













什么是多運行時架構?
作者 | 張旭海,劉振偉
服務化演進中的問題
自從數年前微服務的概念被提出,到現在基本成了技術架構的標配。微服務的場景下衍生出了對分布式能力的大量需求:各服務之間需要相互協作和通信,以及共享狀態等等,因此就有了各種中間件來為業務服務提供這種分布式能力。
 圖片
圖片
我們熟知的“Spring Cloud 全家桶”正是憑借著對各種中間件優秀的集成與抽象能力,成為了當時炙手可熱的項目。
然而隨著業務的快速發展,組織規模的不斷擴大,微服務越來越多,系統規模越來越大則是服務化體系架構演進的必然。這就帶來了兩方面復雜度的上升:
1.服務治理與接入的復雜度
服務治理代表了系統中服務資源的地圖及其獲取途徑,例如通過注冊發現服務提供圖譜能力,路由、網關、負載均衡服務提供獲取途徑。
服務接入則代表了如何使用系統中的服務能力,例如通過中間件提供的API 協議或是封裝的 SDK 來接入該中間件。各種業務服務越多、中間件越復雜,整個系統服務治理與接入的復雜度就會急劇上升。
2.團隊協作的復雜度
該復雜度主要體現在團隊的認知負載上,復雜的依賴、溝通、協作將明顯拖慢交付進度。正如康威定律所述的,由于服務復雜度的上升,團隊之間的交互成本也隨之上升。
如下是復雜度上升問題的一個顯而易見的例子。
 圖片
圖片
當系統中的中間件都通過 SDK 作為其外化能力的控制方式,來封裝協議、數據結構與操作方法。隨著中間件數量和種類不斷增多,大量孤立的 SDK 被綁定在業務服務上,導致兩方面問題:
- 版本升級困難:SDK 與業務服務的強依賴性導致想要升級 SDK 版本變得異常復雜與緩慢
- 業務服務難以異構:SDK 所支持的語言反向限制了業務服務所能選擇的語言,例如 Spring Cloud 幾乎沒有官方的多語言支持
如何治理這種不斷上升的復雜度呢?復雜問題歸一化是一種不錯的手段。
什么是多運行時架構
多運行時微服務架構(Multi-Runtime Microservice Architecture)也被簡稱為多運行時架構,是由 Red Hat 的首席架構師 Bilgin Ibryam 在 2020 年初所提出的一種微服務架構形態,它相對完整地從理論和方法的角度闡述了多運行時架構的模型(實際上,在 2019 年末,微軟的 Dapr v0.1.0 就已經發布)。
暫時先拋開到底什么是“多運行時”不談(因為多運行時這個名字個人覺得起得可能不太妥當),先看看多運行時架構都包括了哪些內容。
分布式應用四大類需求
上一節提到,為了治理不斷上升的復雜度問題,歸一化是手段之一。歸一化的第一步就是對問題進行歸類。
Bilgin Ibryam 梳理了分布式應用的各類需求后,將其劃分到了四個領域內:
 圖片
圖片
(來源:Multi-Runtime Microservices Architecture)
分別是:
- 生命周期:即應用從開發態到運行態之間進行打包、部署、擴縮容等需求。
- 網絡:分布式系統中各應用之間的服務發現、容錯、靈活的發布模式、跟蹤和遙測等需求。
- 狀態:我們期望服務是無狀態的,但業務本身一定需要有狀態,因此包含對緩存、編排調度、冪等、事務等需求。
- 綁定:與外部服務之間進行集成可能面臨的交互適配、協議轉換等需求。
Bilgin Ibryam 認為,應用之間對分布式能力的需求,無外乎這四大類。且在 Kubernetes 成為云原生場景下運行時的事實標準后,對生命周期這部分的需求已經基本被覆蓋到了。
因此實際上我們更關注的是如何歸一化其他三種需求。
與單機應用的類比
單機應用一般大都是以用戶態進程的形式運行在操作系統上。顯然,與微服務類似,單機應用的核心關注點也是業務邏輯,與業務關系不大的支撐能力,都要依賴操作系統來完成。
因此上述由 Bilgin 歸納的分布式應用四大類需求,其實我們很容易就可以和單機應用進行合理的類比:

從上述類比來看我們發現,單單是 Kubernetes 可能還不足以稱為是 “云原生操作系統”,除非有一種解決方案,能在分布式環境下,把其他幾項支撐能力也進行歸一化整合,才能理直氣壯的冠此大名。」
Service Mesh 的成功
Service Mesh 在近幾年的高速發展,讓我們認識到網絡相關的需求是如何被歸一化并與業務本身解耦的:
通過流量控制能力實現多變的發布模式以及對服務韌性的靈活配置,通過安全能力實現的開箱即用的 mTLS 雙向認證來構建零信任網絡,通過可觀察性能力實現的網絡層Metrics,Logging 和 Tracing 的無侵入式采集。
而上述服務治理能力,全部被代理到 Sidecar 進程中完成。這就實現了 codebase level 的解耦,網絡相關的分布式能力完全拋棄 SDK。
 圖片
圖片
伴隨著 Service Mesh 的成功,我們不禁會想到,是否可以將另外的兩種需求——狀態和綁定 ——也進行 Mesh 化改造呢?
分布式能力 Mesh 化
基于對 Service Mesh 的拓展,我們大可以將其他的能力也進行 Mesh 化,每一類能力都以 Sidecar 的形式部署和運作:
 圖片
圖片
在業界也有不少從某些能力角度切入的方案:
 圖片
圖片
(來源:Multi-Runtime Microservices Architecture)
我們可以發現,各類方案都有自己的一套對某些能力需求的 Mesh 化方案,合理地選擇它們,的確滿足了分布式能力 Mesh 化的要求,但卻引入了新的問題:
- 復雜度從業務服務下沉到了 Mesh 層:多種 Mesh 化方案之間缺乏一致性,導致選型和運維的成本很高
- 多個 Sidecar 進程會帶來不小的資源開銷,很多解決方案還需要搭配控制面進程,資源消耗難以忽視
對業務復雜度上升的歸一化,現在變成了對 Mesh 復雜度上升的歸一化。
Multi-Runtime = Micrologic + Mecha
Bilgin Ibryam 在多運行時微服務架構中,對前述討論的各種問題點進行了整合,提出了 Micrologic + Mecha 的架構形態:
 圖片
圖片
(來源:Multi-Runtime Microservices Architecture)
在 Micrologic 中只包含業務邏輯,盡可能的把分布式系統層面的需求剝離出去,放到 Mecha 中。從 Mecha 的命名就可以明白它的功能:
由提供各種分布式能力的 “機甲” 組成的 Sidecar 進程,與 “裸奔的” 業務邏輯一起部署。因為是 Micrologic 進程和 Mecha 進程共同部署的這種多個 “運行時” 的架構,所以稱之為 “多運行時架構”。
Mecha 不僅成功地將分布式能力從耦合的業務進程中抽取出來,還整合了方案,避免了多種方案混合的額外成本。可以說 Mecha 在本質上提供了一個分布式能力抽象層。
因此與其叫 “多運行時架構”,不如叫 “面向能力的架構”。
微軟的嘗試:Dapr
Dapr 是微軟主導開發并開源的一種 Mecha runtime,從宏觀上看它處在整個架構的中間層:
 圖片
圖片
(來源:Dapr)
自上而下分別是業務層、Dapr Runtime層、基礎設施層。Dapr 通過 Http 或 gRPC API 向業務層提供分布式能力抽象,通過稱為 “Component” 的接口定義,實現對具體基礎設施的插件式管理。
Building Blocks
作為一個合格的 Mecha,最關鍵的就是如何定義分布式能力抽象層。如何把各類中間件提供的分布式能力定義清楚是一項挑戰。Dapr 中定義的分布式能力抽象層,稱為 Building Blocks。顧名思義,就是一系列的 “構建塊”,每一個塊定義了一種分布式能力。
 圖片
圖片
(來源:Dapr)
其中有一些 Blocks 的能力由 Dapr 自己就能實現,有一些則需要由實際的基礎設施或中間件來實現。選取幾個典型舉例說明:
- Service-to-service Invocation:提供服務間調用的能力,其中也隱含了服務的注冊與發現。該 Block 的能力由 Dapr 直接實現。
- State management:提供狀態管理能力,最簡單的就是存取狀態。該 Block 需要其他基礎設施通過 Component 的形式實現,例如定義一個 Redis Component。
- Publish and subscribe:提供消息發布和訂閱的能力,這是非常典型的一種分布式能力。也需要通過基礎設施來實現,如定義一個 Kafka Component。
Dapr 的限制與挑戰
Dapr 期望通過定義一個能容納所有需求的分布式能力抽象層,來徹底解放業務邏輯。從歸一化的角度看,不得不說這是一種大膽而富有野心的嘗試,理想條件下的確能非常優雅地解決問題。但現實總是充斥著各種跳脫出理想的情況,Dapr 在推廣的過程中遇到了很多限制與挑戰。
與 Service Mesh 整合
作為面向開發側提供的能力抽象層,Dapr 在網絡能力上包含了 mTLS、Observability 與 Resiliency(即超時重試熔斷等),但并沒有包含諸如負載均衡、動態切換、金絲雀發布等運維側的流量管理能力。
 圖片
圖片
(來源:Dapr)
因此對于不斷走向成熟的業務系統,可能既要 Service Mesh 在運維側的流量管理能力,又要 Dapr 在開發側的分布式抽象能力,不管誰先誰后,都將面臨一個問題:怎樣搭配使用它們才是正確的?某些場景下可以做適配,如:
- 對于 distributed tracing 的能力,如果采用 Service Mesh 來實現,則需要考慮將原本 Dapr 直連的中間件也加入 mesh 網絡,否則會 trace 不到。但從 distributed tracing 本身功能角度講,更應該使用 Dapr。
- mTLS 應該只在 Dapr 或者 Service Mesh 中開啟,而不應該都開啟。
但 Dapr 與 Service Mesh 配合使用中難以避免的是開銷的問題,包括資源開銷和性能開銷。
每個應用 Pod 攜帶兩種 sidecar,再加上 Dapr 和 Service Mesh 自己的控制面應用(高可用方案主備或多副本),這些資源開銷是無法忽略,甚至是非常可觀的。
而由于 Service Mesh 網絡代理的流量劫持,網絡調用需要先經過 Dapr sidecar,再經過網絡代理 sidecar,被代理兩次,也會造成一定的性能開銷。
下表是匯總的 Dapr 官方標注的 daprd 資源與性能消耗數據,以及 Istio v1.16(最新版未找到)官方標注的 envoy 資源與性能消耗數據:
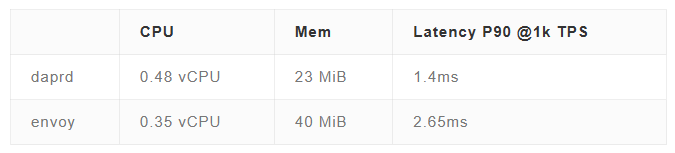
簡單計算一下就會發現,當擁有 1000 個業務實例時,dapr + istio 的 Sidecar 進程可能會消耗 800+ vCPU 和 60+ GiB 內存。
隨著分布式能力抽象層的不斷擴展,到底哪些屬于開發側,哪些屬于運維側,也許不會像現在這樣涇渭分明了。因此已經有對 Multi-Runtime 與 Service Mesh 能力邊界越來越模糊的討論。
Sidecarless?
從上一節的表格我們發現,資源消耗以及性能的問題其實不只是 Dapr 下的場景,實際上它是 sidecar 模式自有的限制,因此在 Service Mesh 領域的討論中,已經有提出 Sidecarless 的概念了,即通過 DaemonSet 而不是 Sidecar 的形式來部署網絡代理。
 圖片
圖片
對于網絡代理的 Sidecarless 化,支持方認為它能帶來高性能、低資源消耗的優點,而反對方則認為它會導致安全性與隔離性差、故障的爆炸半徑過大等缺點。
那么,Mecha 是否也可能會走向 Sidecarless 呢?
與網絡代理的 Sidecarless 類似,如果將 Mecha 做成 Daemonset,其優劣勢也差不多。而 Daemonset 形式的 Mecha,由于只啟動一次,可能會在 Serverless 的場景下大幅縮短 Serverless 函數的執行時間。對此 Dapr 項目也有相關的討論。
就像今年 Cilium 發布支持 Service Mesh 能力的辦法,通過 eBPF 在內核態實現 L3 L4 層能力,而對應的 L7 層能力則交給用戶態的 Envoy 處理這種將問題一分為二的思想,也許多運行時架構的未來方案也可能是折中或是多種方式結合的。例如采用在 Node 上按 Service Account 或 Namespace 運行多實例,或是輕量級 Sidecar 做協議轉換+DaemonSet 做流量管理和網絡調用。
當然 DaemonSet 也有其固有的缺陷,資源被共享從而降低消耗的同時,故障也被共享了,而且故障產生的傷害面也變大了,此外還會導致 DaemonSet 被應用使用的爭搶問題,以及應用之間的數據暴露風險。到底后續將會如何演進,我們拭目以待。
定義抽象能力的(API)的困境
分布式能力抽象層,是對分布式場景下需求的抽象性定義,抽象作為一種共識,其要義就在于保留共性而排除個性。但實際當中會發現,同類型中間件的差異化恰恰體現在了一些高級的、細分的專有特性上,很多業務對中間件選型的原因也在于這些專有特性上。
這就引出了一個困境:抽象能力所覆蓋的需求,其豐富程度與可移植性成反比。
 圖片
圖片
就如上圖所示,如果抽象能力范圍只覆蓋到紅色的部分,則組件 ABC 的專有特性都無法被引入,而如果抽象能力范圍覆蓋到綠色,那么就無法遷移到組件C。
Dapr 的 Building Blocks 中,State management 就存在這樣的一個例子:
State management 定義了基于事務操作的能力 /v1.0/state/<storename>/transaction,支持 State management 能力的 Component 有很多,對于支持事務的中間件如 Redis 就一切正常,但有一些并不支持事務的如 DynamoDB,則這種能力就無法使用。
定義抽象能力的困境,本質上是一種對能力收斂的權衡,這種權衡可能是與具體的業務需要高度相關的。
關于如何降低專有特性對能力集合可移植性的沖擊,敖小劍在他的文章《死生之地不可不察:論API標準化對Dapr的重要性》中提到了四種解決思路:
(1) 在 Mecha 層彌補能力缺失
如果缺失的能力支持用基礎能力來間接實現,就可以在 Mecha 內做處理。例如對于不支持批量寫入的基礎設施,在 Dapr 中通過 forloop 連續調用單次寫入也能間接地彌補這一能力(雖然無法做到性能一致)。 然而這樣也可能導致 Dapr 越來越臃腫,怎么權衡見仁見智。
(2) 在 Component 層彌補能力缺失
Component 作為某種具體基礎設施與 Dapr 的適配器,可以將 1 中的方案下沉到 Component 里面,避免 Dapr 本身的臃腫,然而這種辦法的缺陷在于每種基礎設施只要想彌補缺失的能力,就都要分別在自己的 Component 中實現一遍。
(3) 直接忽略某些缺失的能力
例如在 State management 中對多副本強一致性的配置屬性 consistency,假如實際的存儲中間件是單副本架構,那么就可以直接忽略掉該屬性。
(4) 其余的情況,只能在業務側處理
就像前文提到的事務能力,對于不支持的基礎設施必須要明確報錯,否則可能導致業務不正確。這種情況就只能在業務側做限制,本質上是侵入了業務層。
這四種解決思路從權衡與折中的角度,覆蓋了絕大多數能力缺失的場景,本質上這些思路屬于 “堅守API 能力交集” 的辦法。假如跳出“抽象共識”這一限制,我們是否可以試圖構建出一套包含了所有分布式能力的“大全集”呢?顯然只是理論可行,但不現實。
然而,在企業實際的場景下,這個“全集”的規模可能并不一定像我們想象的那么龐大,因此就有可能提供額外的一種思路,即對分布是抽象層進行擴展,將有限規模的“個性”全部包含進去,形成 “并集” 從而規避上述問題。
 圖片
圖片
螞蟻 Layotto 的設計中體現了這種方案,詳見下文。
螞蟻金服的方案:layotto
螞蟻金服作為 Dapr 的早起使用者,在落地的過程中結合遇到的問題及業務思考,在 2021 年年中推出了自研的 Mecha 方案:layotto。
Layotto 的架構
 圖片
圖片
(來源:Layotto)
非常有趣的一點是,layotto 是以 MOSN 為基座的。MOSN 是螞蟻金服自研的網絡代理,可用于 Service Mesh 數據面。因此 layotto 類似于是 MOSN 的一個特殊的插件,向業務側提供分布式能力抽象層,并且仍然以 Component 的形式封裝各種中間件的訪問與操作,而在這之下的所有網絡層交互全部代理給 MOSN。
由于 layotto 在運行態上是與 MOSN 綁定在一個 Sidecar 內的,因此就減少了一部分前文提到的兩個 Sidecar 之間通信的開銷。當然 layotto 可以這樣做也有一部分原因在于 MOSN 本身已經在螞蟻內部大規模落地,同時螞蟻也有足夠的研發強度來支撐 layotto 的開發。
“私有協議”與“可信協議”
Layotto 的開發者,在討論多運行時架構以及 layotto 落地實踐的文章中,嘗試對可移植性的概念進行了擴展,將支撐分布式能力的協議劃分為“可信協議”與“私有協議”。
其中,可信協議指代的是一類影響力很大的協議如 Redis 協議、S3 協議、SQL 標準等。這一類協議由于用戶眾多,且被各類云廠商所支持,因此可以認為它們本身就具有可移植性。
私有協議則指代一些企業內部自研的、閉源或影響力小的開源軟件提供的協議。顯然這一類協議才更需要考慮抽象與可移植性。
因此實際上的所謂分布式能力抽象層可能會是如下圖所示的樣子:
 圖片
圖片
(來源:如何看待 Dapr、Layotto 這種多運行時架構?)
各類可信協議不再二次抽象,而是直接支持,對其余的私有協議再進行抽象。這種直接支持開源協議的思路,部分緩解了定義抽象能力的困境問題。
靈活的擴展模型
前文提到的 API 擴展形成 “并集”,Layotto 通過提供 In-Tree 形式的私有 API 注冊點,實現了不修改 Layotto 代碼就能擴展 API 能力:
 圖片
圖片
(來源:Layotto 官方文檔)
從代碼角度看,Layotto 是通過暴露 API 注冊鉤子,暴露啟動入口,來允許用戶自行擴展代碼,之后再調用啟動函數啟動進程。這樣擴展 API 代碼與 Layotto package 級隔離,但編譯后可形成同一個二進制文件。
另外,通過 MOSN 的 WASM 插件能力,Layotto 也支持通過 WASM 鏡像來擴展 API Filter。
未來展望
雖然多運行時架構這種理念從提出到現在只有兩年,但已經很少有人會否認它所帶來的價值,不論是 Dapr 還是 layotto 的快速發展,都明確了頭部企業對這一領域的投資邏輯。
當然目前從理論到實踐可能都不夠成熟,大家在落地實踐的過程中也都會或多或少遇到前文提到的一些局限。但這些局限所處的層次大都是工程化、技術選擇等具體的問題,相信隨著各方技術的不斷整合,實踐的不斷完善,問題都能解決。
對多運行時架構實踐的未來,結合當下的限制、挑戰以及趨勢,我們也許能勾勒出某種未來可能的架構形態:
 圖片
圖片
在這一架構形態下:
- 分布式能力抽象層提供標準能力抽象,以及靈活擴展的私有協議的能力
- 既成標準協議(對前文 "可信協議" 的另一種提法)作為 "既成的" 抽象能力,在Mecha 層只做協議轉換或直接透傳
- Mecha 與網絡代理層進程級耦合,各類特性不再明確區分開發側與運維側
- 進程在 Node 上按租戶/namespace 以及高可用要求劃分多實例
- 接入現代化的可觀測性體系,提升對故障的洞察分析能力,降低由于架構分層帶來的問題診斷困難
總之,不管是架構形態怎么變、能力怎么抽象,讓業務邏輯不斷內聚,越來越面向接口、面向能力編程的趨勢不會改變,服務化體系的未來值得期待。
Reference
- Multi-Runtime Microservices Architecture
- Dapr
- 死生之地不可不察:論API標準化對Dapr的重要性
- Layotto
- 如何看待 Dapr、Layotto 這種多運行時架構?




















