谷歌復用30年前經典算法,CV引入強化學習,網友:視覺RLHF要來了?
ChatGPT 的火爆有目共睹,而對于支撐其成功背后的技術,監督式的指令微調以及基于人類反饋的強化學習至關重要。這些技術也在逐漸擴展到其他 AI 領域,包括計算機視覺(CV)。?
我們知道,在處理計算機視覺中的復雜輸出時,成功的主要標準不在于模型對訓練目標的優化程度,而在于預測能力與任務的吻合程度,即模型在預期用途上的表現效果。
為了追求這種一致性,有研究者在模型架構、數據、優化、采樣、后處理等方面進行了一些改進。例如,在物體檢測任務中,研究人員使用了 NMS(non-maximum suppression )、基于集合的全局損失(set-based global loss)以及改變輸入數據來獲得在測試時具有改進行為的模型。雖然這些方法帶來了顯著的收益,但它們往往只對特定任務有用,僅僅是間接地對任務風險進行了優化。?
不僅 CV,包括自然語言處理(NLP)、強化學習(RL)等領域也在廣泛研究這一現象。在這些領域中,對于目標不太明確的任務,如翻譯或生成摘要,制定優化目標非常困難。在處理這類問題時,一種流行的方法是學習模仿例子的輸出,然后進行強化學習,使模型與獎勵函數保持一致。使用這種方法,NLP 領域產生了令人興奮的結果,該方法使用大型預訓練語言模型和由人類反饋定義的獎勵來處理原本難以指定的任務。
此外,同樣的方法被廣泛用于圖像字幕任務中,其中 CIDEr(Vedantam 等人 2015 年提出)被用來作為獎勵。盡管如此,據了解,獎勵優化以前還沒有在(非文本)計算機視覺任務中進行過探索。
近日,谷歌大腦團隊的研究者在論文《Tuning computer vision models with task rewards》中證明了,使用 REINFORCE 算法(Williams 于 1992 提出)來調整(Tuning)具有獎勵函數的預訓練模型可以開箱即用地用于各種計算機視覺任務。
其實許多關于強化學習任務的研究都會提及 Williams 的 REINFORCE 算法,可見這個算法的重要性。可以說 REINFORCE 算法是策略梯度乃至強化學習的典型代表。
論文地址:https://arxiv.org/pdf/2302.08242v1.pdf?
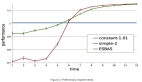
圖 1 展示了一些關鍵結果,主要包括目標檢測、全景分割和圖像著色的獎勵優化帶來的定量和定性改進。該研究所提出的方法在處理各種 CV 任務上簡單而有效,證明了它的多功能性和適應性。盡管本文主要采用評估指標形式的獎勵,但這些初步結果顯示了該方法用來優化計算機視覺模型也不失為一種有效途徑,這些模型具有更復雜和更難指定的獎勵,例如人的反饋或整體系統性能。

推特網友對這篇文章給了一個比較全面的總結,即本文實現的功能是使用 RL 調整預訓練視覺模型。研究的動因是受到 LLM 強化學習成功的啟發;其效果是在目標檢測、全景分割等方面性能大幅提升。并表示,這項研究可能是實現視覺 RLHF (Reinforcement Learning from Human Feedback)的有效途徑。

圖源:https://twitter.com/johnjnay/status/1627009121378598912
獎勵?
在不喪失泛化性的情況下,該研究將 CV 任務描述為學習一個函數的過程,該函數將輸入 x(即圖像)映射到輸出 y = [y_1, y_1,……, y_n](文本 token 序列、bounding box 序列等)。該研究旨在學習以 θ 為參數的條件分布 P (y|x, θ),使獎勵函數 R 最大化。用抽象的公式來形容,就是本文要解決以下優化問題。

問題有了,接下來就是怎么解決了,本文分兩步走:首先用最大似然估計對模型進行預訓練;然后使用 REINFORCE 算法對模型進行 Tuning 。下面我們看看這兩步的具體過程:
最大似然預訓練?
首先使用最大似然原理估計參數 θ 并捕獲訓練數據的分布。實現這一目標可采用梯度下降算法,該算法通過最大化訓練數據的 log-likelihood
 來實現。算法 1 和圖 2 描述了 MLE(最大似然估計)優化步驟,這是訓練模型最常用的方法。完成這一步將得到 MLE 模型。
來實現。算法 1 和圖 2 描述了 MLE(最大似然估計)優化步驟,這是訓練模型最常用的方法。完成這一步將得到 MLE 模型。

REINFORC 算法將獎勵最大化 ?
為了更好的優化 MLE 模型以適應任務風險,還需要最大化獎勵函數。對于給定輸入 x,該研究利用 REINFORCE 算法來估計對給定 x 期望獎勵的梯度,公式如下所述:

算法 2 提供了偽代碼,圖 3 說明了該過程:


實驗結果
接下來我們看看本文提出的方法在視覺任務上的表現。
全景分割
如下表 1 所示,Tuning 過程顯著改善了 MLE 模型。視覺檢查(visual inspection)后的結果表明,Tuning 后的模型在避免不連貫預測方面更好,特別是對于小尺度物體,可參見圖 1。

目標檢測
表 2 顯示,通過優化,該研究將原始 MLE 模型的 mAP 分數從 39.2% 大幅提高到 54.3%。在 Pix2seq 中,具有稍大的 1333×1333 分辨率和許多啟發式的相同大小的 ViT-B 模型達到了 47.1%。當使用更大的 ViT-L 主干時,Pix2seq 報告的最佳目標檢測結果為 50.0%。

上色?
圖 4 給出的定性結果清楚地表明,新模型始終能產生更豐富多彩的圖像。

圖像描述

表 3 結果表明,應用所提出的方法可以改進 MLE 模型,這與先前文獻中的觀察結果一致,證明了該方法針對特定任務風險進行 tuning 的有效性。