













攜程AI推理性能的自動化優化實踐
一、背景
近年來,人工智能逐漸在安防,教育,醫療和旅游等工業和生活場景中落地開花。在攜程旅游業務上,AI技術同樣廣泛覆蓋了多個旅游產品和旅游服務領域,攜程度假AI研發根據旅游的特定場景和業務需求,將自然語言處理,機器翻譯,計算機視覺,搜索排序等主流AI技術成功應用于旅游度假的多個業務線,例如自由行,跟團游,簽證,玩樂和租車等。
從技術角度,為了適應不同的業務場景需求,涉及到多種AI技術,包括傳統機器學習,卷積神經網絡,Transformer等深度學習模型結構,以及知識圖譜和圖神經網絡等技術領域。同時,為了充分挖掘AI技術的優勢,模型設計復雜度日漸提升,包括模型深度,寬度以及結構復雜度等各個維度,計算量的增大使得AI推理性能瓶頸日益凸顯,尤其是實時性的業務需求對推理速度要求更高。為了追求最佳推理性能,往往需要手動進行逐個優化,涉及的開發,部署和溝通成本都很高。主要問題集中在:
- 模型結構種類多,性能瓶頸差異較大,適用的優化方法各有不同,手動優化成本高;
- 優化方法眾多,自上而下,涉及多種模型壓縮方式,系統級,運行時優化等,手動優化門檻高;
- 逐個手動優化,可推廣性差,技術覆蓋面有限;
- 硬件平臺的差異,需要針對性調優,導致優化的人力成本和部署成本都很高;
- 新模型的發布和迭代,需要應用優化方法,涉及較高的溝通和接入成本,同時帶來了性能的不穩定性;
- 模型壓縮技術對不同模型的優化效果有所差異,可能需要進行模型的再訓練,訓練和數據準備流程較長,效率低下。
因此,為了降低優化,部署和迭代成本,提高工作效率,并保證性能穩定,我們嘗試搭建模型自動化優化平臺,旨在為算法模型提供更全面易用,穩定性更好,使用和維護成本更低的優化解決方案。
二、優化平臺的主要框架
從性能優化方法論的角度,無論是自動優化還是手動優化,主要關注以下兩大方向:
- 降低算法復雜度:可通過調整或簡化模型結構,或者保持結構不變,改進算法實現效率;
- 充分發揮軟硬件性能:模型結構和算法不變,優化軟件執行效率,使用硬件優勢特征,最大化硬件執行效率。
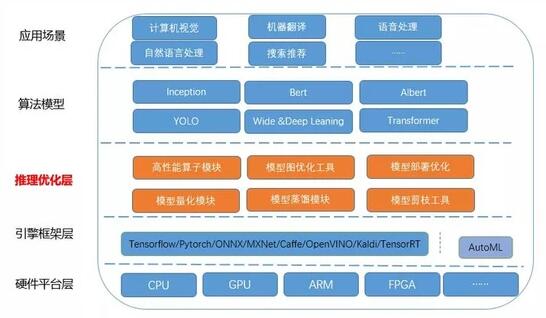
圍繞這兩大優化方向以及人工智能的主流技術方向,優化平臺的整體架構層自下而上可以劃分為:
- 硬件平臺和操作系統層,包含x86架構的CPU,GPU,ARM,FPGA等多種平臺,操作系統主要是Linux OS;
- 引擎框架層,主要是Tensorflow,Pytorch等人工智能主流框架;
- 推理優化層,主要是由我們結合業務場景和實際需求進行自主研發的優化技術,包含高性能算子庫,圖優化和修改工具以及量化蒸餾等模型壓縮模塊;
- 算法模型:包含業界常用模型,例如以卷積為主要結構的CV模型,Resnet,GoogleNet,YOLO等;以Transformer為主要結構的NLP模型Bert,Albert等;
- 應用場景:主要體現在旅游場景中的實際應用,例如智能客服平臺,機器翻譯,搜索排序等應用。
三、自動化優化流程
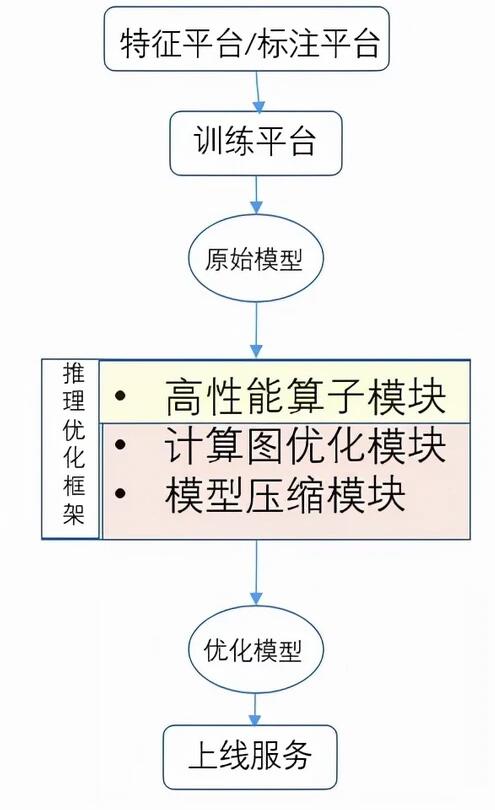
優化平臺的搭建能夠系統有效地將優化技術整合起來,并快速應用于實際需求,但是如果不實現自動化優化,優化效率比較低,部署和迭代成本,溝通和接入成本高。因此我們建立了自動化優化流程,將所支持的優化技術涵蓋在內,結合模型訓練平臺,數據標注平臺,從模型設計,模型訓練到模型推理優化,模型部署全鏈路,實現零介入無感知的優化效果,大大提升工作效率以及整體優化效果的穩定性。
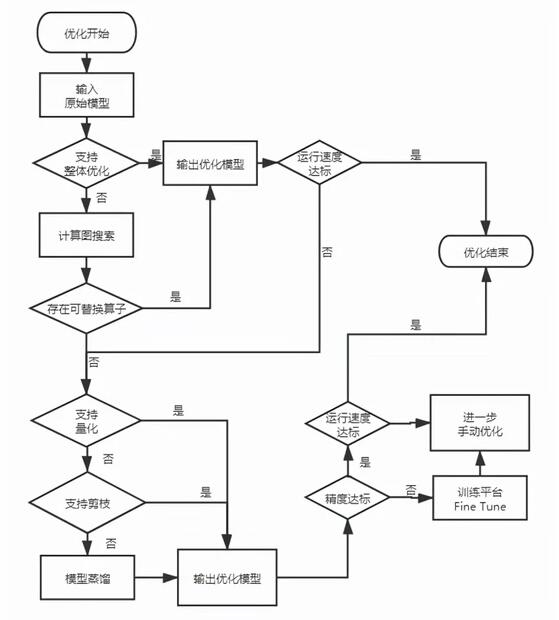
圖2所示為數據平臺,模型訓練平臺,模型優化和部署的大概流程。具體有哪些優化手段,如何進行自動化實現的流程細節如圖3所示。
四、功能模塊
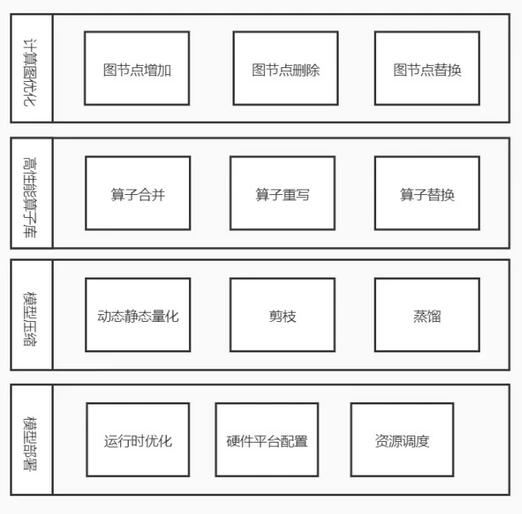
自動化優化平臺的主要功能模塊分四部分:
- 高性能算子庫,包括算子重寫,算子合并等多個優化,支持attention,softmax,Layer norm等多個常用算子;
- 計算圖優化,主要進行計算圖搜索,修改替換模型圖結構,合并生成新的模型文件進行推理部署;同時包含常用的圖優化和修改工具;
- 模型壓縮模塊,包括模型靜態和動態量化,模型剪枝和蒸餾等;
- 模型部署優化,主要提供部署的優化方案,包括部署設計,運行時環境配置等。
4.1 高性能算子庫
該模塊主要實現了常用的算子以及激活函數,包含基礎算子,例如卷積,全連接層,batch norm,softmax等等以及合并后的經典的模型結構,例如transformer encoder,decoder等,基于tensorflow實現,采用c++實現,支持CPU和GPU平臺的優化。
具體的優化方法涵蓋了:
- 算法改進,例如卷積算法的實現,將im2col和winograd卷積相結合,針對不同卷積核大小自適應使用最佳算法,實現最快的速度;
- 內存重構,以BERT模型為例,最核心也是最耗時的計算模塊之一就是多頭自注意力機制multi-head self-attention,包含了大量的矩陣乘法計算,根據算法原理,包括query層,key層和value層的獲取,query和key點乘等等,更重要的是當前的tensorflow算法實現包含了大量的行列變換操作(transpose),transpose帶來大量的內存訪問開銷,這些問題可以通過內存重構來避免。
同時很多矩陣乘法實現可以通過批量矩陣乘法調用提升計算效率,從而帶來運行速度的提升。如下圖5所示,self-attention機制原始實現流程包含了三次冗余的transpose操作,T(a)表示張量a的transpose形式。通過對內存重構可以避免這三次transpose操作。如圖6所示,優化后的計算流程不包含transpose。
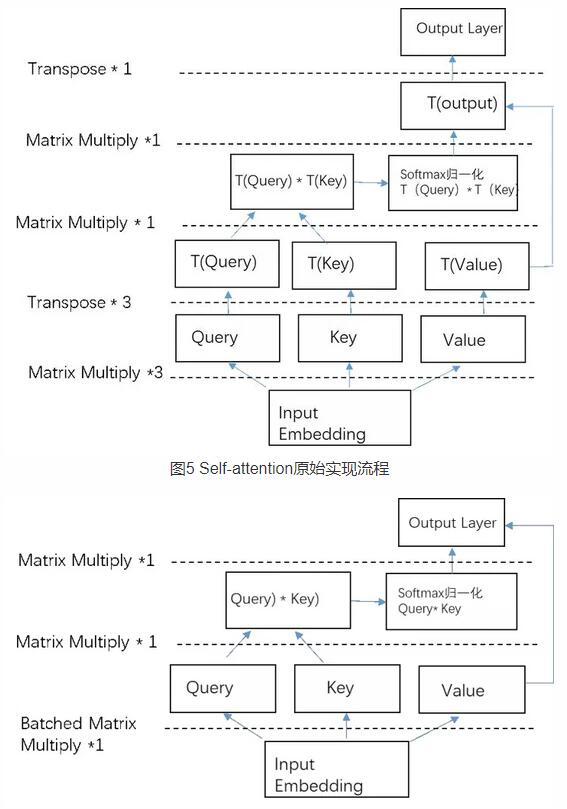
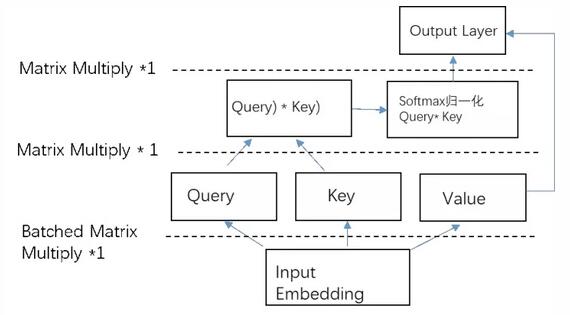
二者對比,可以明顯看出,優化后減少了4次transpose操作,也就是減少了內存訪問的開銷,同時對于矩陣乘法,調用批量矩陣乘法替代單個矩陣乘法操作,效率更高。
- Intrinsic指令集優化,例如在CPU平臺使用合適的向量化指令AVX512以及專門針對AI的VNNI指令等;
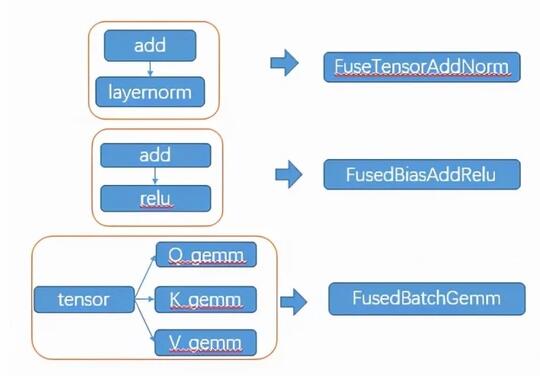
- 算子融合,以transformer為例,每一層包含大量的零散算子,包括self-Attention,GELU激活函數,歸一化Layer Normalization算子等多個零散算子,為了減少數據訪問開銷,將多個算子進行融合,實現新的GPU kernel。通過算子合并,算子數量減少約90%,模型涉及內存搬移的操作去除率100%,90%的時間集中在核心計算的kernel launcher。如圖7所示。
4.2 模型壓縮
模型壓縮是提升推理性能的另一個有效手段,主要是指在算法層面上的模型優化,保證精度的前提下,通過合理的降低模型結構或者參數量,從而實現減少整個模型計算量的目的。
模型壓縮的主要作用有:
- 簡化模型結構,降低計算復雜度,提升推理速度
- 減少模型參數和模型尺寸,降低對內存的占用。
宏觀上來講,當前的優化平臺支持的模型壓縮方法有模型蒸餾,模型剪枝,低精度量化等。
4.2.1 模型蒸餾
模型蒸餾采用的是遷移學習,通過預先訓練好的復雜模型(Teacher model)的輸出作為監督信號去訓練另外一個簡單的學生網絡(Student Model),從而實現對模型的簡化,減少模型參數。模型蒸餾普遍性很強,可有效提升小模型準確率,但是調參相對困難,主要的核心的問題包括,如何選擇特征層如何設計損失函數,學生模型的設計和數據集的選擇等等。圖8是我們壓縮框架中實現的對Transformer的decoder模型的蒸餾實現。
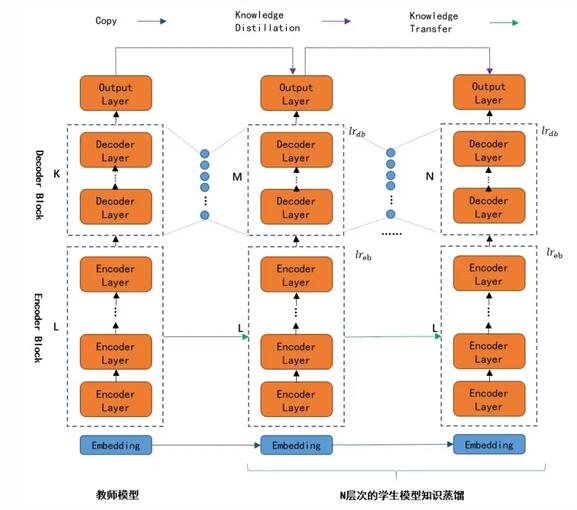
總損失函數構成:
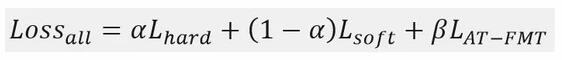
其中α和β分別表示相應的損失值權重系數,α∈(0,1],β∈R,Lsoft是 Teacher網絡的輸出與Student網絡模型輸出的損失值,Lhard - 訓練數據語料真實標簽與Student網絡模型輸出的損失值,LAT_FMT - Teacher和Student網絡模型的Decoder 的中間輸出內容損失值,采用逐級分層蒸餾的方法,最終推理速度加速比達到2倍,精度損失BLEU值在可接受范圍內(4%)。
4.2.2 低精度量化
低精度量化更多是從計算機硬件的設計角度,修改數據類型,降低數據精度,從而進行加速,依賴于硬件實現。量化的方式也包含多種,訓練后量化(PTQ post training quantization),訓練時量化(QAT,quantization aware traning)等。
目前我們優化平臺支持float16和int8,其中int8量化只支持PTQ方式,一般情況下,為了保證模型精度,采用int8量化需要對量化后的模型校準,校準方式實現依賴于復雜的數學算法,目前較常用的是KL散度,對于CV模型,精度損失可接受。對于基于Transformer的NLP模型,精度損失較大,我們目前只支持GPU平臺的float16實現。相比于float32,存儲空間和帶寬減半,精度幾乎無損失,吞吐提升可達3倍。
4.2.3 模型剪枝
剪枝的主要思想是將權重矩陣中相對“不重要”的權值剔除,然后再對網絡進行微調;方法簡單,壓縮效果可控,但是在剪枝粒度和方法選擇需要認為定義規則,而且非結構化的剪枝效果需要依賴于硬件平臺實現。模型剪枝在計算機視覺領域廣泛使用,并取得了不錯的效果。
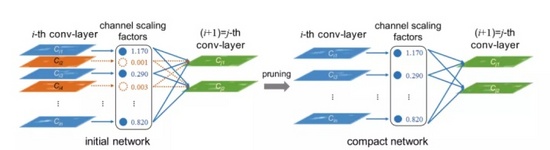
圖9舉例實現了一種典型的結構化剪枝的方法[4]。我們針對CV模型,在原始模型中加入batch_normal層,對batch_normal的參考論文2:ChannelPruning for Accelerating Very Deep Neural Networks論文中提出利用channel進行剪枝,實驗如下:在超分辨率的實驗中,考慮在原始模型中加入batch_normal層,然后對batch_nomal的α值做正則化,最后利用該值作為依據進行剪枝,對訓練好的模型中的batch_normal層的參數α進行分析,針對不同的卷積模型應用同樣的方式,發現有些模型有近一半的參數在1e-5數量級,此外同一層中的分布方差極小,據此對模型進行通道級別的剪枝并進行fine tune訓練,剪枝效果明顯,模型大小減少到原來的1/4,精度不變的前提下,加速比可達4倍。而對于yolov3模型,大部分參數差異不大(MAP降低2%),可剪掉的有限,所以為了保持精度,參數量減半,加速比1.5x左右。
4.3 接口設計
模型優化平臺采用即插即用的模塊化設計,可無縫對接模型訓練平臺,模型發布平臺等。
- 訓練平臺的調用和反饋:無縫對接訓練平臺,python接口調用或者web服務接口;如果需要重新訓練,向訓練平臺申請接口;
- 優化結果的接口提供:支持*.pb格式的模型輸出;
具體使用方式如圖10和圖11所示。
圖11給出了模型壓縮模塊的調用方式。
五、優化成果
以實際應用機器翻譯的Transformer模型為例,所測試平臺為CPU: Intel(R) Xeon(R) Silver 4210CPU @ 2.20GHz; GPU:Nvidia T4,以固定算例的平均響應延遲為測試數據,優化后和優化前的加速比如下圖12所示。
其中,原始性能基于tensorflow1.14為測試基準,在GPU平臺框架層優化和編譯運行時等多層優化實現,圖13是Transformer翻譯模型基于T4平臺使用模型壓縮和高性能算子庫優化之后的對比結果,圖中給出的是token長度為64,不同batch大小時的延遲和吞吐提升比例,實際中token越大,float16的優勢越明顯。
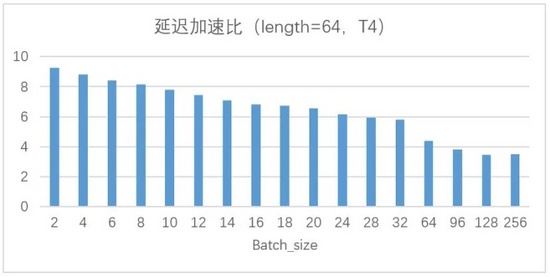
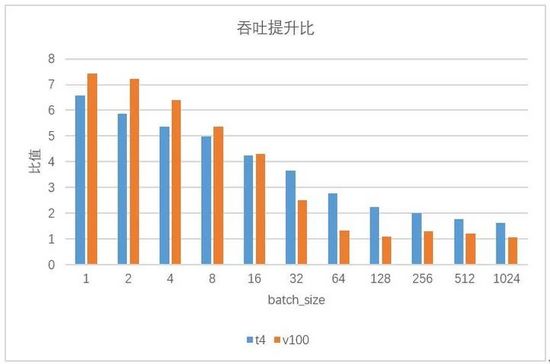
基于CPU硬件平臺,針對CV和NLP模型(例如yolov3,bert和albert等),也取得了不錯的優化效果,延遲加速比最高達到5倍以上。
六、未來展望
AI優化的潛力和需求很大,因為AI理論和模型的日益完善,應用場景對模型精度等推理服務質量的更高要求,必然使得模型結構和計算復雜度越來越高,對推理服務的性能需求只會有增無減。從成本和效率多個角度考慮,自動優化是必然趨勢,并且業界也都陸續開展了相關研究,取得了一些進展。
依舊從兩方面來看,同樣是基于自動化優化這個大方向,算子優化等系統級優化最終都會通過tvm等AI編譯器實現,而模型壓縮則側重于使用AutoML的思想,基于當前平臺和實際需求,通過結構搜索找到符合要求的最簡化的網絡。當然,當前的蒸餾,剪枝等傳統壓縮方法也可以跟AutoML的思想相結合,同樣能夠高效地實現壓縮效果。
因此,我們的自動化優化平臺也正是基于自動化優化的思路,綜合考慮業務場景需求,參考業界更先進的優化技術,為旅游場景的AI模型帶來更加高效的優化方案,推動AI技術在旅游業務更好落地。






























