













淺析容器運行時安全加固
隨著云計算的蓬勃發展,云原生的概念于2013年被提出,Pivotal 公司的 Matt Stine 在概念中提出了云原生的4個要點:DevOps、持續交付、微服務、容器。而在 2015 年 Google 主導成立了云原生計算基金會(CNCF),CNCF 也給出了對云原生(Cloud Native)的定義,其中包含三個方面:1)應用容器化;2)面向微服務架構;3)應用支持容器的編排調度。
隨著近幾年來云原生生態的不斷壯大,所有主流云計算供應商都加入了該基金會, CNCF 基金會中的會員以及容納的項目越來越多,原先的定義已經限制了云原生生態的發展,到了 2018 年 CNCF 為云原生進行了重新定位,同時指出云原生的代表技術包括容器、服務網格、微服務、不可變基礎設施和聲明式 API。圍繞這些概念、定義和代表技術,最為基礎的就是容器和微服務。在容器應用之前,相關的云計算的應用多數運行于虛擬機上,但虛擬機會有額外的資源浪費和維護成本,并且其啟動速度較慢。正是容器技術所具有的占用資源少、部署速度快和便于遷移等特點,助力了云原生生態的蓬勃發展,其中 Docker 和 Kubernetes 是企業容器運行時和容器編排的首要選擇。
而于此同時,如何保證云原生環境的安全性也在不斷受到挑戰。在云原生技術應用的過程中,大多數企業都遇到過不同程度的安全問題,無論是前兩年爆出的某著名車企的容器集群入侵事件,還是容器官方鏡像倉庫 Docker Hub 存在惡意鏡像,用戶在享受云原生相關技術便利的同時,也產生了極大的安全擔憂。而作為云原生的基石——容器的安全性更是重中之重,為了滿足云原生業務上對安全防護工具的全面性、便捷性以及性能上的要求,圍繞著容器運行時安全的多個內核安全特性也在不斷發展,本文將對近年來針對容器運行過程中的安全加固技術進行逐一介紹。(在本文中,若無特殊說明,容器指代 Docker 容器)
1、容器安全概述
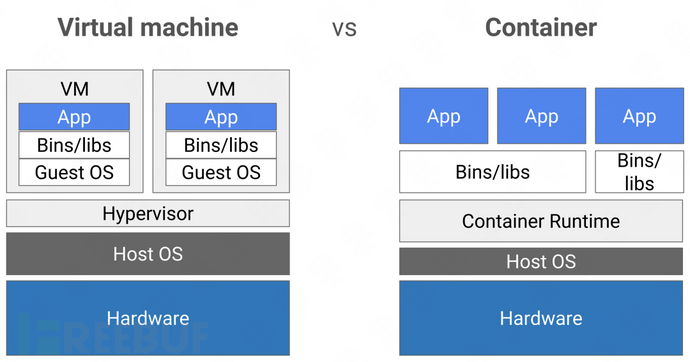
在實現云原生的主要技術中,容器作為支撐應用運行的重要載體,為應用的運行提供了隔離和封裝,成為云原生應用的基礎設施底座。與虛擬機不同的是,虛擬機模擬了硬件系統,每個虛擬機都運行在獨立的 Guest OS 上,而容器之間卻共享操作系統內核,并未實現完全的隔離。若虛擬化軟件存在缺陷,或宿主機內核被攻擊,將會造諸多的安全問題,包括隔離資源失效、容器逃逸等,影響宿主機上的其他容器甚至整個內網環境的安全(下圖展示了 VM 和容器在系統架構上的差異)。
據《Sysdig 2022 云原生安全和使用報告》顯示,超過75%的運行容器存在高危或嚴重漏洞、62%的容器被檢測出包含 shell 命令、76%的容器使用 root 權限運行。鑒于云原生的攻擊手段的獨特性, 安全組織 MITRE 的對抗戰術和技術知識庫(ATT&CK 框架)在2021年推出了專門針對容器的攻擊模型。云原生安全在近年來獲得了大量的關注。
Google 在其 GCP 上討論容器安全風險時,依據容器風險的來源,將其分為了三個方面:
- 基礎架構安全:主要是指容器管理平臺能夠提供的基本功能的安全。
- 軟件供應鏈安全:主要是指容器鏡像安全。
- 運行時安全:確保安全響應團隊能夠檢測到環境中運行的容器所面臨的安全威脅。
而 Google 的這個分類方法,其實也可以歸結抽象為對容器生命周期中三個過程的安全:
- 構建時安全:在容器鏡像構建過程中,分析構建鏡像時所使用的命令和配置參數,還原鏡像文件構建過程,掌握命令使用的敏感操作,以及分析鏡像文件是否包含密碼、令牌、密鑰和用戶機密信息等敏感信息。同時,分析鏡像的軟件組成,發現鏡像文件中包含的惡意文件、病毒和木馬,以及所使用的依賴庫和組件存在的安全漏洞,避免鏡像本身存在的安全風險。
- 部署時安全:分析鏡像無風險后,鏡像被提交至鏡像倉庫。在該階段,將檢查容器環境的鏡像倉庫配置,確保使用加密方式連接鏡像倉庫。當鏡像倉庫中新增鏡像或使用鏡像創建容器時,自動化校驗鏡像簽名或MD5值,確保鏡像來源可信且未被篡改,一旦發現鏡像來源不可信或被篡改,禁止使用該鏡像創建容器。
- 運行時安全:當確認鏡像安全后,進入到容器運行階段。該階段主要是是保證容器運行環境的安全,防止容器出現異常行為,這其中就包括主機環境配置安全、容器守護進程配置安全、容器應用的運行安全。
在容器生命周期的三個過程中,攻擊者往往是在前兩個階段部署相關的惡意代碼,在容器運行時對環境真正執行相關的攻擊指令。因此,容器運行時相比于其他兩個階段更直接、也更容易分析出環境中的惡意行為。與其他虛擬化技術類似,逃逸也是針對容器運行時存在的漏洞最為嚴重的攻擊利用行為。攻擊者可通過利用漏洞“逃逸”出自身擁有的權限范圍,實現對宿主機或者宿主機上其他容器的訪問,其中最為簡單的就是造成宿主機的資源耗盡,往往會直接危害底層宿主機和整個云原生系統的安全。根據風險所在層次的不同,可以進一步展開為:危險配置導致的容器安全風險、危險掛載導致的容器安全風險、相關程序漏洞導致的容器安全風險、內核漏洞導致的容器安全風險:
- 危險配置導致的容器安全風險:用戶可以通過修改容器環境配置或在啟動容器時指定參數來改變容器的相關約束,但如果用戶為一些不完全受控的容器配置了某些危險的配置參數,就為攻擊者提供了一定程度的可以攻擊利用的安全漏洞,例如未授權訪問帶來的容器安全風險,特權模式運行帶來的容器安全風險。
- 危險掛載導致的容器安全風險:將宿主機上的敏感文件或目錄掛載到容器內部,尤其是那些不完全受控的容器內部,往往也會帶來安全風險。這種掛載行為可以通過環境配置來設定,也可以在運行時進行動態掛載,因此這里單獨地歸為一類。隨著應用的逐漸深化,掛載操作變得愈加廣泛,甚至為了實現特定功能或方便操作,使用者會選擇將外部敏感資源或文件系統直接掛載入容器,由此而來的安全問題也呈現上升趨勢。例如:掛載 Docker Socket 引入的容器安全風險、掛載宿主機 procfs、sysfs 引入的容器安全問題等。
- 相關程序漏洞導致的容器安全風險:所謂相關程序漏洞,指的是那些參與到容器運行、管理的服務端以及客戶端程序自身存在的漏洞。例如,CVE-2019-5736、CVE-2021-30465、CVE-2020-15257等存在于 Container Daemon、runC 上的容器安全漏洞。
- 內核漏洞導致的容器安全風險:Linux 內核漏洞的危害之大、影響范圍之廣,使得它在各種攻防話題下都占有一席之地,特別是在容器環境中由于容器與宿主機共享了內核,攻擊者可以直接在容器中對內核漏洞進行利用攻擊。近年來,Linux 系統曝出過無數內核漏洞,例如最有名氣的漏洞之一——臟牛(CVE-2016-5195)漏洞也能用來進行容器逃逸。
安全容器的漏洞安全容器是為了解決內核共享問題導致的安全風險所研發的一種運行時技術,它為容器應用提供一個完整的操作系統執行環境(常常是 Linux ABI),將應用的執行環境與宿主機操作系統隔離開,避免應用直接訪問主機資源,從而可以在容器主機之間或容器之間提供額外的保護。例如,Kata Containers 就是為每一個容器運行一個獨立虛擬機,從而避免其與宿主機共享內核。無論是理論上,還是實踐中,安全容器都具有非常高的安全性。然而在 2020 年 Black Hat 北美會議上,Yuval Avrahami 分享了利用多個漏洞成功從 Kata containers 逃逸的議題,安全容器首次被發現存在逃逸可能性,他使用發現的三個漏洞(CVE-2020-2023、CVE-2020-2025 和 CVE-2020-2026)組成漏洞利用鏈先后進行容器逃逸和虛擬機逃逸,成功從容器內部逃逸到宿主機上。
為緩解甚至消除這些容器運行時的安全隱患,社區提供了一系列強化配置并且多年來也研發了相關的加固工具。CIS 發布的 Docker 基線已成為 Linux 主機配置和 Docker 主機加固的最佳實踐。同樣,CIS也發布了 Kubernetes 基線,傳統的漏洞掃描工具、獨立的容器安全產品(如 Aqua Security 和 NeuVector)和私有維護人員已經在 GitHub 上發布了腳本,可實現自動化的 Kubernetes 安全檢查。接下來,我們將著重介紹一些行而有效的容器運行時的安全加固技術以及近年來的一些發展。
2、容器運行時安全加固
運行時安全是在容器運行時通過檢測和防止惡意行為來提供主動保護,可以說是整個容器生命周期中的最后一道安全屏障。其核心思想就是監控并限制容器中高危的行為,縮小容器進程的能力和權限。容器本身是利用了 Namespace 和 Cgroup 技術,將容器和宿主機之間的資源進行了隔離并加以限制。
NamespaceNamespace 即命名空間,也被稱為名稱空間,這是 Linux 提供的一種內核級別的環境隔離功能,它的主要用途是對容器提供資源的訪問隔離,這些資源包括文件系統掛載 、主機名和域名、進程間通信 、進程訪問、網絡隔離、用戶和組隔離等。容器充分利用了 Namespace 的技術,使其達到盡可能地隔離容器之間以及對宿主機的影響。
CgroupCgroup全稱為 Control Group,它也是容器的重要特性。如果說 Namespace 是用于隔離,那么 Cgroup 則是限制容器對于資源的占用,如CPU、內存、磁盤 I/O 等。這個特性可以有效地避免某個容器因為被 DDOS 攻擊或者自身程序的問題導致對資源的不斷占用,并最終影響到宿主機及上面運行的其他容器,出現“雪崩”的災難 。
雖然這種隔離限制從資源層面實現了對容器和宿主機之間的環境獨立,宿主機的資源對容器不再可見,但是這種方式并沒有達到真正意義上的安全隔離。由于容器的內核與宿主內核共享,一旦容器中通過惡意行為進行一些高危的操作權限,或者是利用內核漏洞,往往就可以突破這種資源上的隔離,造成容器逃逸,重新危害到宿主機及上面運行的其他容器。
目前 Linux 內核提供了一系列的安全能力可以對這些攻擊行為進行有效防護。結合內核安全技術的能力,這些技術的作用范圍可以簡單地分為兩種:一種是限制是限制行為本身,另一種則是限制行為作用的對象范圍。首先我們介紹如果有效切斷這些造成逃逸的惡意行為,如何去限制發起行為的能力。
2.1 Capabilities 和 Seccomp
在 Linux 系統中 Root 用戶作為超級用戶擁有全部的操作權限,以 Root 身份運行容器,相當于將打開容器資源限制大門的鑰匙交給了容器自身,這是十分危險的。但如果以非 Root 身份在后臺運行容器的話,由于缺少權限容器中的應用進程容易處處受限。為了適應這種復雜的權限需求,Linux 細化了 Root 權限的管控能力,從 2.2 版本起 Linux 內核能夠進一步將超級用戶的權限分解為細顆粒度的單元,這些單元稱為 Capabilities。例如,CAP_CHOWN 允許用戶對文件的 UID 和 GID 進行任意修改,即執行 chown 命令。
*Capabilities 詳細信息可通過 Linux Programmer's Manual 進行查看:https://man7.org/linux/man-pages/man7/capabilities.7.html
幾乎所有與超級用戶相關的特權都被分解成了單獨的 Capability,可以分別啟用或禁用。這種系統權限機制提供了細粒度的操作權限的訪問控制,控制容器運行所需的 Capabilities 范圍,可以有效切斷容器中攻擊者的行為操作。即使容器攻擊者取得了 Root 權限,由于不能獲得主機的完全的操作權限,也進一步限制了攻擊對宿主機的破壞。Docker 在容器管理中默認限制了容器的 Capabilities, 其中僅開啟如下部分:
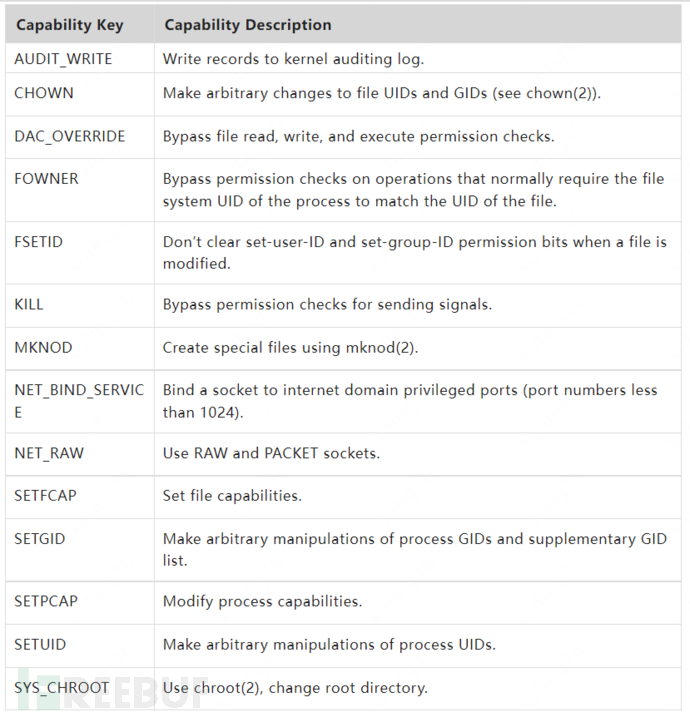
但是基于 Capabilities 的權限訪問管理,有時候并不能很好地限制住容器的操作權限。例如,SYS_ADMIN 管理了 mount,umount,pivot_root,swapon,swapoff,sethostname,setdomainname 等等系統調用的訪問權限,一旦應用進程因為需要進行 sethostname 這樣的操作而在容器中開啟了 SYS_ADMIN 組的 Capabilities,那么也就讓容器具有了 mount 這類可以掛載系統資源的操作權限,導致容器存在逃逸的風險。Seccomp(Secure Computing Mode)同樣也是一種 Linux 內核提供的安全特性,它可以以白名單或黑名單的方式限制進程進行系統調用。相對于 Capabilities 將系統調用以組的形式進行分類管理,Seccomp 是對系統調用更細粒度的單點控制。
Seccomp 首次于內核 2.6.12 版合入 Linux 主線。早期的 Seccomp 只支持過濾使用四個系統調用:read,write,_exit,sigreturn。在這種安全模式下,除了已打開的文件描述符和允許的四種系統調用,一旦進程嘗試訪問其他系統調用,內核就會使用 SIGKILL 或 SIGSYS 信號來終止該進程。由于這種限制太過于嚴格,在實際應用中作用并不大。
為了解決此問題,2012 年的內核 3.5 版本引入了一種新的 Seccomp 模式,叫做 SECCOMP_MODE_FILTER。這個功能允許用戶使用可配置的策略過濾系統調用,該策略使用 Berkeley Packet Filter(BPF)規則實現,從而使 Seccomp 可以對任意的系統調用及其參數(僅常數,無法指針解引用)進行過濾。因此使用這種模式的的 Seccomp 也被稱之為 Seccomp-BPF。而程序在 fork/clone 或 execve 時,BPF 過濾規則是可以從父進程繼承到子進程,因此 Seccomp 機制可以很好地用于限制容器的權限。
seccomp 設定的系統調用過濾規則能傳遞給子程序的關鍵在于 prctl 系統調用:
prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0);
prctl 的 No New Privileges Flag 可以避免類似 execve 的系統調用授予父進程沒有的權限。詳見:https://man7.org/linux/man-pages/man2/prctl.2.html
目前 docker 在運行容器時會使用默認配置,其中禁止了約 44 個系統調用,當然也可以使用 --security-opt 選項將默認的配置文件替換為自定義的配置文件。
*docker默認配置詳見:https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
在 5.0 版本內核中又加入了新的 seccomp-unotify 模式。Seccomp-BPF 模式對系統調用的判斷過程是由加載到內核的 BPF 程序來完成的,而 Seccomp-unotify 機制可以將這一判斷過程移交給另一個用戶態的進程來完成。同時,利用該模式 Filter 進程不僅可以檢測系統調用的參數,還可以對指針參數進行解引用,查看指針所指向的內存。這就方便了判斷程序對調用行為的分析判斷,大大擴充了 Seccomp 機制的過濾能力。作為一種新增特性,Seccomp-unotify 模式更為強大的過濾能力相信后續會在容器安全加固中擁有比較大的使用空間。
需要注意的是,這種位于 syscall 入口處的檢查判斷是存在 TOCTTOU(Time Of Check To Time Of Use)風險的——風險就在于此時的一些內存數據依舊保存在用戶空間,從入口檢測到實際使用還需要一定的時間,攻擊者完全可以在這段時間內通過其他并發線程對用戶空間上的數據進行修改。因此 Seccomp 以及 Capabilities 的優勢不在于限制容器中的進程能否通過 syscall 去訪問一些特定的資源,而在于直接去排除容器中進程發起這類 syscall 行為的能力。接下來我們也將討論如何更有效地限制這些行為的作用對象,以及阻斷逃逸后的攻擊者對宿主機中其他資源的訪問。
2.2 MAC 和 LSM
Namespace 機制讓容器和宿主機之間實現了資源上的隔離,讓宿主機上的其他資源對容器不再可見。但是這種虛擬隔離并沒有限制容器中進程的訪問權限,資源訪問權限的管理卻是由 Linux DAC(Discretionary Access Control,自主訪問控制,以下簡稱 DAC)機制來完成的,它主要依賴的進程的 uid 和 gid 來進行管理。因此一旦容器中的攻擊者突破了 Namespace 的界限,往往就可以對容器外的資源進行訪問。而解決這一安全風險的關鍵就是——強制訪問控制(Mandatory Access Control——MAC,以下簡稱MAC)。其中最為熟知的 MAC 訪問控制安全模塊,就是 SELinux、AppArmor等。
SELinux
早期的操作系統幾乎沒有考慮安全問題,系統中只有一個用戶并且可以訪問系統任何資源。而隨著多用戶系統的發展,為了有效限制用戶的訪問權限,確保用戶只能訪問他們需要的資源,出現了訪問控制機制來增強安全性。其中主要的訪問控制就是 DAC 機制。DAC 通常允許授權用戶自主改變客體的訪問控制屬性,這樣就可指定其他用戶是否有權訪問該客體。然而,DAC 機制只約束了用戶、同用戶組內的用戶、其他用戶對文件的可讀、可寫、可執行權限,這對系統的保護作用非常有限。
Linux 系統中所有內容都是以文件的形式保存和管理的,即一切皆文件。
為了克服這種脆弱性,出現了 MAC 機制,其基本原理是利用配置的安全策略來控制對客體的訪問,且這種訪問不被單個程序和用戶所影響。SELinux(Security-Enhanced Linux)是由美國國家安全局(NSA)聯合其他安全機構(比如 SCC 公司)共同開發的一套 MAC 安全認證機制,并在 Linux 2.6 版本后集成在內核中。SELinux 規定了每個對象(程序、文件和進程等)都有一個安全上下文(Security Context),它依附于每個對象身上,包含了許多重要的信息,包括 SELinux 用戶(不同于Linux系統的用戶)、角色(Role)、類型(Type)和級別(Security Level)等。
管理員可以通過定制安全策略(Security Policy)來定義這些安全上下文,從而定義哪種對象具有什么權限。當一個對象需要執行某個操作時,系統會按照該對象以及該對象要操作的對象的安全上下文所定制的安全策略來檢查相對應的權限。如果全部權限都符合,系統就會允許該操作,否則將阻斷這個操作。
SELinux 與 DAC
在啟用了 SELinux 的 Linux 操作系統中,SELinux 并不是取代傳統的 DAC 機制。當某個對象需要執行某個操作時,需要先通過 DAC 機制的檢測,再由 SELinux 定制的安全策略來檢測。如果 DAC 規則拒絕訪問,則根本無需使用 SELinux 策略。只有通過 DAC 和 SELinux 的雙重權限檢查確認之后,才能執行操作。
SELinux 其中一個重要概念就是 TE(Type Enforcement,類型強制),其原理是將權限與程序的上下文結合在一起,而不是與執行程序的用戶,這是目前使用最為廣泛的 MAC 檢測機制。
SELinux 支持兩種 MAC 檢測機制
Type Enforcement (TE)
顧名思義,Type Enforcement 是根據安全上下文中的 type 進行權限審查,審查主體的 type 對客體的 type 的某種操作是否具有訪問權限,主要集中于程序訪問控制決策。
Multi-Level Security (MLS)
多層安全機制,是基于Bell-La Padula (BLP) 模型,將主體和客體定義成多層次的安全等級,不同安全等級之間有相關的訪問約束,常見的訪問約束是 "no write down" 和 "no read up"。它是根據安全上下文中的最后一個字段 label 進行確認的。
它允許管理者可以基于程序的功能和安全屬性,加上用戶要完成任務所需的訪問權作出訪問決策,將程序限制到功能合適、權限最小化的程度。并且這個安全策略采用的是白名單方法,這意味著程序在運行過程中只能被授予策略中明確允許的訪問權限。因此,即使某個程序出現了故障或被攻擊,但整個系統的安全并不會受到威脅。
容器與 SELinux
容器在默認配置下是沒有開啟 SELinux 功能的,需要管理者修改 Docker 守護進程中的參數配置進行開啟。
如何為容器啟用 SELinux:
1.在 dockerd 啟動時加上 --selinux-enabled 參數,在 CentOS上 可以修改 systemd 配置文件 docker.service
2.在/etc/docker/daemon.json配置文件中加上:{ "selinux-enabled": true } 然后重啟 docker 服務
開啟 SELinux 后,依據自帶的默認策略,啟動容器中的進程一般會打上 container_t 的標簽,容器具備操作權限的資源則一般會打上 container_file_t 的標簽。(docker 每創建一個容器,容器中對象的安全上下文還會分配一個額外的信息—— Category,以此來確保容器之間的訪問隔離。簡單點說是說一個容器A中的進程是無法訪問容器B的資源)
這樣容器中的進程就無法對容器中的一些特殊資源進行修改,甚至是逃逸后這些進程依舊無法對宿主機的其他資源進行訪問。
需要注意的是,docker 在啟動過程中可以通過 -v 參數額外掛載一些宿主機上的目錄/文件。如果直接掛載在容器中進行訪問時,操作是會被 SELinux 阻止:
# docker run -it --rm -v /tmp/HostDIR:/host/tmp/HostDIR ubuntu root@f724f5437895:/# ls -lZ /host/tmp/ total 0 drwxr-xr-x. 2 root root unconfined_u:object_r:user_tmp_t:s0 22 Oct 12 10:05 HostDIR root@f724f5437895:/# ls -lZ /host/tmp/HostDIR/ ls: cannot open directory '/host/tmp/HostDIR/': Permission denied
需要通過加上后綴 :z 或者 :Z 來改變掛載資源的上下文的標簽。兩者存在區別,具體可以查看 Docker ,詳見:Docshttps://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container---volumes-from
# docker run -it --rm -v /tmp/HostDIR:/host/tmp/HostDIR:Z ubuntu root@62e115c4771c:/# ls -l /host/tmp/ total 0 drwxr-xr-x. 2 root root 22 Oct 12 10:05 HostDIR root@62e115c4771c:/# ls -lZ /host/tmp/ total 0 drwxr-xr-x. 2 root root system_u:object_r:container_file_t:s0:c132,c528 22 Oct 12 10:05 HostDIR root@62e115c4771c:/# ls -lZ /host/tmp/HostDIR/ total 4 -rw-r--r--. 1 root root system_u:object_r:container_file_t:s0:c132,c528 18 Oct 12 10:05 HostFile root@62e115c4771c:/# cat /host/tmp/HostDIR/HostFile This is a host file
近年來比較突出的利用 procfs/sysfs 中的特殊文件進行容器逃逸的方法,在利用 SELinux 對容器環境進行加固后,是可以進行有效阻止。以利用 /proc/sys/kernel/modprobe 進行容器逃逸為例,作為宿主機相關的文件 modprobe 被配置了 usermodehelper_t 的標簽,對于容器中的進程 modprobe 文件是沒有寫權限的,也就阻止了攻擊者進行逃逸的操作。
利用 /proc/sys/kernel/modprobe 進行容器逃逸的原理
/proc/sys/kernel/modprobe 用于設置自動加載內核模塊相關 usermode helper 的完成路徑,默認是 /sbin/modprobe,Linux內核安裝或卸載模塊的時候就會觸發這個被指定的 usermode helper。
在 Documentation for /proc/sys/kernel/ - The Linux Kernel documentation中也提到:“if userspace passes an unknown filesystem type to mount(), then the kernel will automatically request the corresponding filesystem module by executing this usermode helper.”。
也就是說執行一個未知的文件類型,內核也會去調用這個指定的程序。
攻擊者就可以替換原有的 modprobe_path 為惡意代碼的地址,之后執行一個未知文件類型,內核就會去調用惡意文件,執行惡意代碼。
但是這個攻擊的利用需要一定的權限,在 docker 中默認 /proc/sys/kernel/modprobe 是不可寫入的,需要對 /proc/sys 以 rw 方式 remount 才可以修改文件內容,這就需要被攻擊的容器環境具有 SYS_ADMIN 的權限。
*Documentation for /proc/sys/kernel/ - The Linux Kernel documentation 原文詳見:https://www.kernel.org/doc/html/latest/admin-guide/sysctl/kernel.html#modprobe
AppArmor
另一個用于此目的的類似的 Linux 內核安全模塊是 AppArmor。AppArmor 得到了開發 Linux Ubuntu 發行版的母公司 Canonical 的支持,其目的是希望開發一個比 SELinux 更簡單易用的訪問控制模塊。
RedHat 旗下的所有 Linux 發行版都預裝或提供 SELinux 設置,包括 RHEL、CentOS 和 Fedora,而 AppArmor 安裝在 Debian、Ubuntu、它們的衍生發行版以及 SUSE Enterprise Server 和 OpenSUSE 發行版上。
與 SELinux 不同,AppArmor 是作為 DAC 機制的補充,用于限制指定目標程序的資源訪問權限,例如是否允許讀/寫某個特定的目錄/文件、打開/讀/寫網絡端口以及是否具備某類 Linux Capabilities 等。為了簡單易用,Apparmor使用文件名(路徑名)作為安全標簽,而SELinux使用文件的 inode 作為安全標簽。在文件系統中,只有inode才具有唯一性,因此相比于 SELinux,通過改名等方式,AppArmor 存在被繞過的風險。
Docker 本身也提供了對于容器環境的默認 AppArmor 配置,啟動容器時系統會自動應用 docker-default 安全配置文件,配置文件通過 template 模板生成,(Docker 也設計了針對 docker 守護進程的配置文件 contrib/apparmor,但是當前并沒有包含在 docker 相關發行包中),也可以通過 --security-opt apparmor=<profile-name> 命令行選項指定自定義的配置文件。
*template 模板詳見:https://github.com/moby/moby/blob/master/profiles/apparmor/template.go,Docker 守護進程的配置文件 contrib/apparmor詳見:https://github.com/moby/moby/tree/master/contrib/apparmor
管理者可以通過檢查進程的 /proc/<pid>/attr/current 文件來查看對應進程是否配置了相應的 AppArmor 配置文件:
通過配置 AppArmor 同樣可以阻斷之前提到的逃逸攻擊,例如 docker-default 配置中不僅限制了容器進程對 procfs/sysfs 等敏感文件/目錄的寫權限,并且限制容器中進程進行 mount 操作。(利用 AppArmor 的配置文件同樣可以限制容器 Capabilities 權限,并配置 Seccomp 功能)
LSM 的現狀
不管是 SELinux 還是 AppArmor 其實都是 Linux 安全模塊(Linux Security Module,以下簡稱 LSM),都是基于 LSM 框架—— Linux 操作系統內核提供的一種安全機制,來完成對進程對 Linux 資源訪問權限的判斷(Capabilities 其實也是一個 LSM 模塊)。LSM 雖然被稱作“模塊”,但不同于 LKM(Loadable Kernel Module),這些擴展并不是可加載的內核模塊,而是和內核代碼一起編譯在內核文件(vmlinuz)中,并且只能在系統啟動時就進行初始化。
LSM 與 SELinux
在2001年的 Linux Kernel 峰會上,NSA 代表建議在 Linux Kernel 2.5 中加入 SELinux。然而,這一提議遭到了 Linus Torvalds 的拒絕。一方面,SELinux 并不是惟一用于增強 Linux 安全性的安全子系統;另一方面,并不是所有的開發人員都認為 SELinux 是最佳解決方案。最終 SELinux 沒能加入到 Linux Kernel 2.5,取而代之的是 Linux Security Module 的開發被提上日程。
LSM 子系統自提出后開發了近3年,并終于在 Linux Kernel 2.6正式加入到內核中,隨之應運而生了大量LSM,比如 SELinux、SMACK、AppArmor、TOMOYO、Yama、loadPin、SetSafeID、Lockdown 等。
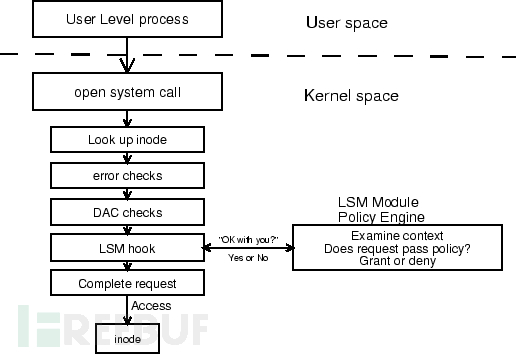
從上圖可以看出 LSM 框架在Linux安全體系中所處的位置,LSM hook 點一般會被插入到被訪問的內核對象與 DAC 檢查之間。系統在完成 DAC 檢查通過之后,然后根據 LSM 框架調用系統中啟用的 LSM 模塊,檢查是否允許訪問,這也是為什么 SELinux 的檢查是在 DAC 之后的原因。同時我們也可以看到與之前 Seccomp 在系統調用入口點的檢測判斷不同,LSM Hook 點所在的位置基本上位于實際資源的訪問之前,在這個時候相關的數據信息已經從用戶空間復制到內核空間中,也就不會再有攻擊者在用戶空間進行篡改的可能性。
如果系統中有多個 LSM 模塊,就會根據 LSM 在初始化時的優先順序依次執行,所有檢查都被允許才可以繼續訪問內核對象。通過使用 LSM 框架,就可以進行內核安全審計和元數據捕獲。安全開發人員只需要按照既定的調用規范編寫 LSM 模塊,并加載進 Linux 內核,不再需要對系統內核代碼進行修改。這就方便了安全人員不在受限于已有的 AppArmor、SELinux 等模塊可以基于自身公司容器環境的實際需求,定制化的開發更為輕便的訪問控制模塊,有針對性地保障容器環境。而 Linux 5.4中加入的 lockdown 模塊直接禁止了運行時對內核的動態修改,使得 LSM 框架成為 Linux 安全加固工具開發的最佳途徑之一。
LSM Stacking
當前的 Linux 系統雖然支持多個 LSM 模塊的運行,但是這種運行依然存在著很大的限制,例如 SELinux 和 AppArmor 不能運行在同一系統中。其實基于這種限制,LSM 模塊被劃分為兩種:Major LSM 和 Minor LSM。目前 Linux 系統中提供的 Major LSM 包括 SELinux、SMACK、AppArmor 和 TOMOYO,這四個模塊都是 MAC 的實現。LSM 框架在最初設計時只允許啟用一個 LSM 模塊,Major LSM 模塊在設計開發時都假設自己擁有對受保護內核對象的安全上下文指針和安全標識符的獨占訪問權限。例如進程相關的“/proc/[pid]/attr”目錄下的相關文件,就是用來標記進程的安全屬性,像“/proc/[pid]/attr/current”文件,被 SELinux 用來標識進程的安全上下文,而 AppArmor 模塊則用于標識進程對應的配置文件。由于 Major LSM 所具有的排他性,即使四個安全模塊都編譯進了內核,內核在啟動時只能打開一個 Major LSM 模塊。而 Minor LSM 模塊則沒有這種排他性,可以同時運行在系統中。相比于 Major LSM,他們的作用范圍更小,較少地訪問或者使用內核對象的安全上下文指針,例如 YAMA 模塊主要是對 Ptrace 函數調用進行訪問控制。其他 Minor LSM 模塊還有 LoadPin、SetSafeID、Lockdown 等。并且他們一般直接硬編碼了大部分安全策略,相對地 Major LSM 模塊則可以加載用戶可配置的安全策略。在 Linux 5.1 版本之前,通過啟動參數 “security=”,內核在啟動時確認打開哪個 Major LSM 模塊,若未指定則按照 Kconfig 編譯配置中 CONFIG_DEFAULT_SECURITY 的值啟動。
為了更便于多個 LSM 模塊的加載使用,LSM 框架在近年來也在逐步逐步消除 Major LSM 模塊之間獨占性的問題。從 5.1 版本開始,改進了模塊的啟動方式,啟動參數由 “lsm=” 替換了原有的 “security=”(參數被保留,但是存在 “lsm=” 參數時,不起作用), Kconfig 編譯配置中 CONFIG_DEFAULT_SECURITY 也被替換為 CONFIG_LSM。內核在啟動過程中會按照 “lsm=” 參數中的順序啟動相應的的 LSM 模塊。
為了區分Major LSM 和 Minor LSM,引入了 LSM_FLAG_LEGACY_MAJOR 和 LSM_FLAG_EXCLUSIVE 標志來標注對應的 LSM 模塊的排他性。如果啟動順序中配置多個 Major LSM 模塊,那么在啟動過程中,內核會按照順序只打開第一個具有 LSM_FLAG_EXCLUSIVE 標志的模塊。當然這部分只是對模塊啟動的優化,改進的另一個重要的目標就是可以讓一個系統中開啟多個 Major LSM 模塊。從 5.1 版本開始 TOMOYO 已經被消除了排他性標記,而 AppArmor 也很快將可以消除這一標記,與其他 MAC 模塊同時運行在同一系統中(參考 LSM: Module stacking for AppArmor)。這種特性的發展為不同業務容器配置不同的 MAC 模塊帶來了可能性。
*LSM: Module stacking for AppArmor,詳見:https://lwn.net/ml/linux-kernel/20220415211801.12667-1-casey@schaufler-ca.com/
2.3 eBPF 觀測與防護
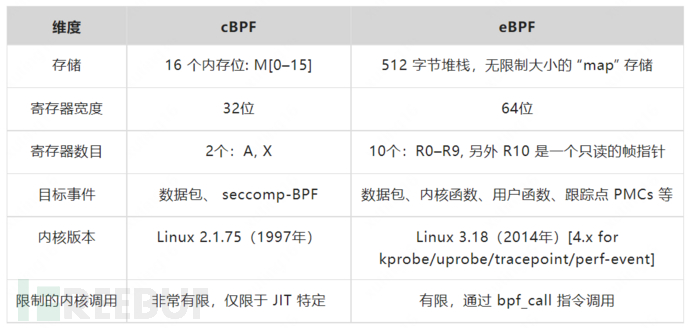
eBPF,全稱為擴展的伯克利數據包過濾器(Extended Berkeley Packet Filter),是傳統 BPF(以下稱為 cBPF)的后繼者。之前我們介紹過 SECCOMP_MODE_FILTER 模式下的 Seccomp 也是通過 cBPF 來構建自定義的系統調用篩查規則。cBPF 最初的設計目標是用于過濾網絡數據包的,受限在內核空間使用,只有少數用戶空間程序(例如:tcpdump和 seccomp)可以編寫這類過濾器。
2014 年,Alexei Starovoitov 對 cBPF 進行徹底地改造,實現了更為高效的 eBPF。時至今日 cBPF 現在已經基本廢棄,Linux 內核只運行 eBPF,內核會將加載的 cBPF 轉換成 eBPF 再執行。下面是 CBPF 和 eBPF 的對比:(參考【19】)
eBPF 的設計的最初目標是針對現代硬件進行的優化,生成指令集更接近硬件的 ISA(Instruction Set Architecture),所以 eBPF 相比于原有的 BPF 解釋器生成的機器碼執行得更快。在這之后更重要的一步改進優化就是將 eBPF 擴展到用戶空間,提供了用戶空間和內核空間數據交互的能力,這也使得 eBPF 可以適用于更為復雜的數據觀察和分析場景中。隨著越來越多的新特性被合入到 Linux 內核社區,eBPF 支持的功能已經越來越豐富,擴展了內核態函數、用戶態函數、跟蹤點、性能事件(perf_events)以及 LSM 等事件類型。下表列出了目前 eBPF 一些重要的特性(詳細可參見 BPF Features by Linux Kernel Version:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md):
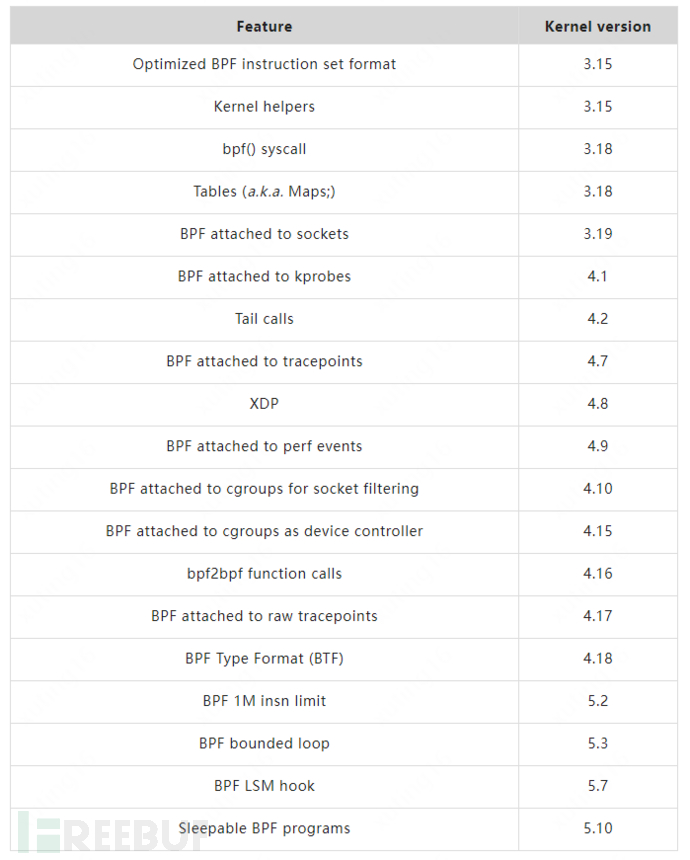
隨著這些改進的加入,eBPF 的使用場景也不再僅僅是網絡分析,可以基于 eBPF 開發性能分析、系統追蹤、網絡優化、安全防護等多種類型的工具和平臺,許多最新的檢測、監控軟件和性能跟蹤工具都是基于 BPF 技術,并且在云原生社區中,eBPF 被大量項目采用(例如 Cilium、Falco、Tracee)。
*Cilium詳見:https://docs.cilium.io/en/v1.8/intro/、Falco詳見:https://falco.org/、Tracee詳見:https://github.com/aquasecurity/tracee
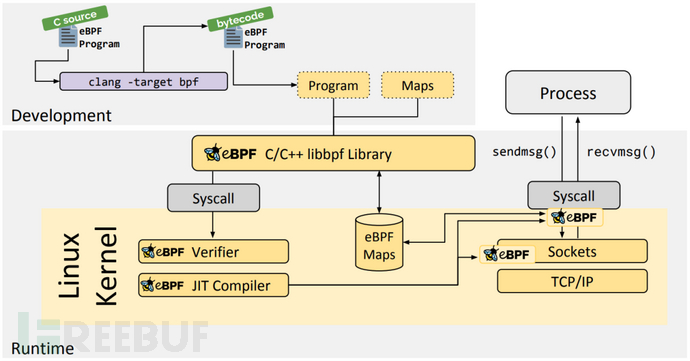
eBPF 程序本身是一個標準的 ELF(可執行和可鏈接格式,Executable and Linkable Format)文件,一般由 C 語言開發并使用 LLVM 編譯而成。作為標準的對象文件,同樣可以用像 readelf 這樣的工具來檢查,其中包含程序字節碼和所有映射的定義。之后用戶空間程序就可以通過 bpf() 系統調用將 eBPF 字節碼加載到內核,在加載的過程中,內核會使用驗證器組件對字節碼的安全性進行驗證,避免 eBPF 程序不會對內核造成崩潰影響。在 eBPF 程序運行過程中,如果有需要就可以通過 Maps 或者 perf-event 事件將執行結果或者檢測到的數據信息回傳至用戶空間程序,并且用戶空間程序也可以通過 Maps 給 eBPF 程序傳遞數據。下圖是 eBPF 整個流程的圖示:
2.4 eBPF 與 LSM 模塊
相較于 LSM 框架,eBPF 提供了一種更加簡便安全的方式在 Linux 內核中運行自定義的代碼。通過編寫內核模塊來改變或擴展內核行為,往往需要足夠的內核編程知識,并且在編寫使用過程中需要十分謹慎,以免因為一些疏忽帶來內核代碼崩潰的問題,甚至留下攻擊者可以利用的漏洞。因此為了保障內核安全性,往往內核模塊的開發以及內核新版本的發布,都需要長時間的分析測試。
而 eBPF 程序的開發則不需要通過復雜的內核編譯,只需要引入相關結構體的頭文件申明,這就給 eBPF 程序的開發降低了難度。同時 eBPF 在安全性保證上提供了一道有效的屏障—— eBPF 驗證器:在整個 eBPF 的使用過程中,內核會在加載 eBPF 程序時對 eBPF 程序進行分析驗證,保證 eBPF 程序不會造成內核崩潰等問題,當然這不意味著 eBPF 程序在開發后不需要經過測試驗證,但是在一定程度上保障了 eBPF 的安全性。驗證器首先會確保程序中沒有不可達的指令,并且沒有無界循環,確保程序在一定數量的指令數量后安全地終止,其次通過模擬執行,確保所有路徑都是可以運行完成的,驗證程序沒有越界訪問內存。在驗證通過后,eBPF 程序才能被解釋執行。更具有優勢的一點是,eBPF 程序是可以動態地從內核中加載或刪除,而不像 LSM 模塊需要重啟系統才能進行模塊加載,完全可以做到不打斷任何已經存在的進程。
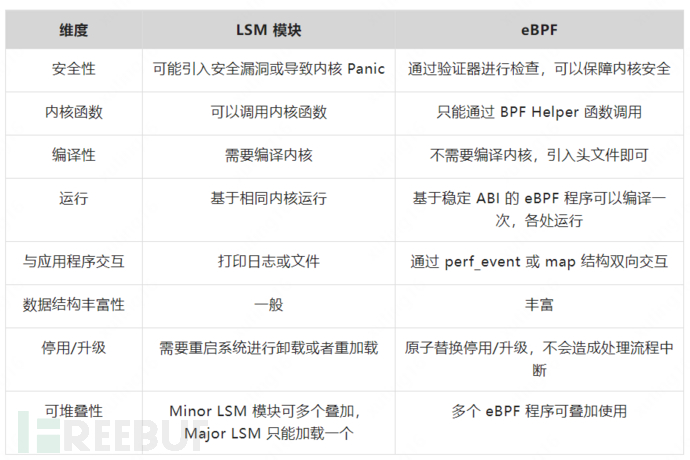
下表列舉了一些 LSM 模塊和 eBPF 的差異點:(參考【19】)
2.5 eBPF 與容器安全
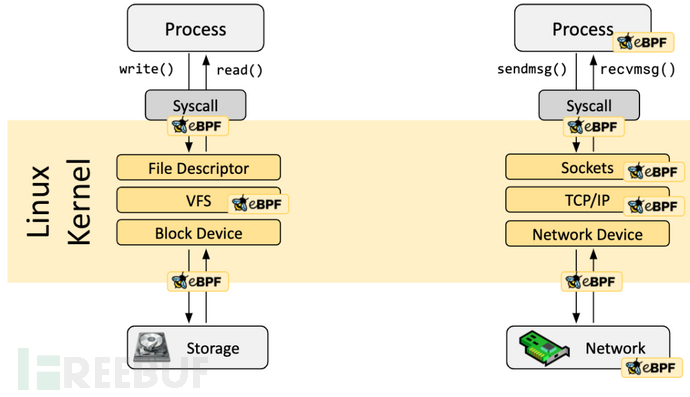
正如前面提到,作為一個功能豐富的新特性,eBPF 提供了一種便利的可基于系統或程序事件高效安全執行特定代碼的通用能力,并且它可檢測的事件覆蓋了系統的各個方面(如下圖所示),提供了豐富的可觀察信息,甚至在 Linux 5.7 版本后 eBPF 程序可以插入 LSM hook 點。
對于容器環境來說,所有運行在一臺機器上的容器都和主機共享內核,內核了解主機上運行的所有應用代碼。eBPF 的 Hook 點可以說是遍布內核的各個角落,這對于容器安全的檢測和防護是很大的助力,方便了對容器中正在進行的操作的分析和判斷,近些年來有許多利用這項新技術來解決一些容器安全問題的工具。當前這類安全上的工具主要可以分為兩類:一類是確保網絡活動的安全,eBPF 最初就是用于網絡數據包過濾的技術,可以在網絡驅動中盡可能早的位置提供最優的數據包處理能力,過濾并丟棄惡意或非預期的流量以及防范 DDOS 攻擊等。而另一類則是檢測惡意行為,確保應用程序在運行時的行為安全。例如利用 eBPF 同樣可以在系統調用的入口處插入檢測過濾程序,但是相比于 Seccomp 更強大的地方在于,eBPF 程序可以對其中的指針參數進行解引用,這也就方便了更進一步的行為分析。
早期的 eBPF 程序并沒有直接的阻斷功能,而是作為觀測分析工具將收集到的的信息交給用戶空間程序,這樣用戶空間程序根據這些信息判斷目標進程操作的威脅性來殺死目標進程。目前大部分的成熟的基于 eBPF 開發的安全工具都將其作為系統觀察和信息收集的手段加以利用,例如 Aqua Security 云原生安全公司開發的 Tracee 和 Sysdig 開發的 Falco 都是基于 eBPF 系統觀測能力的異常行為檢測工具。之后在 Linux 5.3 版本中引入了 send_signal() Helper 函數,BPF 程序本身具備了可以直接決斷是否終止目標進程的能力。
2022年5月,Cilium 的母公司 Isovalent 在歐洲舉行的 KubeCon 技術峰會期間發布了云原生運行時防護系統——Tetragon,正是利用這一新特性來做到安全防護的能力。無論是通過用戶空間高權限進程殺死惡意進程,或者是 eBPF 程序直接通過 send_signal() 終止進程,這兩種加固阻斷的方式或多或少都是存在 TOCTTOU 風險的。直到 Linux 5.7 版本,eBPF 程序可以直接插入 LSM hook 點,并影響 LSM Hook 點的判定結果。需要區分的是,5.7 版本之前的 eBPF 程序雖然可以利用 kprobe 進行動態插入來觀測 LSM 相關方法的情況,但是只能用于數據采集,并不能影響 LSM 方法的返回值。正是這一新特性 Kernel Runtime Security Instrumentation(簡稱 KRSI)的出現,使得基于 eBPF 開發的安全工具才具備真正意義上的加固阻斷能力,也為云原生安全加固相關的工作帶來了更多可能。
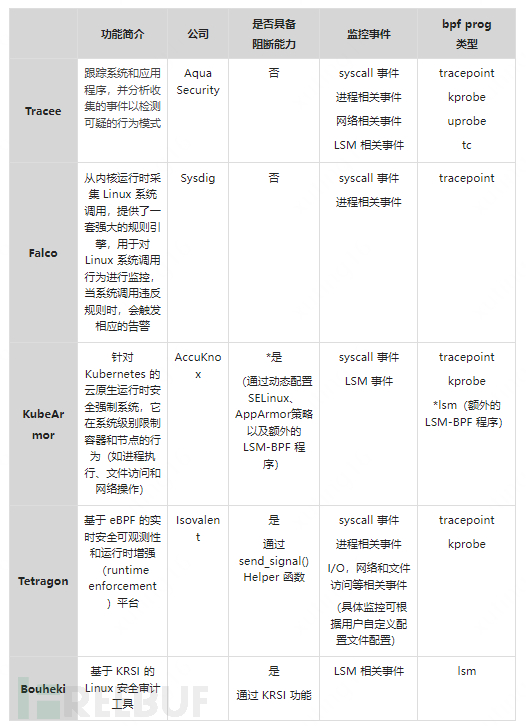
下表列舉了當前比較有名的基于 eBPF 開發的安全工具(當前基于KRSI的項目較少,筆者選取了github上比較有特點的一個開源項目作為對比):
03容器運行時安全的未來
當前云原生的技術大多數被服務于 Web 應用的相關業務,此類業務往往把性能要求放在較為靠前的位置,對于設備上選用的安全加固技術都會有性能方面的考量。而 eBPF 的出現為容器安全帶來了一種能夠動態、輕量、無感知的提升防御能力的方式。其全面的觀測能力,可以輕松地監控到容器安全可觀測性的四個黃金信號【18】:進程執行、網絡套接字、文件訪問和七層網絡身份,保證了安全檢測的全面性。同時 KRSI 特性的出現使得 eBPF 程序還具備了等同于 LSM 模塊進行訪問控制的決斷能力,而不再只是單純地作為觀測工具。因此在未來的發展過程中,eBPF 的相關應用將是容器運行時安全最重要的助力。同時,不可忽視的是對低版本內核系統上的安全防護,目前并在未來很長的一段時間內,大多數的主機服務器上仍然將運行著 Linux 3.* 以及 4.* 的系統。對于這些系統來說,Seccomp、LSM 模塊等內核安全機制依舊是保障容器安全不可或缺的部分。
?// 文丨支葉盛:美團安全研究員,主要從事 Linux 內核安全及二進制程序安全等方向的研究,當前負責美團內部操作系統安全、云原生安全等方向的安全建設。
1.“Docker Overview”:https://docs.docker.com/get-started/overview/
2.“云原生之容器安全實踐”:https://tech.meituan.com/2020/03/12/cloud-native-security.html
3.“Exploring container security: An overview”:https://cloud.google.com/blog/products/gcp/exploring-container-security-an-overview
4.“MITRE ATT&CK? Containers Matrix”:https://attack.mitre.org/matrices/enterprise/containers/
5.“Sysdig 2022 Cloud?Native Security and Usage Report”:https://sysdig.com/wp-content/uploads/2022-cloud-native-security-and-usage-report.pdf
6.CIS Docker Benchmark:https://www.cisecurity.org/benchmark/docker
7.CIS Azure Kubernetes Service (AKS) Benchmark:https://www.cisecurity.org/benchmark/kubernetes
8.“New Container Kernel Features” - Christian Brauner, Canonical Ltd.*:https://static.sched.com/hosted_files/ossna19/22/OSS%20NA%202019_%20New%20Container%20Kernel%20Features.pdf
9.“capabilities(7) - Linux man page”:http://man7.org/linux/man-pages/man7/capabilities.7.html
10.“Seccomp BPF (SECure COMPuting with filters)“:https://www.kernel.org/doc/html/latest/userspace-api/seccomp_filter.html
11.“seccomp_unotify(2) — Linux manual page”:https://man7.org/linux/man-pages/man2/seccomp_unotify.2.html
12.“Inside the Linux Security Modules (LSM)” - Vandana Salve, Prasme Systems:https://static.sched.com/hosted_files/ossna2020/3a/ELC_Inside_LSM.pdf
13.“LSM Stacking - What You Can Do Now and What's Next” - Casey Schaufler, Intel:https://static.sched.com/hosted_files/lsseu2019/84/201910-LSS-EU-xxx-Stacking.pdf
14.《What Is eBPF? An Introduction to a New Generation of Networking, Security, and Observability Tools》—— Liz Rice
15.“eBPF Documentation”:https://ebpf.io/what-is-ebpf
16.“eBPF 技術簡介”:https://cloudnative.to/blog/bpf-intro/
17.《Linux Observability with BPF: Advanced Programming for Performance, Analysis and Networking》(譯名《Linux內核觀測技術BPF》)—— David Calavera and Lorenzo Fontana
18.《Security Observability with eBPF: Measuring Cloud Native Security Through eBPF Observability》—— Jed Salazar and Natalia Reka Ivanko
19.“基于 eBPF 實現容器運行時安全”:https://www.ebpf.top/post/ebpf_container_security/
20.“Tetragon進程阻斷原理”:https://www.cnxct.com/how-tetragon-preventing-attacks/
21.“KRSI — the other BPF security module”:https://lwn.net/Articles/808048/


















