谷歌實現2種新的強化學習算法,“比肩”DQN,泛化性能更佳
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
強化學習(RL)算法持續“進化”中……
來自Google Research的研究人員,證明可以使用圖表示 (graph representation)和AutoML的優化技術,來學習新的、可解析和可推廣的RL算法!
他們發現的其中兩種算法可以推廣到更復雜的環境中,比如具有視覺觀察的Atari游戲。
這一成就使得RL算法越來越優秀!
具體怎么個“優秀法”,請看下文:
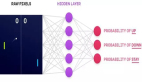
損失函數表示為計算圖
首先,對于強化學習算法研究的難點,研究人員認為,一種可能的解決方案是設計一種元學習方法。
該方法可以設計新的RL算法,從而自動將其推廣到各種各樣的任務中。
受神經架構搜索(NAS)在表示神經網絡結構的圖空間中搜索的思想啟發,研究人員通過將RL算法的損失函數表示為計算圖(computational graph)來元學習RL算法。
其中使用有向無環圖來表示損失函數,該圖帶有分別表示輸入、運算符、參數和輸出的節點。
該表示方法好處有很多,總的來說就是可用來學習新的、可解析和可推廣的RL算法。
并使用PyGlove庫實現這種表示形式。
基于進化的元學習方法
接下來,研究人員使用基于進化的元學習方法來優化他們感興趣的RL算法。
其過程大致如下:
新提出的算法必須首先在障礙環境中表現良好,然后才能在一組更難的環境中進行訓練。算法性能被評估并用于更新群體(population),其中性能更好的算法進一步突變為新算法。在訓練結束時,對性能最佳的算法在測試環境中進行評估。
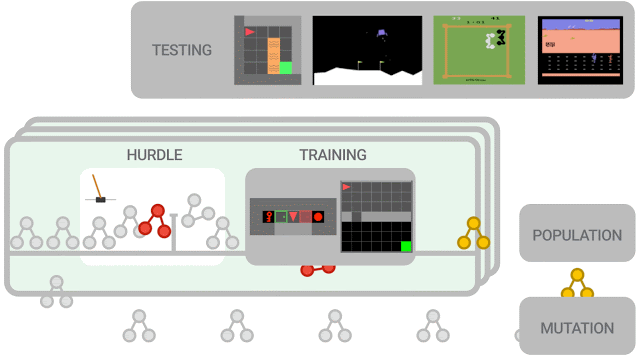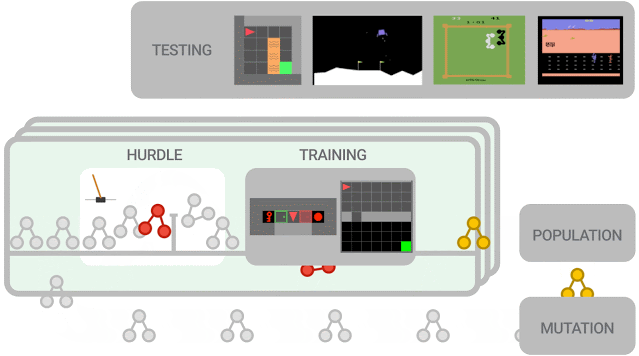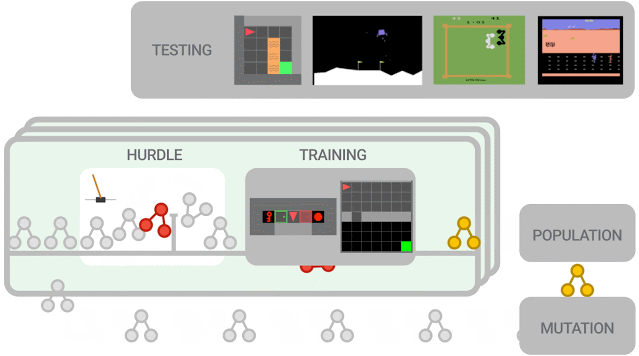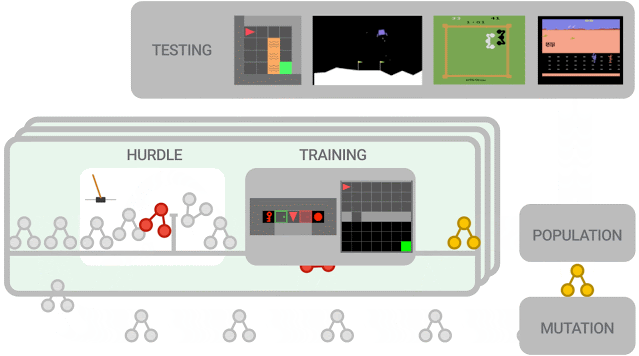
本次實驗中的群體(population)規模約為300個智能體,研究人員觀察到在2-5萬個突變后,發現候選損失函數的進化需要大約3天的訓練。
為了進一步控制訓練成本,他們在初始群體中植入了人類設計的RL算法,eg. DQN(深度Q學習算法)。
發現兩種表現出良好泛化性能的算法
最終,他們發現了兩種表現出良好泛化性能的算法:
一種是DQNReg,它建立在DQN的基礎上,在Q值上增加一個加權懲罰(weighted penalty),使其成為標準的平方Bellman誤差。
第二種是DQNClipped,盡管它的支配項(dominating term)有一個簡單的形式——Q值的最大值和平方Bellman誤差(常數模),但更為復雜。
這兩種算法都可以看作是正則化Q值的一種方法,都以不同的方式解決了高估Q值這一問題。
最終DQNReg低估Q值,而DQNClipped會緩慢地接近基本事實,更不會高估。
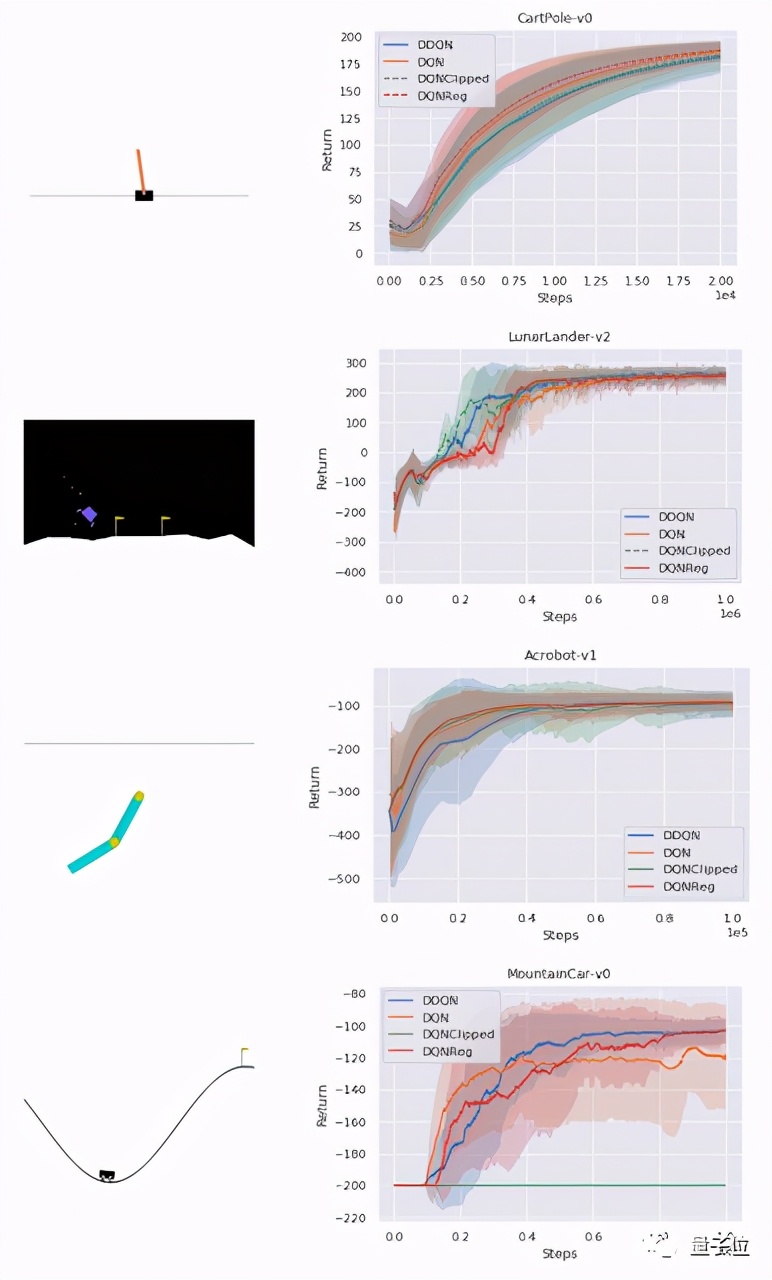
性能評估方面,通過一組經典的控制環境,這兩種算法都可以在密集獎勵任務(CartPole、Acrobot、LunarLander)中持平基線,在稀疏獎勵任務(MountainCar)中,性能優于DQN。
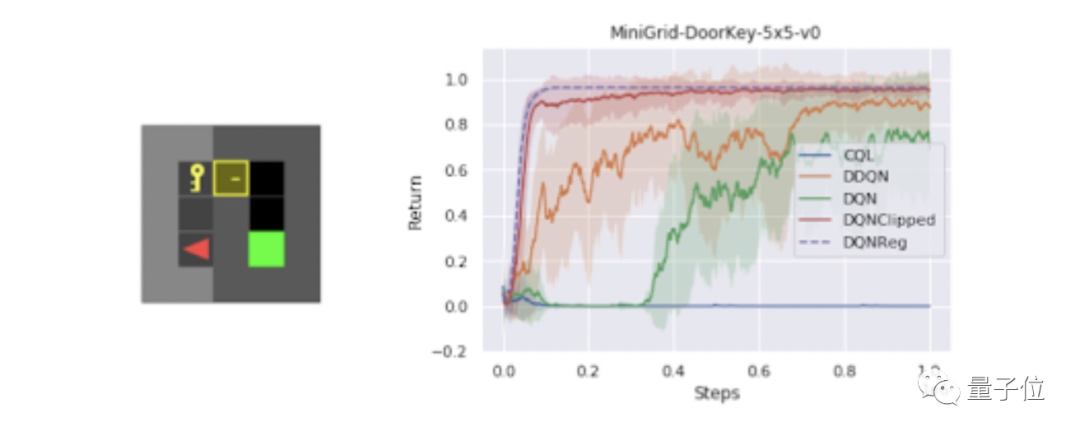
其中,在一組測試各種不同任務的稀疏獎勵MiniGrid環境中,研究人員發現DQNReg在訓練和測試環境中的樣本效率和最終性能都大大優于基線水平。
另外,在一些MiniGrid環境將DDQN(Double DQN)與DQNReg的性能進行可視化比較發現,當DDQN還在掙扎學習一切有意義的行為時,DQNReg已經可以有效地學習最優行為了。
最后,即使本次研究的訓練是在基于非圖像的環境中進行的,但在基于圖像的Atari游戲環境中也觀察到DQNReg算法性能的提高!
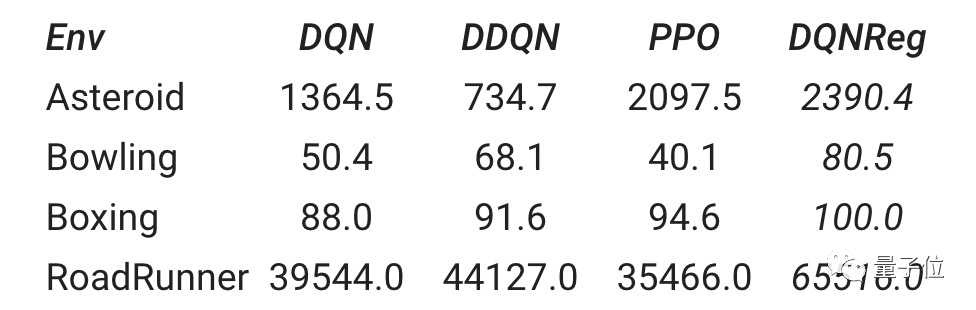
這表明,在一組廉價但多樣化的訓練環境中進行元訓練,并具有可推廣的算法表示,可以實現根本的算法推廣。
此研究成果寫成的論文,已被ICLR 2021接收,研究人員門未來將擴展更多不同的RL設置,如Actor-Critic算法或離線RL。