













流式數據庫的四個關鍵設計原則和保證
實時數據處理是運行以現代技術為導向的業務的基礎方面。客戶比以往任何時候都想要更快的結果,并且會在獲得更快結果的絲毫機會上背叛。因此,如今的組織都在不斷地尋求減少響應的毫秒數。
實時處理接管了之前使用批處理處理的大部分方面。實時處理需要對傳入的數據流執行業務邏輯。這與將數據存儲在數據庫中然后執行分析查詢的傳統方式形成鮮明對比。此類應用程序無法承受先將數據加載到傳統數據庫然后再執行查詢所涉及的延遲。這為流式數據庫奠定了基礎。流式數據庫是可以接收高速數據并在移動中處理它們的數據存儲,而無需混合使用傳統數據庫。它們不是傳統數據庫的直接替代品,但擅長處理高速數據。本文將涵蓋流式數據庫的四個關鍵設計原則和保證。
了解流式數據庫
流式數據庫是可以實時收集和處理傳入的一系列數據點(即數據流)的數據庫。傳統數據庫存儲數據并期望用戶執行查詢以根據最新數據獲取結果。在實時處理是關鍵標準的現代世界中,等待查詢不是一種選擇。相反,查詢必須連續運行并始終返回最新數據。流式數據庫促進了這一點。
在流式數據庫的情況下,查詢不會被執行而是被注冊,因為執行永遠不會完成。它們運行無限長的時間,對傳入的更新數據做出反應。應用程序還可以及時查詢以了解數據如何隨時間變化。
與傳統數據庫相比,流式數據庫在撰寫本文時完成所有工作。實現這一目標面臨著許多挑戰。其一,人們對傳統數據庫的期望最低限度的持久性和正確性。當數據始終處于動態狀態時,保持這種持久性和正確性需要復雜的設計。然后是使用戶能夠查詢動態數據的挑戰。SQL 長期以來一直是所有查詢要求的標準。流式數據庫自然也支持 SQL,但是當數據總是在移動時,實現窗口、聚合等結構很復雜。
持久查詢是對移動數據進行操作的查詢。它們無限期地運行并不斷產生輸出行。無休止的查詢對更新邏輯提出了獨特的挑戰。關鍵問題是關于用改進的查詢替換查詢時的行為——它是對到那時到達的所有數據進行操作,還是只對下一組數據進行操作?第一種操作模式的名稱是backfill,后者是exactly-once processing。要實現 exactly-once 處理,執行引擎必須有一個本地存儲。有時,查詢可以提供給其他數據流。這樣的操作稱為級聯模式。
現在概念已經清楚了,讓我們花點時間了解流式數據庫的架構細節。流式數據庫通常構建在基于生產者-消費者范式工作的流處理系統之上。生產者是創建事件的實體。消費者消費事件并處理它們。通常將事件分組為主題的邏輯分區,以方便業務邏輯的實現。
它們之間有一個經紀人,負責確保生產者和消費者所需的流和格式轉換的可靠性。Broker通常分布在一個分布式平臺上,以保證高可用性和健壯性。流查詢引擎駐留在處理平臺之上。還存在將 SQL 查詢轉換為流處理邏輯的 SQL 抽象層。將所有內容拼接在一起,架構如下所示。
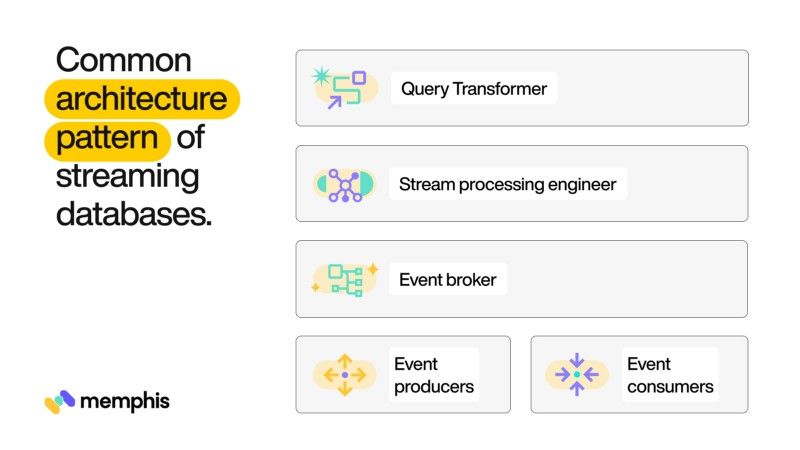
現在我們了解了流式數據庫和持久查詢的概念,讓我們花一些時間了解它們的典型用例。
物聯網平臺
物聯網平臺處理從世界各地的設備推送的大量事件。他們需要根據實時處理生成警報,并在反應時間方面有嚴格的 SLA。IoT 平臺還需要永久存儲所有接收到的事件,并需要基于窗口的流數據聚合以進行分析。流式數據庫和持久查詢非常適合這里。
事件溯源
事件溯源是一種范例,其中根據隨時間發生的事件而不是實體的最終狀態來執行應用程序邏輯。這有助于提高應用程序的持久性和可靠性,因為可以通過回復事件隨時重新創建應用程序狀態。這在審計跟蹤是強制性要求的情況下很有用。
點擊流分析
點擊流分析平臺處理作為應用程序使用的一部分生成的點擊事件。來自點擊事件的數據有時會直接輸入機器學習模型,為客戶提供推薦和建議。持續事件和點擊流的實時處理是運行電子商務等業務的重要組成部分。
交易系統
交易系統每秒處理數百萬個交易請求,并將它們與需求和供應方程式進行匹配以結算交易。在這種情況下,審計跟蹤是一項強制性要求,即使是最輕微的延誤也會給相關各方造成巨大的經濟損失。
欺詐檢測系統
欺詐檢測系統一旦檢測到與典型的欺詐開始非常匹配的場景,就需要立即采取行動。他們還必須記錄觸發警報和事件發生后的后續事件。考慮一個金融系統欺詐檢測系統,它根據合法所有者的消費模式檢測欺詐。它需要實時將事件的特征提供給欺詐檢測模型,并在標記可能的違規行為時立即采取行動。實時數據庫是實現此類用例的絕佳解決方案。
IT系統監控
集中監控幫助組織保持其 IT 系統始終運行流式數據庫通常用于從系統收集日志并在滿足特定條件時生成警報。通過事件存儲生成的實時警報和審計跟蹤是可觀察系統實施的關鍵要素。
流式數據庫市場并不擁擠,只有少數數據庫經得起考驗來處理生產工作負載。Kafka、Materialise、Memgraph 等是一些穩定的。選擇一個適合用例的工具需要仔細比較它們的特性和用例剖析。
現在讓我們將注意力轉移到學習流式數據庫背后的關鍵數據庫設計原則和保證上。
4個關鍵的流式數據庫設計原則和保證
數據庫系統的完整性通常用數據庫是否符合 ACID 標準來表示。ACID 投訴構成了良好數據庫設計原則的基礎。ACID 合規性代表原子性、一致性、隔離性和持久性。原子性是指保證邏輯操作的一組語句部分在其中一條語句出錯的情況下優雅地失敗。這樣的一組語句稱為事務。在流式數據庫的早期,事務支持和原子性常常缺失。但是較新的版本確實支持事務。
一致性是指遵守數據庫強制執行的規則,如唯一鍵約束、外鍵約束等。如果結果狀態不遵守這些規則,一致的數據庫將恢復事務。隔離是單獨事務執行的概念,這樣一個事務不會影響另一個事務。這使得事務的并行執行成為可能。像 KSQLDB 這樣的數據庫支持查詢的強一致性和并行執行。耐用性是指從故障點恢復。該架構的分布式特性確保了現代流式數據庫的強大持久性。
在流式數據庫的情況下,保證是指處理事件的保證。由于數據是不斷移動的,因此很難保證事件處理的順序或避免重復處理。確保所有數據只處理一次是一項昂貴的操作,并且需要狀態存儲和確認。同樣,在分布式應用程序的情況下,確保消息以與接收消息相同的順序進行處理需要復雜的體系結構。
現在讓我們看看核心設計原則以及它們是如何在流式數據庫中實現的。
1.自動恢復
對于流式數據庫,自動恢復是最關鍵的數據庫設計原則之一。流式數據庫用于高度監管的領域,如醫療保健、金融系統等。在這些領域,沒有任何借口可以失敗,并且事故可能導致巨大的金錢損失甚至生命損失。想象一下作為醫療保健物聯網平臺的一部分集成的流式數據庫。傳感器監測患者的重要參數并將它們發送到云端托管的流式數據庫。這樣的系統永遠不會宕機,基于閾值生成警報的查詢應該無限期地運行。
由于流式數據庫不會出現故障,因此它們通常基于分布式架構來實現。基于節點集群設計的流式數據庫提供了很好的容錯能力,因為即使少數節點出現故障,系統的其余部分仍然可以接受查詢。這種容錯必須在開發周期的早期納入流式數據庫的設計中。現在讓我們看看流式數據庫自動恢復中涉及的關鍵活動。
分布式流式數據庫中的自動恢復涉及以下活動:
- 故障檢測
- 重新平衡和智能路由
- 最終恢復
故障檢測是自動恢復的第一步。系統必須有足夠的自我意識來檢測故障情況,以便它可以采取必要的步驟進行恢復。在分布式系統中,故障檢測通常是通過心跳機制來完成的。心跳是一個周期性的輕量級消息,節點發送給集群的每個節點或集群的主節點。這讓其他人知道它還活著。如果沒有收到來自節點的心跳消息,系統會認為它已經死亡并啟動恢復程序。心跳消息的大小、其中捆綁的信息以及心跳消息的頻率對于優化資源很重要。非常頻繁的心跳有助于更早地檢測到故障,但它也會耗費處理時間并產生開銷。
當分布式系統中發生節點故障時,該節點擁有的資源必須重新平衡到其他節點。分布式系統使用受控復制來確保即使在一些節點出現故障時數據也不會丟失。一旦一個節點出現故障,系統會確保數據在其他節點之間重新平衡,并盡可能保持復制策略以降低數據丟失的風險。
要維護高可用性流式數據庫,僅在部分故障期間進行重新平衡是不夠的。由于在流式數據庫的情況下查詢始終在運行,因此系統需要確保它們保持運行。這就是智能路由的用武之地。智能路由有助于確保查詢保持運行并返回結果。使用故障節點上的資源的查詢被無縫地路由到其他節點。這需要仔細設計,并且是流式數據庫基本要求的一部分。
最終恢復涉及恢復在事件中丟失的狀態存儲。狀態存儲需要確保系統滿足用戶配置的約束恰好一次、至多一次或至少處理保證。分布式數據庫通常使用無限日志作為事實來源。他們還使用單獨的主題,將時間偏移量作為恢復機制。如果發生故障,此時間偏移主題可用于重新創建事件的時間線。
2.恰好一次語義
對于流式數據庫,故障情況下的自動恢復是不夠的。與傳統數據庫設計不同,流式數據庫設計應確保在故障期間丟失的結果不影響下游消費者。實現這一點有幾個方面。首先,系統需要保證沒有記錄漏處理。這可以通過重新處理所有記錄來完成,但存在風險。其一,沒有充分考慮的重新處理可能導致記錄被處理不止一次。這會導致不準確的結果。例如,考慮相同的醫療保健 IOT 平臺,其中警報是決定生命的警報。重復處理會導致重復警報,從而造成資源浪費。重復處理也會導致聚合結果,如平均值、百分位計算等。
根據要求,有時,事件處理中的一些錯誤可能是可以接受的。流式數據庫定義了不同的消息處理保證以支持具有不同需求的用例。可以使用三種類型的消息保證——至多一次、至少一次和恰好一次。Utmost once 保證定義了消息永遠不會被處理超過一次的情況,但有時可能會錯過處理。至少一次保證定義了允許重復處理但不接受丟失記錄的情況。
Exactly once 語義保證一條消息只被處理一次,并且結果足夠準確,以至于消費者不會注意到失敗事件。讓我們借助圖表來探討這個概念。
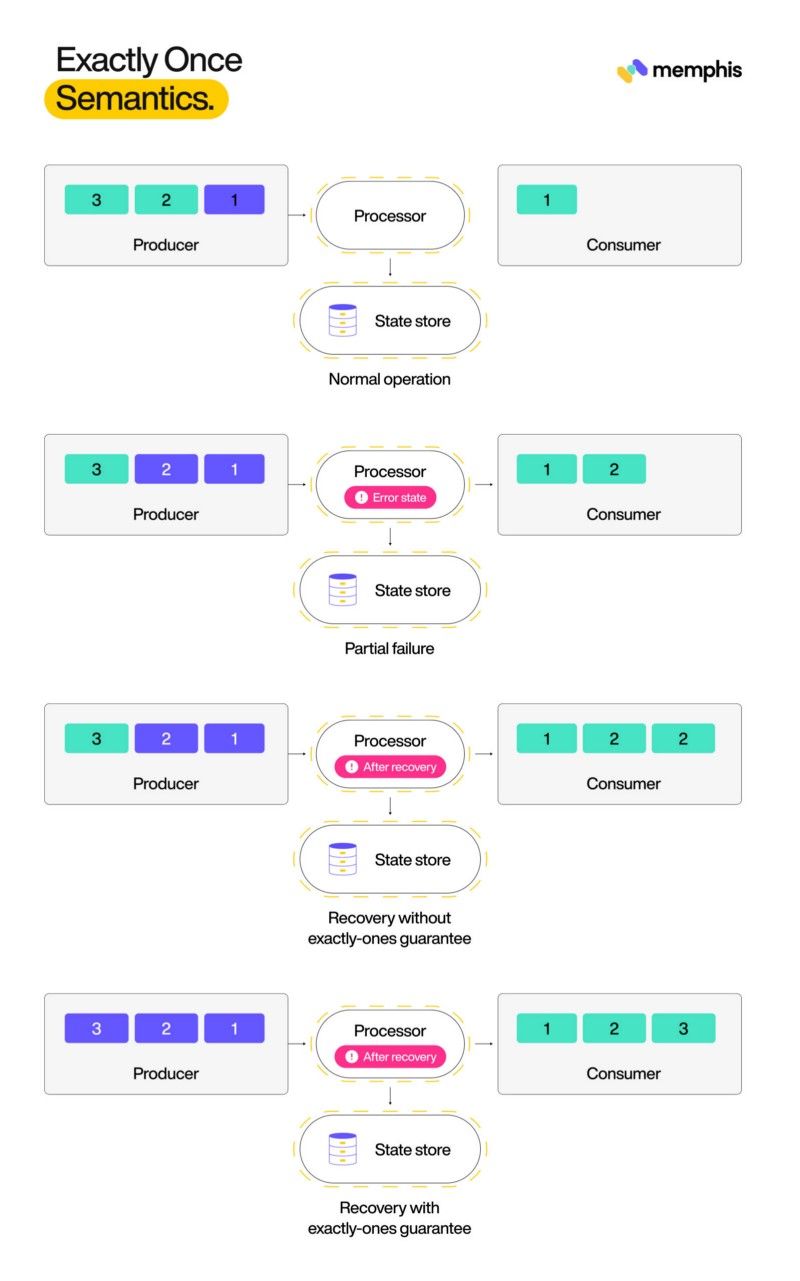
假設系統正在處理按順序發送的消息。為了表示,消息在此處從 1 開始排序。處理器接收消息,根據邏輯進行轉換或聚合,傳遞給消費者。在上圖中,綠色表示尚未處理的消息,紅色表示已處理的消息。每次處理消息時,處理器都會使用偏移量更新狀態存儲。這是為了在發生故障時啟用恢復。現在假設處理器在處理第二條消息后發生錯誤并崩潰。當處理器恢復時,它必須從 3 而不是從消息 2 重新開始處理。它應該避免對狀態存儲進行重復更新或將消息 2 的結果再次提供給消費者。
換句話說,系統從結果的角度和系統間通信的角度都掩蓋了故障。這需要生產者、消息系統和消費者根據約定的合同進行合作。消息傳遞確認是可以幫助流式數據庫完成此操作的最簡單的保證。合約應該能夠承受代理故障、生產者與代理之間的通信故障,甚至是消費者故障。
3.處理故障記錄
良好的數據庫設計將處理無序記錄視為一個關鍵方面。由于多種原因,流式數據庫會遇到亂序記錄。原因包括網絡延遲、生產者不可靠、時鐘不同步等。由于它們用于高度敏感的應用程序,如金融和醫療保健,處理順序非常重要,流式數據庫必須優雅地處理它們。為了更好地理解這個問題,讓我們考慮同一個物聯網醫療保健平臺的例子。假設由于短暫的互聯網連接失敗,其中一臺設備在短時間內無法發送數據。當它恢復時,它從恢復時間開始發送數據。一段時間后,設備中的固件發送了之前未能發送的其余數據。
為了更好地了解上下文,讓我們現在使用圖表來解釋這個問題。下圖有一個生產者,它發送的消息的編號從 1 開始。綠色塊代表尚未發送的事件,紅色塊代表此處已發送的事件。當消息。1,2, 3 按時間戳順序到達;一切安好。但是,如果其中一條消息在途中或從源本身延遲,則會導致流媒體平臺的結果損壞。在這種情況下,消息1和3早于2到達。流媒體平臺在1和3之后收到2,但必須保證下游消費者按實際順序收到消息。
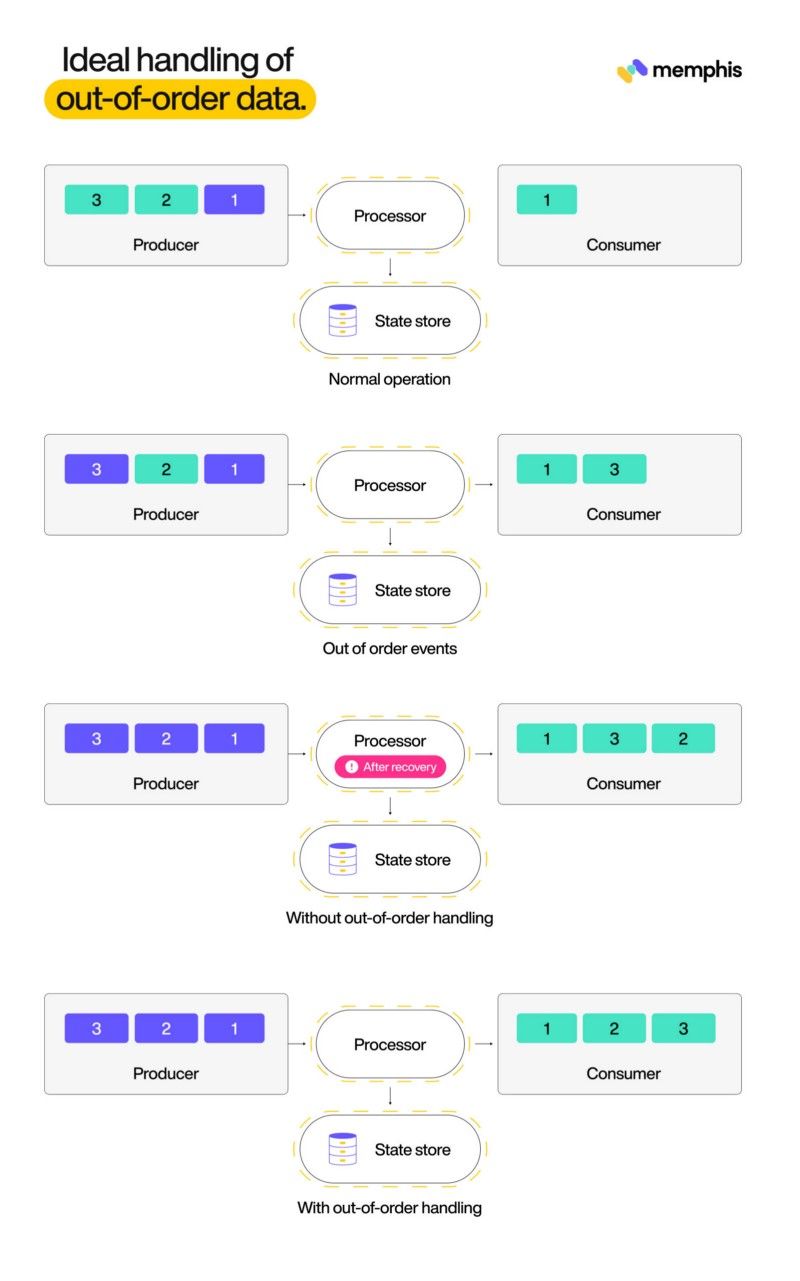
如果亂序記錄沒有得到妥善處理,處理記錄的流式數據庫將向下游系統提供不準確的結果。例如,假設消息表示一個溫度值,并且有一個持久查詢可以找到最后一分鐘的平均溫度。延遲的溫度值會導致錯誤的平均值。流式數據庫以兩種方法處理這些情況。第一種方法涉及一個配置參數,該參數定義處理器在每個微批處理開始之前等待無序記錄到達的時間量。微批次是一組記錄,它們是實時查詢的一部分。微批處理的概念是持久查詢的基礎。
解決亂序記錄的第二種方法是允許處理器更新已經計算的結果。這需要與消費者達成協議。這個概念與事務的概念直接沖突,因此在實現時需要仔細設計。這僅適用于下游消費者即使以不同順序接收輸入也能夠產生相同輸出的情況。例如,如果下游消費者的輸出是一個允許修改的表,那么流式數據庫就可以使用這種策略。
4. 一致的查詢結果
實現流式數據庫通常基于分布式架構。傳統的數據庫設計原則將原子性和一致性視為良好數據庫設計的關鍵支柱。但是在流式數據庫的情況下,由于分布式的特性,很難實現寫入的一致性。考慮一個使用復制分區概念并部署在節點集群上的流式數據庫。收入流將根據存儲模式進入不同的分區或節點。為確保真正的寫入一致性,需要確保只有在所有分區都反映成功時才確認流。當有多個消息作為邏輯事務的一部分時,這很困難。
確保寫入一致性的困難也會影響到讀取一致性。只有讀取一致,才有可能返回一致的查詢結果。考慮充當多個持久查詢的數據源的流,該查詢根據不同的業務邏輯聚合流。流式數據庫必須確保兩個查詢都作用于單一的真實來源,并且查詢的結果反映不沖突的值。這是一個極其困難的命題,因為為了處理亂序的記錄,大多數數據庫都以持續更新的模式運行,經常會改變它們之前計算的結果。在串聯查詢的情況下,此類更新會在不同時間滴入下游流,并且一些派生查詢狀態可能反映不同的源數據狀態。
有兩種方法可以解決查詢結果的一致性問題。第一種方法通過確保在來自該流的所有查詢完成之前不確認寫入來解決這個問題。這對生產者而言是昂貴的。因為為了滿足 exact once 處理要求,大多數流式數據庫依賴于代理和生產者之間的確認。如果僅在查詢完成后才確認所有寫入,那么生產者將被蒙在鼓里的時間更長。這種方法是 block-on-write 方法。
解決一致性的第二種方法是在查詢引擎級別進行。在這里,查詢引擎延遲需要強一致性保證的特定查詢的結果,直到所有寫入都得到確認。這比第一種方法更便宜,因為輸入流的寫入性能不受影響。這種方法不是延遲確認作為查詢基礎的輸入流,而是在查詢級別運行。因此,如果查詢不需要強一致性保證,則該查詢的結果將比依賴于相同輸入流的其他查詢更早發出。因此,不同的查詢根據其一致性配置對同一輸入流的不同版本進行操作。
流式數據庫必須在數據的陳舊性和一致性級別之間取得平衡,以優化性能。提高一致性級別可能會導致處理速度降低,反之亦然。
結論
流式數據庫是實時處理應用程序的基礎。它們不是傳統數據庫的替代品,而是有助于滿足需要對永無止境的數據流進行始終在線處理的獨特需求。設計流式數據庫是一項復雜的任務,因為在處理流式數據時存在一些限制。實現讀取一致性、處理亂序數據、確保恰好一次處理和自動恢復是設計流式數據庫時考慮的典型設計原則。


















