













看 Serverless Task 如何解決任務調度&可觀測性中的問題
一、任務調度
任務調度多指系統根據當前負載情況,將不同任務放到合適的計算資源中去執行的相關操作。一個完善的調度系統往往需要平衡不同特點的任務間的隔離以及效率最優這兩個需求。函數計算異步任務采用了獨立隊列模型及自動負載均衡策略,具備在不影響處理性能的前提下進行多租隔離的能力。
Serverless Task 任務調度模型
當用戶提交一次任務后,系統會將該任務轉換為一條消息,并通過異步下發的方式放入到內部隊列中。一條消息的處理流程如下圖所示:
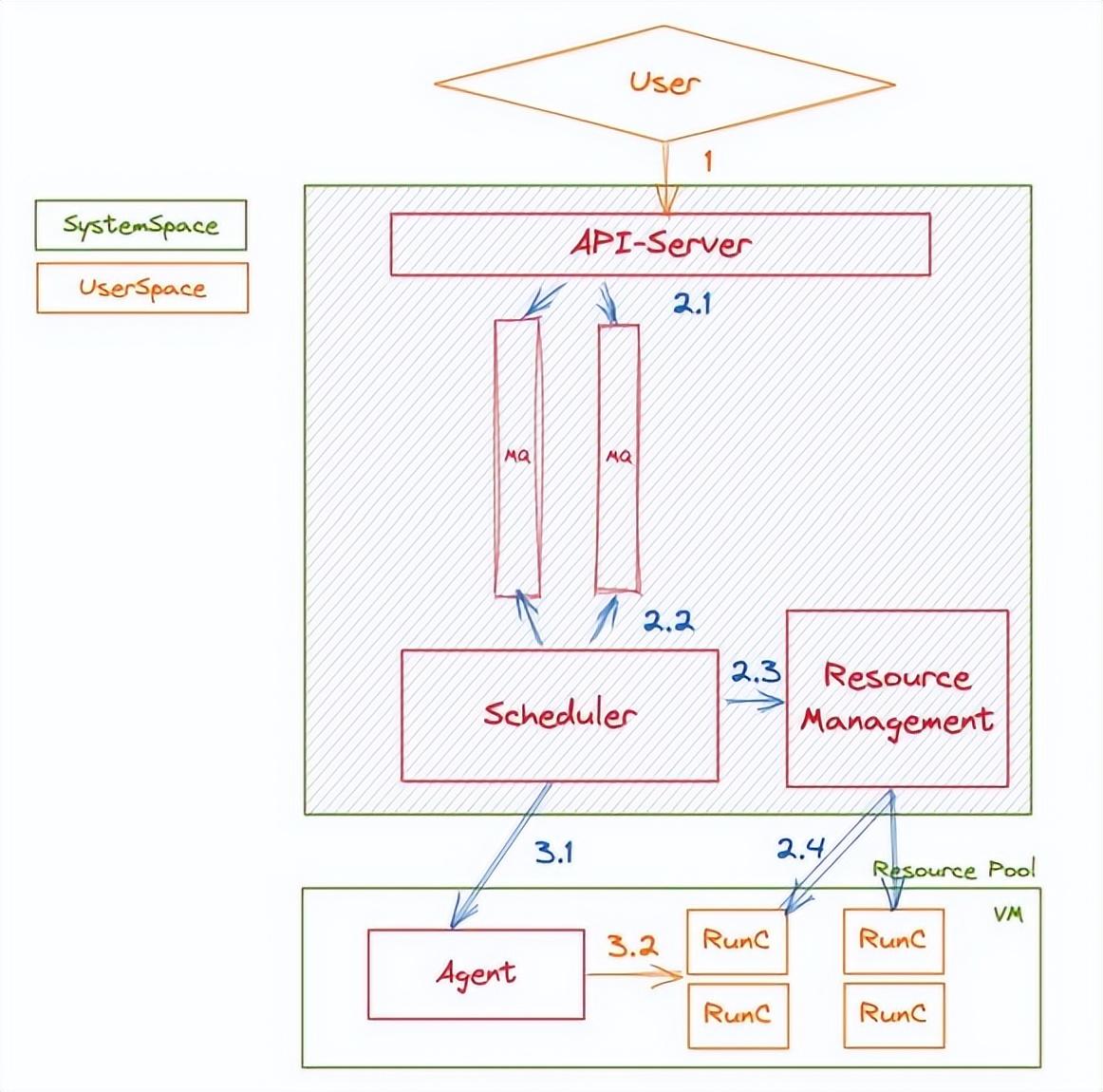
圖 1
整個系統在任務調度方面的多租隔離及消息積壓控制方面主要依賴的是 Scheduler 對于隊列的消費及控制。我們事先會為每一位用戶劃分一個賬號級別的隊列,該用戶的所有函數的異步調用(包括任務調用)會共享該隊列。
這樣的模型結構會保證每個用戶的異步執行請求(包括任務調用)均不會受到其他用戶的調用情況的影響。但是在一些大規模應用場景,如一個用戶的函數很多,并且每個函數的調用量都很大的情況下,所有的異步消息共用一個隊列難免造成調用間的相互影響。部分長尾調用可能會過多的消耗隊列的資源,導致其他函數的執行出現饑餓的現象。
為了避免這種情況影響重要函數的執行,函數計算提供了更細力度的隊列 - 函數級別的隊列。可以通過對每個不同函數設置單獨的隊列,確保高優先級函數的消費情況不會受同賬號下的其他函數執行的影響。隊列間的關系如下圖所示:
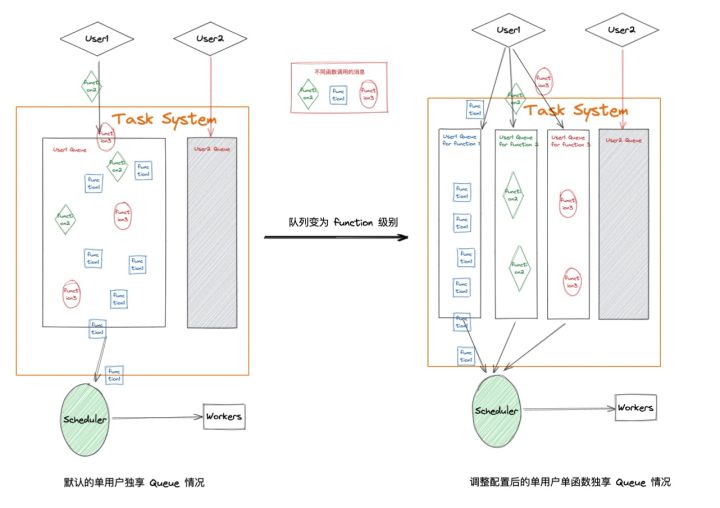
圖 2
典型的應用場景
假設某用戶 A 具有 2 個不同的任務函數。其中一個任務 A 由于下游服務的限制,需要一個消息一個消息的執行;而另外一個任務 B 是大并發任務,并且希望盡快執行完。在默認模式下,任務 A 和 B 共享同一個用戶隊列;這時會出現如下場景:任務 A 由于具有并發度限制,函數計算側會對整個任務隊列進行出隊速率控制。這就導致了任務 B 的任務遲遲無法出隊。
而當任務 A 執行完后,任務 B 得到了出隊機會,此時并發度升高,任務 B 的消息搶占了資源池進行執行,任務 A 又變得難以出隊,很長時間也無法開始一次執行。這樣的結果就是無論 A 還是 B 都受到了對方業務的嚴重干擾。
當進行隊列調整后,任務 A 和 B 分別獨占隊列。在這種情況下任務 A 和 B 的消費速度不受對方影響,都可以達到自身的訴求。
目前 Serverless Task 提供了任務積壓大盤,您可以在任務界面獲取目前已經積壓的任務數,綜合分析是否需要開啟函數的獨占隊列。
Serverless Task 任務隊列負載均衡模型
上面介紹了如何通過函數級別隊列來避免出現 “Noisy Neighbour” 問題。但是在一些場景下,如果任務的并發量級過大,即便對該任務劃分了單隊列,也會導致任務的積壓。這個問題的解決需要引入 Serverless Task 的負載均衡策略。
函數計算的任務處理模塊具有 Partition 的概念。每個用戶默認屬于一個 Partition,負責該 Partition 的 Scheduler 會監聽用戶對應的任務隊列。當出現嚴重積壓時,我們會為用戶按照負載情況分配多個 Partition,并交由不同的 Scheduler 負責消費,來提升任務整體的消費速度。
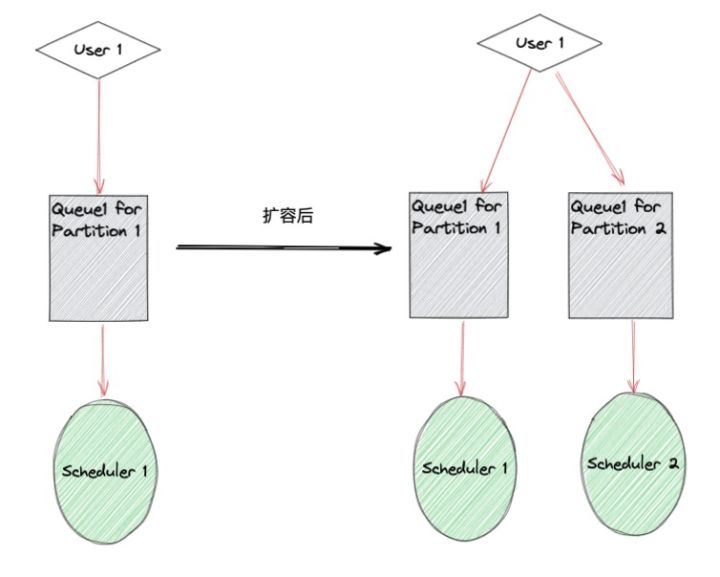
圖 3
可以看到,阿里云函數計算在任務隊列管理方面默認做到了多租及隔離的能力,可以適用于絕大多數場景。針對一些重負載、長執行、并發量大的場景,函數計算還支持橫向擴容,加快消費速度。在任務隔離方面,函數計算支持針對不同優先級的函數進行單獨隔離,避免出現 Noisy Neighbour 的問題。
二、可觀測性
任務的可觀測能力是任務系統必不可少的能力之一。強大的可觀測性將有助于業務方減少在任務運行的各個階段所需要額外進行的工作量。
開發階段:任務的在線調試能力、運行結果的 Debug 能力將直接影響業務上線進度;
業務常規運行階段:各種監控、流量情況的統計以及運行時日志將協助用戶快速了解業務的發展、變化,以及出現故障時的快速定位 & 處理;
階段性審計:任務的歷史記錄存儲及保留將為用戶提供良好的可追溯能力,可以根據歷史信息進行后續的業務規劃。
ServerlessTask 可觀測性支持 - 開發測試階段
業務的開發階段最主要的訴求就是快速調試并定位問題。在對該階段的支持中,ServerlessTask 提供了登錄實例及實時日志的能力。當代碼開發并上傳后,測試 - debug - 修改代碼 - 再次測試的流程可以全部在控制臺完成,極大的提高了研發效率。如果有需要性能調試、第三方 Binary 調試(如音視頻處理領域的 FFmpeg 調試)等可以借助登錄實例功能完成。操作流程如下圖所示:
選擇想登錄實例的任務,點擊實例鏈接。

會進入到實例監控頁面,點擊右上角的登錄實例功能,即可登錄到對應的實例上。
ServerlessTask 可觀測性支持 - 業務上線后運行階段
當業務上線后,經常容易出現因容量預估不足導致下游系統無法承載壓力,導致故障。因此 ServerlessTask 提供了運行時指標,即一段時間內的任務提交數、完成數及執行情況。用戶可以根據這張指標圖快速了解當前業務的負載情況。當用戶任務的下游消費較慢,可能造成任務積壓,這種情況也很容易在指標圖中反映出,進而快速做出相應的反應。目前 ServerlessTask 所提供的相關指標如下:
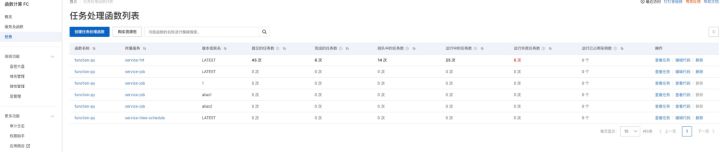
任務監控大盤提供以下任務監控數據:
監控指標 | 說明 |
提交的任務數 | 在過去 1 分鐘內所提交的任務總數,包括運行中的、已完成的及未出隊的數量。 |
完成的任務數 | 在過去 1 分鐘內提交的任務所完成的任務數,包括執行成功或失敗的。 |
排隊中的任務數 | 在過去 1 分鐘內提交的任務,還在排隊中的數量。如果該數量不為 0,則說明任務有積壓。 |
運行中的任務數 | 在過去 1 分鐘內提交的任務處于運行中的任務數。 |
運行失敗任務數 | 在過去 1 分鐘內提交的任務處于運行失敗的任務數。 |
運行已占用實例數 | 在過去 1 分鐘內提交的任務處于運行成功的任務數。 |
在快速定位問題方面,函數計算支持實時查看函數日志及實例指標。您可以進入到任務的列表頁面,找到實際執行失敗的任務,進入日志頁面及實例頁面進行問題定位:
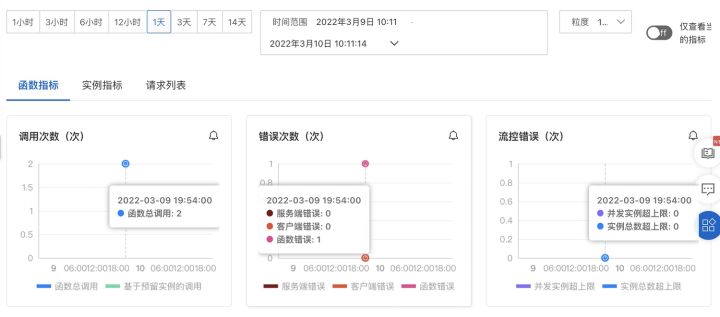
ServerlessTask 可觀測性支持 - 階段性審計
當線上任務運行一段時間后,往往需要進行一系列的階段性審計工作,比如上一周的執行總任務數,執行失敗的任務數及執行失敗的時間。目前除了控制臺以外,函數計算提供了豐富的 API 能力來進行任務的審計工作。主要包括以下幾方面能力:
根據狀態進行過濾,只查詢某一個狀態的執行;
根據觸發時間進行過濾,如查詢過去某一段時間內發起的任務;
根據任務名稱查詢。如果您的任務具有業務上下游的 TraceID,您可以在觸發任務時指定一個有意義的任務ID。后續可以根據 ID 前綴進行范圍查詢;
上面的幾個過濾方式可以組合,達到更便捷的需求。控制臺所支持的過濾條件如下圖所示:

更多參數內容可參考:
ListStatefulAsyncInvocation 。
ServerlessTask 可觀測性支持 - 死信隊列及業務補償
在消息領域,有一個非常重要的概念 - 死信隊列。當一些消息無法被消費時,這些消息往往需要存儲到一個地方,以便后續人為的介入處理,避免因未進行處理而造成業務損失。Serverless Task 也支持了這樣一類功能。您可以對 Serverless Task 設置目標功能;當任務執行失敗后,函數計算支持自動將執行失敗的上下文信息推送到消息隊列等消息服務中,以便后續處理。如果您的處理邏輯支持自動化,函數計算還支持將失敗任務的上下文信息推送回函數計算,執行一段您的自定義業務邏輯來實現業務補償。
您可以在異步調用配置頁面配置成功及失敗目標。

更多配置內容請參考:
PutFunctionAsyncInvokeConfig。
綜上所述,Serverless Task 所提供的可觀測能力可以有效支持任務全生命周期的監測需求。所有控制臺能力均可以使用開放 API 進行定制化開發,來滿足更多的需求。Serverless Task 的目標功能除了可以做到任務失敗補償以外,還可以作為 Event-Driven 模式的數據源,自動的將處理后的事件投遞到下游服務中。


























