別再說你不會ElasticSearch調(diào)優(yōu)了,都給你整理好了!

?這篇文章,我們來聊一下最近這一兩年行業(yè)內(nèi)Java高級工程師面試的時候尤為常見的一個問題:談?wù)勀銓Ψ植际剿阉饕娴睦斫猓牧乃募軜?gòu)原理?
很多同學(xué)可能從來沒接觸過這個東西,所以本文我們就以現(xiàn)在最火最流行的El?asticsearch為例,來聊一下分布式搜索引擎的核心架構(gòu)原理。
一、倒排索引到底是啥?
要了解分布式搜索引擎,先了解一下搜索這個事兒吧,搜索這個技術(shù)領(lǐng)域里最入門級別的一個概念就是倒排索引。
我們先簡單說一下倒排索引是個什么東西。
假如說你現(xiàn)在不用搜索引擎,單純使用數(shù)據(jù)庫來存放和搜索一些數(shù)據(jù),比如說放了一些論壇的帖子數(shù)據(jù)吧,那么這個數(shù)據(jù)的格式大致如下:
id | title | content |
1 | Java好用嗎? | Java是非常非常好的一門語言。。。。 |
2 | 大家一起來學(xué)Java | 我這兒有一些很好的Java學(xué)習資源,比如說。。。 |
3 | 一次Java面試經(jīng)驗 | 去年這個時候,我學(xué)了Java,今年開始了面試。。。 |
很簡單吧,假設(shè)有一個id字段標識了每個帖子數(shù)據(jù),然后title字段是帖子的標題,content字段是帖子的內(nèi)容。
那么這個時候,比如我們要是用數(shù)據(jù)庫來進行搜索包含“Java”這個關(guān)鍵字的所有帖子,大致SQL如下:

咱們姑且不論這個數(shù)據(jù)庫層面也有支持全文檢索的一些特殊索引類型,或者數(shù)據(jù)庫層面是怎么執(zhí)行的,這個不是本文討論的重點,你就看看數(shù)據(jù)庫的數(shù)據(jù)格式以及搜索的方式就好了。
但是如果你通過搜索引擎類的技術(shù)來存放帖子的內(nèi)容,他是可以建立倒排索引的。
也就是說,你把上述的幾行數(shù)據(jù)放到搜索引擎里,這個倒排索引的數(shù)據(jù)大致看起來如下:
關(guān)鍵詞 id
- Java [1, 2, 3]
- 語言 [1]
- 面試 [3]
- 資源 [2]
所謂的倒排索引,就是把你的數(shù)據(jù)內(nèi)容先分詞,每句話分成一個一個的關(guān)鍵詞,然后記錄好每個關(guān)鍵詞對應(yīng)出現(xiàn)在了哪些id標識的數(shù)據(jù)里。
那么你要搜索包含“Java”關(guān)鍵詞的帖子,直接掃描這個倒排索引,在倒排索引里找到“Java”這個關(guān)鍵詞對應(yīng)的那些數(shù)據(jù)的id就好了。
然后你可以從其他地方根據(jù)這幾個id找到對應(yīng)的數(shù)據(jù)就可以了,這個就是倒排索引的數(shù)據(jù)格式以及搜索的方式,上面這種利用倒排索引查找數(shù)據(jù)的方式,也被稱之為全文檢索。
二、什么叫做分布式搜索引擎?
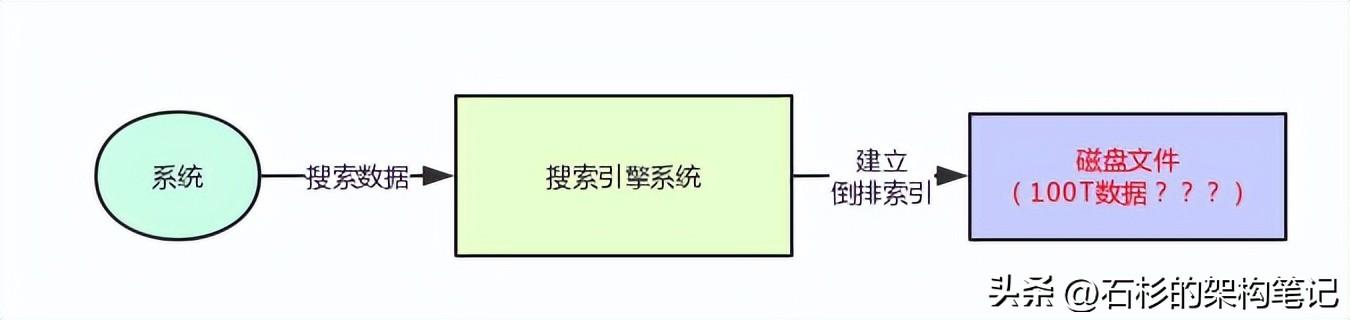
其實要知道什么叫做分布式搜索引擎,你首先得知道,假如我們就用一臺機器部署一個搜索引擎系統(tǒng),然后利用上述的那種倒排索引來存儲數(shù)據(jù),同時支持一些全文檢索之類的搜索功能,那么會有什么問題?
其實還是很簡單,假如說你現(xiàn)在要存儲1TB的數(shù)據(jù),那么放在一臺機器還是可以的。
但是如果你要存儲超過10TB,100TB,甚至1000TB的數(shù)據(jù)呢?你用一臺機器放的下嗎?
當然是放不下的了,你的機器磁盤空間是不夠的。
大家看一下下面的圖:
所以這個時候,你就得用分布式搜索引擎了,也就是要使用多臺機器來部署搜索引擎集群。
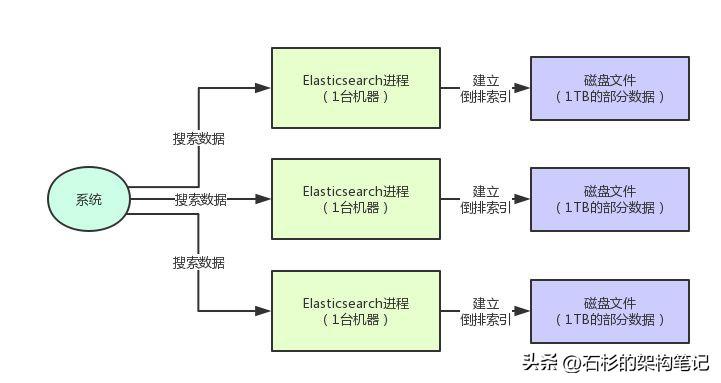
比如說,假設(shè)你用的是Elasticsearch(后面簡寫為:ES)。
現(xiàn)在你總共有3TB的數(shù)據(jù),那么你搞3臺機器,每臺機器上部署一個ES進程,管理那臺機器上的1TB數(shù)據(jù)就可以了。
這樣不就可以把3TB的數(shù)據(jù)分散在3臺機器上來存儲了?這不就是索引數(shù)據(jù)的分布式存儲嗎?
而且,你在搜索數(shù)據(jù)的時候,不就可以利用3臺機器來對分布式存儲后的數(shù)據(jù)進行搜索了?每臺機器上的ES進程不都可以對一部分數(shù)據(jù)搜索?這不就是分布式的搜索?
是的,這就是所謂的分布式搜索引擎:把大量的索引數(shù)據(jù)拆散成多塊,每臺機器放一部分,然后利用多臺機器對分散之后的數(shù)據(jù)進行搜索,所有操作全部是分布在多臺機器上進行,形成了完整的分布式的架構(gòu)。
同樣,我們來看下面的圖,直觀的感受一下。
三、Elasticsearch的數(shù)據(jù)結(jié)構(gòu)
如果你要是使用Elasticsearch這種分布式搜索引擎,必須要熟悉他的一些專業(yè)的技術(shù)名詞,描述他的一些數(shù)據(jù)結(jié)構(gòu)。
比如說“index”這個東西,他是索引的意思,其實他有點類似于數(shù)據(jù)庫里的一張表,大概對應(yīng)表的那個概念。
比如你搞一個專門存放帖子的索引,然后他有id、title、content幾個field,這個field大致就是他的一個字段。
然后還有一個概念,就是document,這個就代表了index中的一條數(shù)據(jù)。
下面就是一個document,這個document可以寫到index里去,算是index里的一條數(shù)據(jù)。
而且寫到es之后,這條數(shù)據(jù)的內(nèi)容就會拆分為倒排索引的數(shù)據(jù)格式來存儲。
id | title | content |
1 | Java好用嗎? | Java是非常非常好的一門語言。。。。 |
四、Shard數(shù)據(jù)分片機制
那么這個時候大家考慮一下,比如說你有一個index,專門存放論壇里的帖子,現(xiàn)在論壇里的帖子有1億,占用了1TB的磁盤空間,這個還好說。
如果這個帖子有10億,100億,占用了10TB、甚至100TB的磁盤空間呢?
那你這個index的數(shù)據(jù)還能在一臺機器上存儲嗎?答案明顯是不能的。
?這個時候,你必須得支持這個index的數(shù)據(jù)分布式存儲在多臺機器上,利用多臺機器的磁盤空間來承載這么大的數(shù)據(jù)量。
而且,需要保證每臺機器上對這個index存儲的數(shù)據(jù)量不要太大,因為控制單臺機器上這個index的數(shù)據(jù)量,可以保證他的搜索性能更高。
所以這里就引入了一個概念:Shard數(shù)據(jù)分片結(jié)構(gòu)。每個index你都可以指定創(chuàng)建多少個shard,每個shard就是一個數(shù)據(jù)分片,會負責存儲這個index的一部分數(shù)據(jù)。
比如說index里有3億帖子,占據(jù)3TB數(shù)據(jù)。然后這個index你設(shè)置了3個shard。
那么每個shard就可以包含一個1TB大小的數(shù)據(jù)分?片,每個shard在集群里的一臺機器上,這樣就形成了利用3臺機器來分布式存儲一個index的數(shù)據(jù)的效果了。
大家看下面的圖:
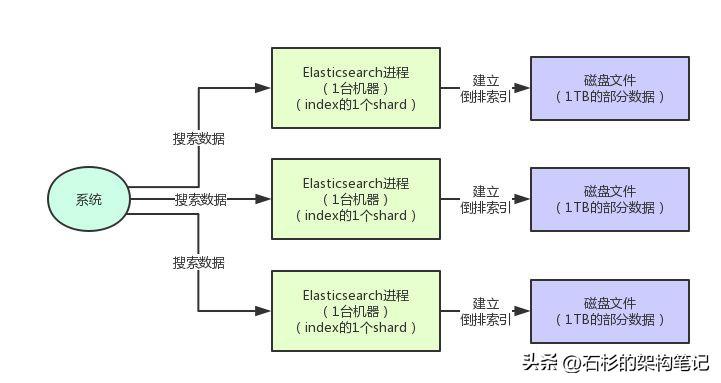
現(xiàn)在index里的3TB數(shù)據(jù)分布式存儲在了3臺機器上,每臺機器上有一個shard,每個shard負責管理這個index的其中1TB數(shù)據(jù)的分片。
而且,另外一個好處是,假設(shè)我們要對這個index的3TB數(shù)據(jù)運行一個搜索,是不是可以發(fā)送請求到3臺機器上去?
3臺機器上的shard直接可以分布式的并行對一部分數(shù)據(jù)進行搜索,起到一個分布式搜索的效果,大幅度提升海量數(shù)據(jù)的搜索性能和吞吐量。
五、Replica多副本數(shù)據(jù)冗余機制
但是現(xiàn)在有一個問題,假如說3臺機器中的其中一臺宕機了,此時怎么辦呢?
是不是這個index的3TB數(shù)據(jù)的1/3就丟失了?因為上面有1TB的數(shù)據(jù)分片沒了。
所以說,還需要為了實現(xiàn)高可用使用Replica多副本數(shù)據(jù)冗余機制。
在Elasticsearch里,就是支持對每個index設(shè)置一個replica數(shù)量的,也就是每個shard對應(yīng)的replica副本的數(shù)量。
比如說你現(xiàn)在一個index有3個shard,你設(shè)置對每個shard做1個replica副本,那么此時每個shard都會有一個replica shard。
這個初始的shard就是primary shard,而且primary shard和replica shard是絕對不會放在一臺機器上的,避免一臺機器宕機直接一個shard的副本也同時丟失了。
我們再來看下面的圖,感受一下:
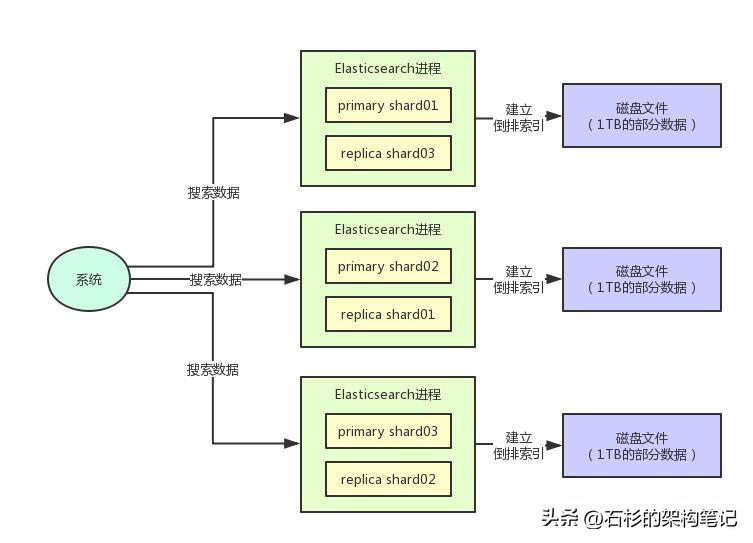
在上述的replica機制下,每個primary shard都有一個replica shard在別的機器上,任何一臺機器宕機,都可以保證數(shù)據(jù)不會丟失,分布式搜索引擎繼續(xù)可用。
Elasticsearch默認是支持每個index是5個primary shard,每個primary shard有1個replica shard作為副本。
六、文末總結(jié)
好了,本文到這兒就結(jié)束了,再來給大伙簡單小結(jié)。
我們從搜索引擎的倒排索引開始,到單機無法承載海量數(shù)據(jù),再到分布式搜索引擎的存儲和搜索。
然后我們以優(yōu)秀的分布式搜索引擎ES為例,闡述了ES的數(shù)據(jù)結(jié)構(gòu),shard數(shù)據(jù)分片機制,replica多副本機制,解釋了一下分布式搜索引擎的架構(gòu)原理。
最后還是強調(diào)一下,在Java面試尤其是高級Java面試中,對于分布式搜索引擎技術(shù)的考察越來越重,所以這塊技術(shù)的重要性,還是不容小覷的!