量化、稀疏、剪枝等
- 特定場景的高性能算子
- AI編譯器優(yōu)化
量化
模型量化是指將浮點(diǎn)激活值或權(quán)重(通常以32比特浮點(diǎn)數(shù)表示)近似為低比特的整數(shù)(16比特或8比特),進(jìn)而在低比特的表示下完成計(jì)算的過程。通常而言,模型量化可以壓縮模型參數(shù),進(jìn)而降低模型存儲(chǔ)開銷;并且通過降低訪存和有效利用低比特計(jì)算指令(如Intel? Deep Learning Boost Vector Neural Network Instructions,VNNI),取得推理速度的提升。
給定浮點(diǎn)值,我們可以通過如下公式將其映射為低比特值:
其中和是通過量化算法所得。基于此,以Gemm操作為例,假設(shè)存在浮點(diǎn)計(jì)算流程:
我們可以在低比特域完成相應(yīng)的計(jì)算流程:
高性能算子
在深度學(xué)習(xí)框架中,為了保持通用性,同時(shí)兼顧各種流程(如訓(xùn)練),算子的推理開銷存在著冗余。而當(dāng)模型結(jié)構(gòu)確定時(shí),算子的推理流程僅是原始全量流程個(gè)一個(gè)子集。因此,當(dāng)模型結(jié)構(gòu)確定的前提下,我們可以實(shí)現(xiàn)高性能推理算子,對(duì)原始模型中的通用算子進(jìn)行替換,進(jìn)而達(dá)到提升推理速度的目的。
在CPU上實(shí)現(xiàn)高性能算子的關(guān)鍵在于減少內(nèi)存訪問和使用更高效的指令集。在原始算子的計(jì)算流程中,一方面存在著大量的中間變量,而這些變量會(huì)對(duì)內(nèi)存進(jìn)行大量的讀寫操作,進(jìn)而拖慢推理的速度。針對(duì)這種情況,我們可以修改其計(jì)算邏輯,以降低中間變量的開銷;另一方面,算子內(nèi)部的一些計(jì)算步驟我們可以直接調(diào)用向量化指令集,對(duì)其進(jìn)行加速,如Intel? Xeon?處理器上的高效的AVX512指令集。
AI編譯器優(yōu)化
隨著深度學(xué)習(xí)領(lǐng)域的發(fā)展,模型的結(jié)構(gòu)、部署的硬件呈現(xiàn)出多樣化演進(jìn)的趨勢(shì)。將模型部署至各硬件平臺(tái)時(shí),我們通常會(huì)調(diào)用各硬件廠商推出的runtime。而在實(shí)際業(yè)務(wù)場景中,這可能會(huì)遇到一些挑戰(zhàn),如:
- 模型結(jié)構(gòu)、算子類型的迭代的速度會(huì)高于廠家的runtime,使得一些模型無法快速基于廠商的runtime完成部署。此時(shí)需要依賴于廠商進(jìn)行更新,或者利用plugin等機(jī)制實(shí)現(xiàn)缺失的算子。
- 業(yè)務(wù)可能包含多個(gè)模型,這些模型可能由多個(gè)深度學(xué)習(xí)框架訓(xùn)得,此外模型可能需要部署至多個(gè)硬件平臺(tái)。此時(shí)需要將這些格式不同的模型轉(zhuǎn)化至各個(gè)硬件平臺(tái)所需的格式,同時(shí)要考慮各推理框架實(shí)現(xiàn)的不同導(dǎo)致的模型精度性能變化等問題,尤其是像量化這類對(duì)于數(shù)值差異敏感度較高的方法。
AI編譯器就是為了解決上述問題而提出的,它抽象出了多個(gè)層次來解決上述的一些問題。首先,它接受各個(gè)前端框架的模型計(jì)算圖作為輸入,并通過各類Converter轉(zhuǎn)化生成統(tǒng)一的中間表示。隨后,諸如算子融合、循環(huán)展開等圖優(yōu)化pass會(huì)作用至中間表示,以提升推理性能。最后,AI編譯器會(huì)基于優(yōu)化后的計(jì)算圖進(jìn)行面向特定硬件平臺(tái)的codegen,生成可執(zhí)行的代碼,這過程中會(huì)引入諸如stitch、shape constraint等優(yōu)化策略。AI編譯器有很好魯棒性、適應(yīng)性、易用性,并且能夠收獲顯著優(yōu)化收益。
本文中,阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI團(tuán)隊(duì)聯(lián)合英特爾數(shù)據(jù)中心軟件團(tuán)隊(duì)、英特爾人工智能和分析團(tuán)隊(duì)、達(dá)摩院NLP地址標(biāo)準(zhǔn)化團(tuán)隊(duì),針對(duì)地址標(biāo)準(zhǔn)化服務(wù)的推理性能挑戰(zhàn),合作實(shí)現(xiàn)了高性能的推理優(yōu)化方案。
2. 地址標(biāo)準(zhǔn)化介紹
公安政務(wù)、電商物流、能源(水電燃)、運(yùn)營商、新零售、金融、醫(yī)療等行業(yè)在業(yè)務(wù)開展的過程中往往涉及大量地址數(shù)據(jù),而這些數(shù)據(jù)往往沒有形成標(biāo)準(zhǔn)結(jié)構(gòu)規(guī)范,存在地址缺失、一地多名等問題。隨著數(shù)字化的升級(jí),城市地址不標(biāo)準(zhǔn)的問題愈加凸顯。
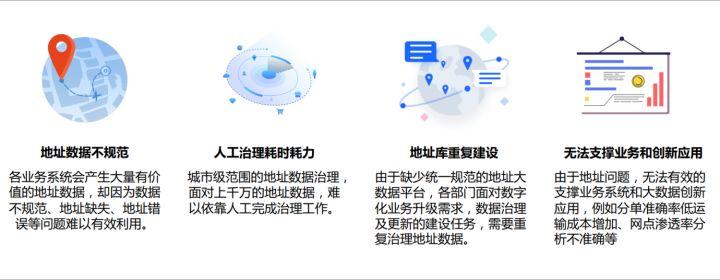
地址應(yīng)用現(xiàn)存問題
地址標(biāo)準(zhǔn)化[2](Address Purification)是阿里巴巴達(dá)摩院NLP團(tuán)隊(duì)依托阿里云海量的地址語料庫,以及超強(qiáng)的NLP算法實(shí)力所沉淀出的高性能及高準(zhǔn)確率的標(biāo)準(zhǔn)地址算法服務(wù)。地址標(biāo)準(zhǔn)化產(chǎn)品從規(guī)范地址數(shù)據(jù)、建立統(tǒng)一標(biāo)準(zhǔn)地址庫的角度出發(fā),提供高性能地址算法。
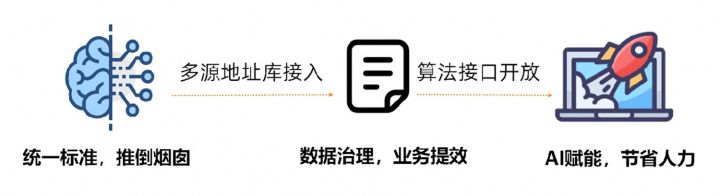
地址標(biāo)準(zhǔn)化優(yōu)勢(shì)
該地址算法服務(wù)能自動(dòng)地標(biāo)準(zhǔn)化處理地址數(shù)據(jù),可有效地解決一地多名,地址識(shí)別,地址真?zhèn)伪鎰e等地址數(shù)據(jù)不規(guī)范、人工治理耗時(shí)耗力、地址庫重復(fù)建設(shè)問題,為企業(yè),政府機(jī)關(guān)以及開發(fā)者提供地址數(shù)據(jù)清洗,地址標(biāo)準(zhǔn)化能力,使地址數(shù)據(jù)更好的為業(yè)務(wù)提供支持。地址標(biāo)準(zhǔn)化產(chǎn)品具有如下的幾個(gè)特點(diǎn):
- 準(zhǔn)確率高:擁有海量地址語料庫以及超強(qiáng)的NLP算法技術(shù),并持續(xù)優(yōu)化迭代,地址算法準(zhǔn)確率高
- 超強(qiáng)性能:積累了豐富的項(xiàng)目建設(shè)經(jīng)驗(yàn),能夠穩(wěn)定承載海量數(shù)據(jù)
- 服務(wù)全面:提供20多種地址服務(wù),滿足不同業(yè)務(wù)場景需求
- 部署靈活:支持公共云、混合云、私有化部署。
本次優(yōu)化的模塊屬于地址標(biāo)準(zhǔn)化中的搜索模塊。地址搜索是指用戶輸入地址文本相關(guān)信息,基于地址庫和搜索引擎,對(duì)用戶輸入的地址文本進(jìn)行搜索和聯(lián)想,并返回相關(guān)興趣點(diǎn)(Point of Interest,POI)信息。地址搜索功能不僅能夠提升用戶數(shù)據(jù)處理體驗(yàn),同時(shí)也是多個(gè)地址下游服務(wù)的基礎(chǔ),如經(jīng)緯度查詢、門址標(biāo)準(zhǔn)化、地址歸一等,因此在整套地址服務(wù)體系中起到了關(guān)鍵作用。
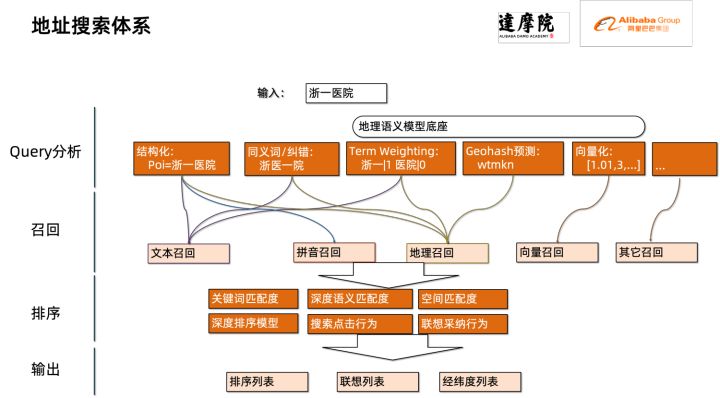
地址服務(wù)搜索體系示意圖
具體而言,本次優(yōu)化的模型是基于多任務(wù)地理預(yù)訓(xùn)練語言模型底座產(chǎn)出的多任務(wù)向量召回模型和精排模型。
多任務(wù)地理預(yù)訓(xùn)練語言模型底座在掩碼語言模型 (Masked Language Model, MLM) 任務(wù)的基礎(chǔ)上結(jié)合了相關(guān)興趣點(diǎn)分類與地址元素識(shí)別(省、市、區(qū)、POI 等),并通過元學(xué)習(xí)(Meta Learning)的方式,自適應(yīng)地調(diào)整多個(gè)任務(wù)的采樣概率,在語言模型中融入通用的地址知識(shí)。
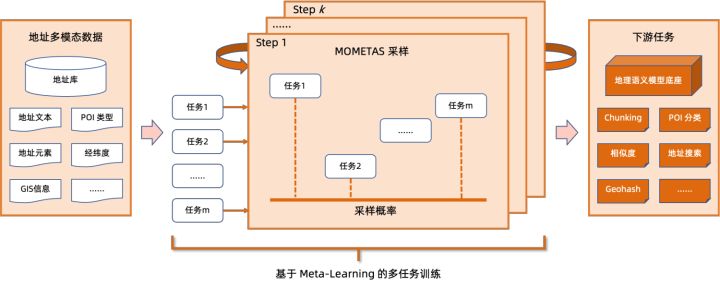
多任務(wù)地址預(yù)訓(xùn)練模型底座示意圖
多任務(wù)向量召回模型基于上述底座訓(xùn)練所得,包含雙塔相似度、Geohash (地址編碼) 預(yù)測、分詞和 Term Weighting (詞權(quán)重) 四個(gè)任務(wù)。
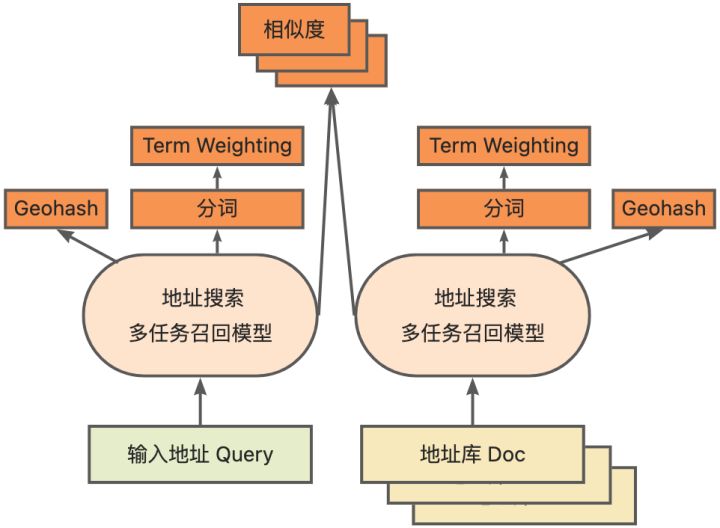
多任務(wù)向量召回模型示意圖
作為計(jì)算地址相似度匹配的核心模塊,精排模型則是在上述底座的基礎(chǔ)上,引入了海量點(diǎn)擊數(shù)據(jù)和標(biāo)注數(shù)據(jù)訓(xùn)練訓(xùn)練所得[3],并通過模型蒸餾技術(shù),提升了模型的效率[4]。最終用應(yīng)用于召回模型召回的地址庫文檔重新排序。基于上述流程訓(xùn)練得到的4層單模型能夠在CCKS2021中文NLP地址相關(guān)性任務(wù)[5]上獲得較12層基線模型更好的效果(詳見性能展示部分)。
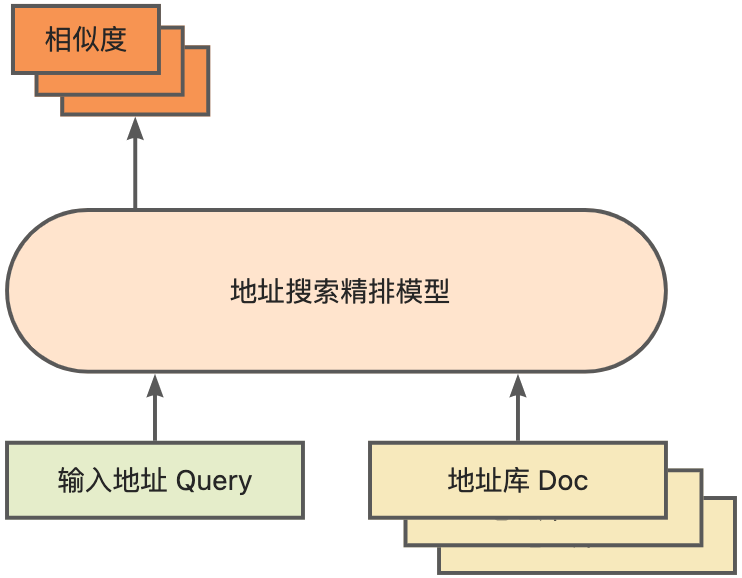
精排模型示意圖
3. 模型推理優(yōu)化解決方案
阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI團(tuán)隊(duì)推出的Blade產(chǎn)品支持以上提及的所有優(yōu)化方案,提供了統(tǒng)一的用戶接口,并擁有多個(gè)軟件后端,如高性能算子、Intel Custom Backend、BladeDISC等等。

Blade模型推理優(yōu)化架構(gòu)圖
3.1 Blade
Blade是阿里云機(jī)器學(xué)習(xí)PAI團(tuán)隊(duì)(Platform of Artificial Intelligence)推出的通用推理優(yōu)化工具,可以通過模型系統(tǒng)聯(lián)合優(yōu)化,使模型達(dá)到最優(yōu)推理性能。它有機(jī)融合了計(jì)算圖優(yōu)化、Intel? oneDNN等vendor優(yōu)化庫、BladeDISC編譯優(yōu)化、Blade高性能算子庫、Costom Backend、Blade混合精度等多種優(yōu)化手段。同時(shí),簡潔的使用方式降低了模型優(yōu)化門檻、提升了用戶體驗(yàn)和生產(chǎn)效率。
PAI-Blade支持多種輸入格式,包括Tensorflow pb、PyTorch torchscript等。對(duì)于待優(yōu)化的模型,PAI-Blade會(huì)對(duì)其進(jìn)行分析,再應(yīng)用多種可能的優(yōu)化手段,并從各種優(yōu)化結(jié)果中選取出加速效果最明顯的為最終的優(yōu)化結(jié)果。
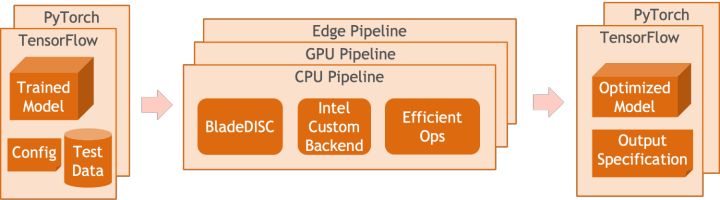
Blade優(yōu)化示意圖
為了在保證部署成功率的前提下獲得最大的優(yōu)化效果,PAI-Blade采取了“圈圖”的方式進(jìn)行優(yōu)化,即:
- 將待優(yōu)化子計(jì)算圖中,能夠被推理后端/高性能算子支持的部分轉(zhuǎn)化至相應(yīng)的優(yōu)化子圖;
- 無法被優(yōu)化的子圖回退(fallback)至相應(yīng)的原生框架(TF/Torch)執(zhí)行。
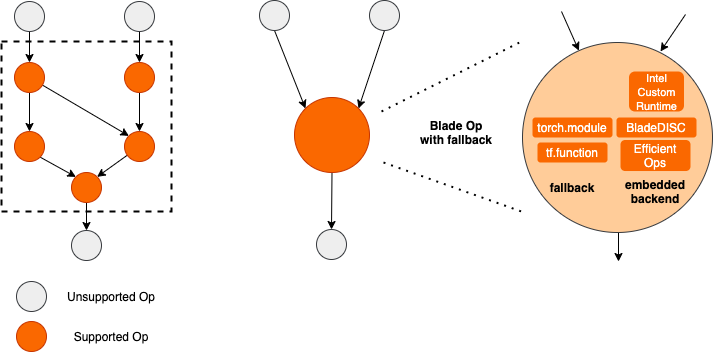
Blade圈圖示意圖
Blade Compression是Blade推出的面向模型壓縮的工具包,旨在協(xié)助開發(fā)人員進(jìn)行高效的模型壓縮優(yōu)化工作。它包含了多種模型壓縮功能,包括量化、剪枝、稀疏化等。壓縮后的模型可以便捷地通過Blade實(shí)現(xiàn)進(jìn)一步優(yōu)化,以獲得模型系統(tǒng)聯(lián)合的極致優(yōu)化。
量化方面,Blade Compression:
- 提供了簡潔的使用接口,通過調(diào)用幾個(gè)簡單api,即可完成量化改圖、校準(zhǔn)(calibration)、量化訓(xùn)練(Quantization-aware Training,QAT)、導(dǎo)出量化模型等步驟。
- 提供了多種后端的支持,通過config文件的配置,即可完成面向不同設(shè)備、不同后端的量化過程。
- 集成了PAI-Blade團(tuán)隊(duì)在實(shí)際生產(chǎn)業(yè)務(wù)中自研的各種算法,以獲得更高的量化精度。
同時(shí),我們提供了豐富的原子能力api,便于對(duì)特定情況進(jìn)行定制化開發(fā)。
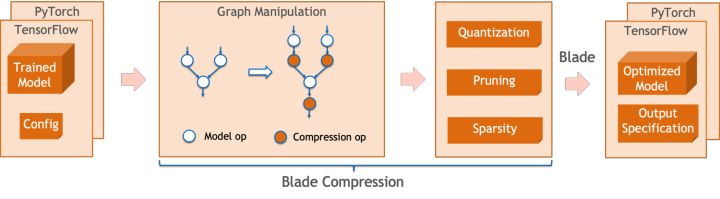
Blade Compression示意圖
BladeDISC是阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI團(tuán)隊(duì)推出的面向機(jī)器學(xué)習(xí)場景的動(dòng)態(tài)shape深度學(xué)習(xí)編譯器,是Blade的后端之一。它支持主流的前端框架(TensorFlow、PyTorch)與后端硬件(CPU、GPU),同時(shí)也支持推理以及訓(xùn)練的優(yōu)化。
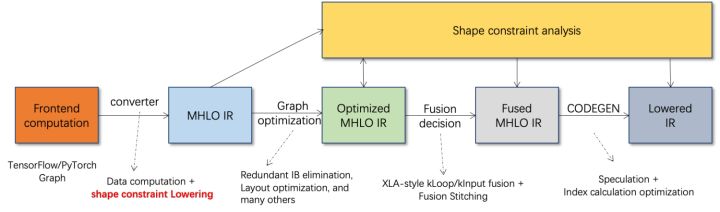
BladeDISC架構(gòu)圖
3.2 基于Intel? Xeon?的高性能算子
神經(jīng)網(wǎng)絡(luò)模型中的子網(wǎng)絡(luò)通常具有長期的通用性和普遍性,如 PyTorch 中的 Linear Layer 和Recurrent Layers 等,是模型建構(gòu)的基礎(chǔ)模塊,負(fù)責(zé)著特定的功能,通過這些模塊的不同組合得到形形色色的模型,并且這些模塊也是AI編譯器重點(diǎn)優(yōu)化的目標(biāo)。據(jù)此,為了得到最佳性能的基礎(chǔ)模塊,從而實(shí)現(xiàn)性能最佳的模型,Intel針對(duì)X86架構(gòu)對(duì)這些基礎(chǔ)模塊進(jìn)行了多層次優(yōu)化,包括使能高效的AVX512指令、算子內(nèi)部計(jì)算調(diào)度、算子融合、緩存優(yōu)化,并行優(yōu)化等等。
在地址標(biāo)準(zhǔn)化服務(wù)中,經(jīng)常會(huì)出現(xiàn)Recurrent Neural Network (RNN) 模型,并且RNN模型中最影響性能的模塊是LSTM或GRU等模塊,本章節(jié)以LSTM為例,呈現(xiàn)在不定長且多batch的輸入時(shí),如何實(shí)現(xiàn)對(duì)LSTM的極致性能優(yōu)化。
通常,為了滿足不同用戶的需求和請(qǐng)求,追求高性能和低成本的云上服務(wù)會(huì)將不同的用戶請(qǐng)求進(jìn)行Batch,以實(shí)現(xiàn)計(jì)算資源的最大化利用。如下圖所示,總共有3條已經(jīng)被embedding的句子,并且內(nèi)容和輸入的長度是不相同的。

原始輸入數(shù)據(jù)
為了使得LSTM計(jì)算的更高效,需要對(duì)Batched input采用PyTorch的pack_padded_sequence()函數(shù)進(jìn)行padding和sort,得到下圖所示,一個(gè)paddding的數(shù)據(jù)tensor,一個(gè)描述數(shù)據(jù)tensor的batch size的tensor,一個(gè)描述數(shù)據(jù)tensor的原始序號(hào)tensor。

原始輸入數(shù)據(jù)
到目前為止,已經(jīng)準(zhǔn)備好了LSTM的輸入,對(duì)于LSTM的計(jì)算過程如下圖所示,對(duì)輸入的tensor進(jìn)行分段批量計(jì)算,及跳過零值計(jì)算。
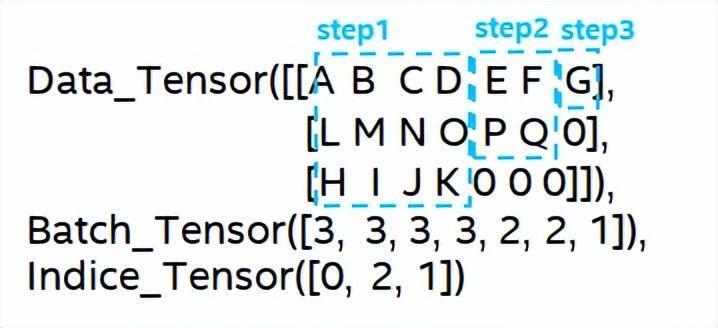
LSTM針對(duì)輸入的計(jì)算步驟
更深入的LSTM的計(jì)算優(yōu)化如下圖17所示,公式中的矩陣乘部分進(jìn)行了公式間計(jì)算融合,如下圖所示,原先4次矩陣乘轉(zhuǎn)換成1次矩陣乘,并且采用AVX512指令進(jìn)行數(shù)值計(jì)算,以及多線程并行優(yōu)化,從而實(shí)現(xiàn)高效的LSTM算子。其中,數(shù)值計(jì)算指的是矩陣乘和后序的elementwise的元素操作,針對(duì)矩陣乘部分,本方案采用的是oneDNN庫進(jìn)行計(jì)算,庫中具有高效的AVX512 GEMM實(shí)現(xiàn),針對(duì)elementwise的元素操作,本方案對(duì)其采用AVX512指令集進(jìn)行算子融合,提升了數(shù)據(jù)在緩存中的命中率。
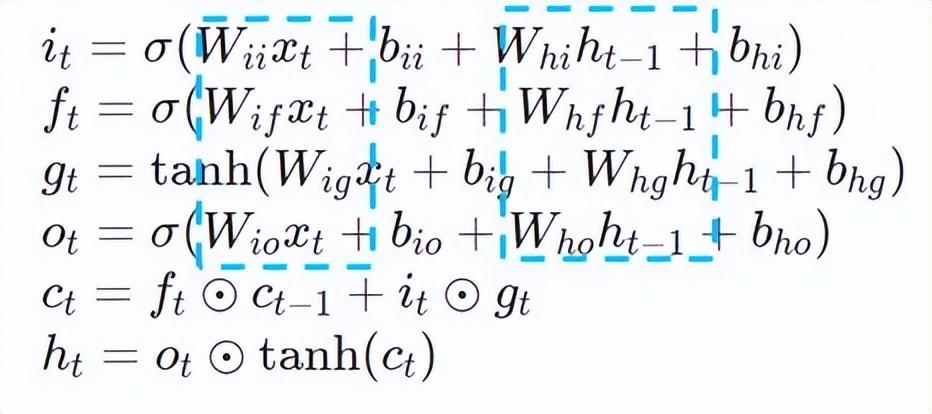
LSTM計(jì)算融合[8]
3.3 推理后端 Custom Backend
Intel custom backend[9]作為Blade的軟件后端,強(qiáng)有力地加速著模型量化和稀疏的推理性能,主要包含三個(gè)層面的優(yōu)化。首先,采用Primitive Cache的策略對(duì)內(nèi)存進(jìn)行優(yōu)化,其次,進(jìn)行圖融合優(yōu)化,最后,在算子層級(jí),實(shí)現(xiàn)了包含稀疏與量化算子在內(nèi)的高效算子庫。
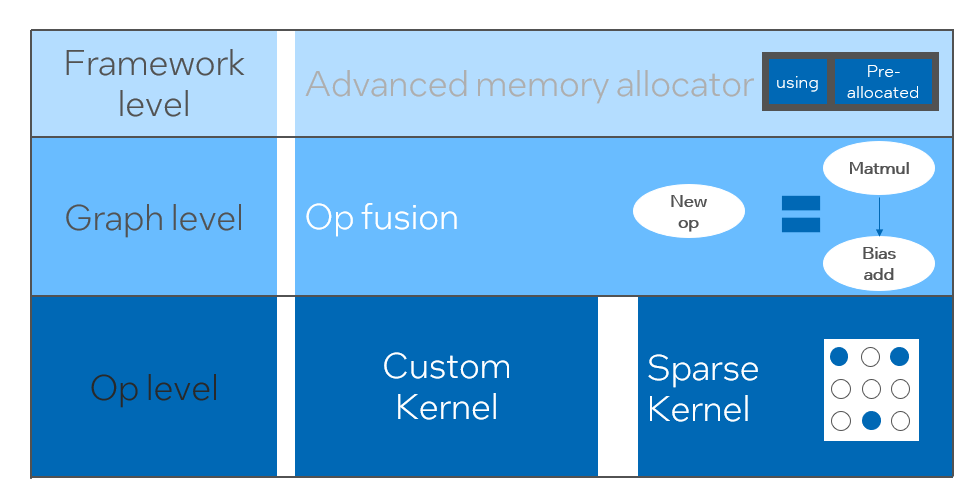
Intel Custom Backend架構(gòu)圖
低精度量化
稀疏與量化等高速算子, 得益于Intel? DL Boost加速指令集,如VNNI指令集。
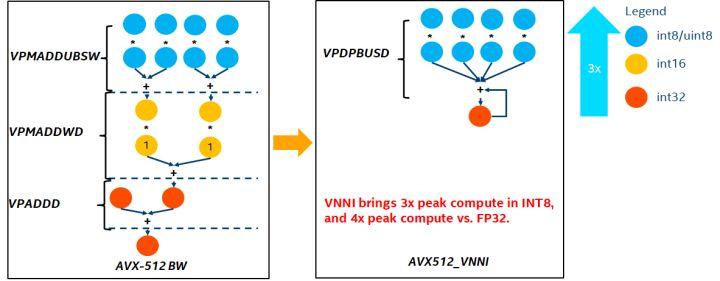
VNNI 指令介紹
上圖為VNNI 指令, 8bits可以使用AVX512 BW三個(gè)指令來加速, VPMADDUBSW 先對(duì)2對(duì)由8bits組成的數(shù)組做乘法與加法, 得到16bits數(shù)據(jù), VPMADDWD將相鄰數(shù)據(jù)加總起來,得到32bits數(shù)據(jù), 最后VPADDD加上一個(gè)常數(shù), 此三函數(shù)可組成一個(gè)AVX512_VNNI,此指令可用來加速推理中的矩陣相乘。
圖融合
除此之外,Custom Backend中也提供了圖融合,例如矩陣相乘后不輸出中間態(tài)臨時(shí)Tensor,而是直接運(yùn)行后面指令,即將后項(xiàng)的post op與前級(jí)算子進(jìn)行融合,如此減少數(shù)據(jù)搬運(yùn)以減少運(yùn)行時(shí)間,下圖為一個(gè)范例,紅框內(nèi)的算子融合后可消除額外的數(shù)據(jù)搬移,成為一個(gè)新的算子。
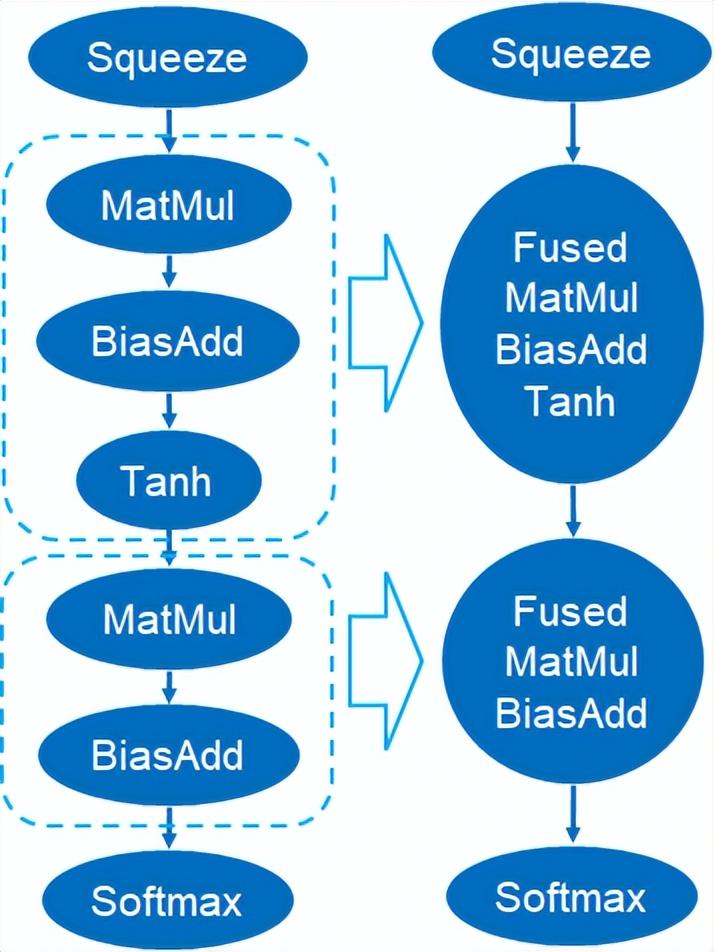
圖融合
內(nèi)存優(yōu)化
內(nèi)存分配與釋放會(huì)與操作系統(tǒng)進(jìn)行通信,從而導(dǎo)致運(yùn)行時(shí)的延時(shí)增加,為了減少這部分的開銷,Custom Backend中增加了Primitive Cache的設(shè)計(jì),Primitive Cache用于緩存已經(jīng)被創(chuàng)建的Primitive,使得Primitive不能被系統(tǒng)回收,減少了下一次調(diào)用時(shí)的創(chuàng)建開銷。
同時(shí)為耗時(shí)較大的算子建立了快取機(jī)制,以加速算子運(yùn)行,如下圖所示:
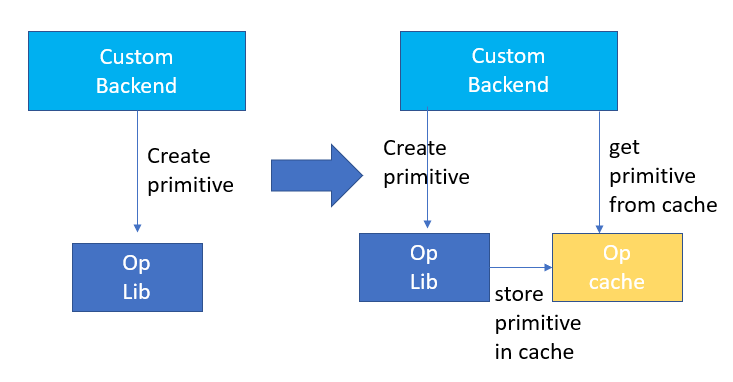
Primitive Cache
量化功能如之前所說,模型大小減小后,計(jì)算與存取的開銷大幅減少,從而性能得到巨大的提升。
4. 整體性能展示
我們選取了地址搜索服務(wù)中典型的兩個(gè)模型結(jié)構(gòu)來驗(yàn)證上述優(yōu)化方案的效果。測試環(huán)境如下所示:
- 服務(wù)器型號(hào):阿里云 ecs.g7.large,2 vCPU
- 測試CPU型號(hào):Intel? Xeon? Platinum 8369B CPU @ 2.70GHz
- 測試CPU核數(shù):1 vCPU
- PyTorch版本:1.9.0+cpu
- onnx版本:1.11.0
- onnxruntime版本:1.11.1
4.1 ESIM
ESIM[6]是一種專為自然語言推斷而生的加強(qiáng)版LSTM,它的推理開銷主要來自于模型中的LSTM結(jié)構(gòu)。Blade利用Intel數(shù)據(jù)中心軟件團(tuán)隊(duì)開發(fā)的高性能通用LSTM算子對(duì)其進(jìn)行加速,替換PyTorch module中的默認(rèn)LSTM (Baseline)。本次測試的ESIM中包含兩種LSTM結(jié)構(gòu),單算子優(yōu)化前后的性能如表所示:
LSTM結(jié)構(gòu) | 輸入shape | 優(yōu)化前RT | 優(yōu)化后RT | 加速比 |
LSTM - A | 7x200 | 0.199ms | 0.066ms | +3.02x |
202x200 | 0.914ms | 0.307ms | +2.98x | |
LSTM - B | 70x50 | 0.266ms | 0.098ms | +2.71x |
202x50 | 0.804ms | 0.209ms | +3.85x |
LSTM單算子優(yōu)化前后推理性能
優(yōu)化前后,ESIM端到端推理速度如表 所示,同時(shí)優(yōu)化前后模型的精度保持不變。
模型結(jié)構(gòu) | ESIM[6] | ESIM[6]+Blade算子優(yōu)化 | 加速比 |
RT | 6.3ms | 3.4ms | +1.85x |
ESIM模型優(yōu)化前后推理性能
4.2 BERT
BERT[7]近年來在自然語言處理 (NLP) 、計(jì)算機(jī)視覺(CV)等領(lǐng)域被廣泛采納。Blade對(duì)該種結(jié)構(gòu)有編譯優(yōu)化(FP32)、量化(INT8)等多種手段。
速度測試中,測試數(shù)據(jù)的shape固定為10x53,各種后端及各種優(yōu)化手段的速度性能如下表所示。可以看到,blade編譯優(yōu)化后或INT8量化后的模型推理速度均優(yōu)于libtorch與onnxruntime,其中推理的后端是Intel Custom Backend & BladeDisc。值得注意的是,經(jīng)過量化加速后的4層BERT的速度是2層BERT的1.5倍,意味著可以在提速的同時(shí),讓業(yè)務(wù)用上更大的模型,獲得更好的業(yè)務(wù)精度。
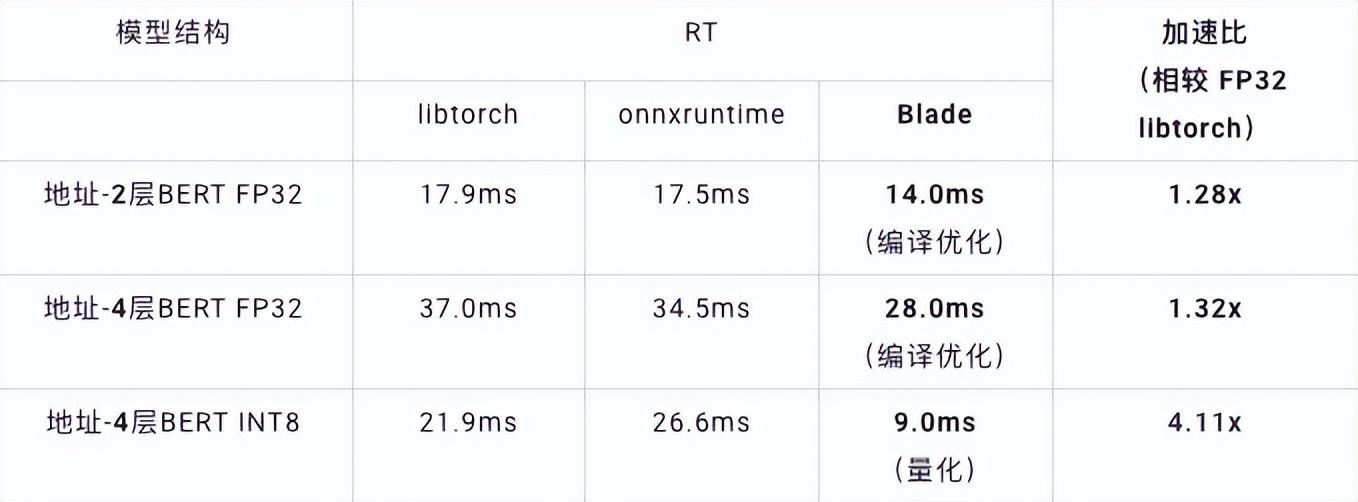
地址BERT推理性能展示
精度方面,我們基于CCKS2021中文NLP地址相關(guān)性任務(wù)[5]展示相關(guān)模型性能,如下表所示。達(dá)摩院地址團(tuán)隊(duì)自研的4層BERT的macro F1精度要高于標(biāo)準(zhǔn)的12層BERT-base。Blade編譯優(yōu)化可以做到精度無損,而經(jīng)過Blade Compression量化訓(xùn)練后的真實(shí)量化模型精度要略高于原始浮點(diǎn)模型。
模型結(jié)構(gòu) | macro F1(越高越好) |
12層BERT-base | 77.24 |
地址-4層BERT | 78.72(+1.48) |
地址-4層BERT + Blade編譯優(yōu)化 | 78.72(+1.48) |
地址-4層BERT + Blade量化 | 78.85(+1.61) |
地址BERT相關(guān)精度結(jié)果


















