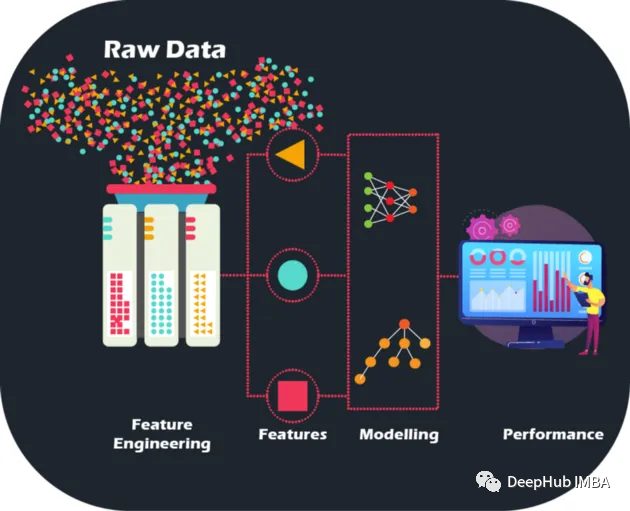
通過對原始數據進行手工的特征工程,我們可以將模型的準確性和性能提升到新的水平,為更精確的預測和更明智的業務決策鋪平道路, 可以以前所未有的方式優化模型并提升業務能力。

原始數據就像一個沒有圖片的拼圖游戲——但通過特征工程,我們可以將這些碎片拼在一起,雖然擁有大量數據確實是尋求建立機器學習模型的金融機構的寶庫,但同樣重要的是要承認并非所有數據都提供信息。并且手工特征是人工設計出來,每一步操作能夠說出理由,也帶來了可解釋性。
特征工程不僅僅是選擇最好的特征。它還涉及減少數據中的噪音和冗余,以提高模型的泛化能力。這是至關重要的,因為模型需要在看不見的數據上表現良好才能真正有用。
數據集描述
本文中描述的數據集經過匿名處理和屏蔽,以維護客戶數據的機密性。特征可分類如下:
D_* = 拖欠變量
S_* = 支出變量
P_* = 支付變量
B_* = 平衡變量
R_* = 風險變量
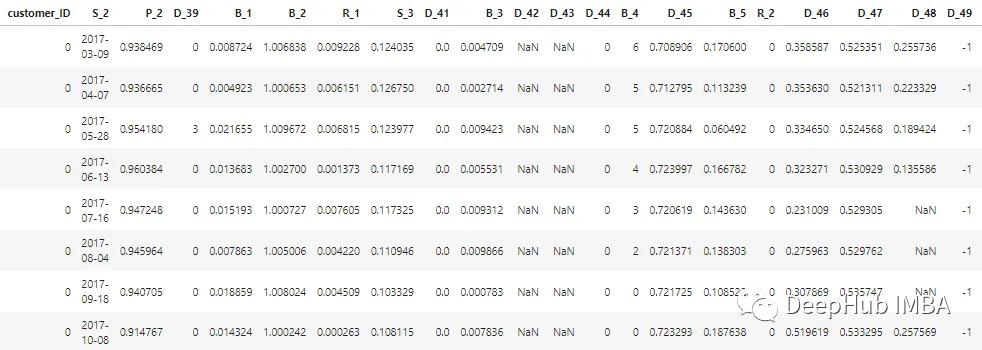
總共有 100 個整數特征和 100 個浮點特征代表過去 12 個月客戶的狀態。該數據集包含有關客戶報表的信息,從 1 到 13 不等。客戶的每張信用卡報表之間可能有 30 到 180 天的間隔(即客戶的信用卡報表可能缺失)。每個客戶都由一個客戶 ID 表示。customer_ID=0的客戶前5條的樣本數據如下所示:
在 700 萬個 customer_ID 中,98% 的標簽為“0”(好客戶,無默認),2% 的標簽為“1”(壞客戶,默認)。
數據集很大,所以我們使用cudf來加速處理,如果你沒有安裝cudf,那么使用pandas也是一樣的
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
df = cudf.read_parquet('./data.parquet')
特征生成方法
有數百種想法可用于生成特征;但是我們還確保這些特征有助于提高模型的性能,下圖顯示了特征工程中使用的一些基本方法:

聚合特征
聚合是理解復雜數據的秘訣。通過計算分類分組變量(如 customer_ID (C_ID) 或產品類別)的匯總統計數據或數值變量的聚合,我們可以發現一些不可見的模式和趨勢。借助均值、最大值、最小值、標準差和中值等匯總統計數據,我們可以構建更準確的預測模型,并從客戶數據、交易數據或任何其他數值數據中提取有意義的見解。
可以計算每個客戶的這些統計屬性
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]
均值:一個數值變量的平均值,可以給出數據集中趨勢的一般意義。平均值可以捕獲:
客戶擁有的平均銀行余額。
- 平均客戶支出。
- 兩個信用報表之間的平均時間(信用付款之間的時間)。
- 借錢的平均風險。
標準偏差 (Std):衡量數據圍繞均值的分布情況,可以深入了解數據的變異程度。余額的高度可變性表明客戶有消費。
最小值和最大值可以捕獲客戶的財富,也可以捕獲有關客戶支出和風險的信息。
中位數:當數據高度傾斜時,使用平均值并不是一個更好的主意,因此可以使用中值(可以使用數值的中間值。
最新值可能是最重要的特征,因為它們包含有關發布給客戶的最新已知信用聲明的信息,也就表明目前客戶賬戶的最新狀態。
獨熱編碼
對分類變量使用上述統計屬性是不明智的,因為計算最小值、最大值或標準偏差并不能給我們任何有用的信息。那么我們應該怎么做呢?可以使用像count這樣的特征,和唯一的數量來計算特征,最新的值也可以使用
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]
但是這些信息不會捕獲客戶是否被歸類到特定的類別中。所以我們通過對變量進行獨熱編碼,然后對變量(例如均值、總和和最后)進行聚合來實現。
平均值將捕獲客戶屬于該類別的總次數/銀行對帳單總數的比率。總和將只是客戶屬于該類別的總次數。
from cuml.preprocessing import OneHotEncoder
df_categorical = df_last[cat_features].astype(object)
ohe = OneHotEncoder(drop='first', sparse=False, dtype=np.float32, handle_unknown='ignore')
ohe.fit(df_categorical)with open("ohe.pickle", 'wb') as f:
pickle.dump(ohe, f) #save the encoder so that it can be used for test data as well df_categorical = pd.DataFrame(ohe.transform(df_categorical).astype(np.float16),index=df_categorical.index).rename(columns=str)
df_categorical['customer_ID']=df['customer_ID']
df_categorical.groupby('customer_ID').agg(['mean', 'sum', 'last'])

基于排名的特征
在預測客戶行為方面,基于排名的特征是非常重要的。通過根據收入或支出等特定屬性對客戶進行排名,我們可以深入了解他們的財務習慣并更好地管理風險。
使用 cudf 的 rank 函數,我們可以輕松計算這些特征并使用它們來為預測提供信息。例如,可以根據客戶的消費模式、債務收入比或信用評分對客戶進行排名。然后這些特征可用于預測違約或識別有可能拖欠付款的客戶。
基于排名的特征還可用于識別高價值客戶、目標營銷工作和優化貸款優惠。例如,可以根據客戶接受貸款提議的可能性對客戶進行排名,然后將排名最高的客戶作為目標。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客戶的排名也可以基于分類特征來計算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
特征組合

特征組合的一種流行方法是線性或非線性組合。這包括采用兩個或多個現有特征,將它們組合在一起創建一個新的復合特征。然后使用這個復合特征來識別單獨查看單個特征時可能不可見的模式、趨勢和相關性。
例如,假設我們正在分析客戶消費習慣的數據集。可以從個人特征開始,比如年齡、收入和地點。但是通過以線性或非線性的方式組合這些特性,可以創建新的復合特性,使我們能夠更多地了解客戶。可以結合收入和位置來創建一個復合特征,該特征告訴我們某一地區客戶的平均支出。
但是并不是所有的特征組合都有用。關鍵是要確定哪些組合與試圖解決的問題最相關,這需要對數據和問題領域有深刻的理解,并仔細分析創建的復合特征和試圖預測的目標變量之間的相關性。
下圖展示了一個組合特征并將信息用于模型的過程。作為篩選條件,這里只選擇那些與目標相關性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
for feat1 in features:
for feat2 in features:
th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate threshold
feat3=df[feat1]-df[feat2] #difference feature
corr3=np.corr(feat3,Y)[0]
if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as feature
df[feat1+'_'+feat2]=feat3
基于時間/日期的特征
在數據分析方面,基于時間的特征非常重要。通過根據時間屬性(例如月份或星期幾)對數據進行分組,可以創建強大的特征。這些特征的范圍可以從簡單的平均值(如收入和支出)到更復雜的屬性(如信用評分隨時間的變化)。
借助基于時間的特征,還可以識別在孤立地查看數據時可能看不到的模式和趨勢。下圖演示了如何使用基于時間的特征來創建有用的復合屬性。
首先,計算一個月內的值的平均值(可以使用該月的某天或該月的某周等),將獲得的DF與原始數據合并,并取各個特征之間的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=df.groupby(month_Agg,notallow='month')
for feat in features: #create composite features b taking difference
df[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']

還可以通過使用時間作為分組變量來創建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
滯后特征
滯后特征是有效預測金融數據的重要工具。這些特征包括計算時間序列中當前值與之前值之間的差值。通過將滯后特征納入分析,可以更好地理解數據中的模式和趨勢,并做出更準確的預測。
如果滯后特征顯示客戶連續幾個月按時支付信用卡賬單,可能會預測他們將來不太可能違約。相反,如果延遲特征顯示客戶一直延遲或錯過付款,可能會預測他們更有可能違約。
# difference function calculate the lag difference for numerical features
#between last value and shift last value.
def difference(groups,num_features,shift):
data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})
return data
#calculate diff features for last -2nd last, last -3rd last, last- 4th last
def get_difference(data,num_features):
print("diff features...")
groups=data.groupby('customer_ID')
df1=difference(groups,num_features,2).fillna(0)
df2=difference(groups,num_features,3).fillna(0)
df3=difference(groups,num_features,4).fillna(0)
df1=pd.concat([df1,df2,df3],axis=1)
df1.reset_index(inplace=True)
df1.sort_values(by='customer_ID')
del df2,df3
gc.collect()
return df1train_diff = get_difference(df, num_features)

基于滾動窗口的特性
這些特征只是取最后3(4,5,…x)值的平均值,這取決于數據,因為基于時間的最新值攜帶了關于客戶最新狀態的信息。
xth=3 #define the window size
df["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()
last_info=df[df["cumulative"]<=xth]
last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
last_info.columns = ['_'.join(x) for x in last_info.columns]
其他的特征提取方法
上面的方法已經創建了足夠多的特征來構建一個很棒的模型。但是根據數據的性質,還可以創建更多的特征。例如:可以創建像null計數這樣的特征,它可以計算客戶當前的總null值,從而幫助捕獲基于樹的算法無法理解的特征分布。
def calc_nan(df,features):
print("calculating nan_info...")
df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zero
df_nan['customer_ID'] = df['customer_ID']
nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customer
nan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not known
del df_nan
gc.collect()
return nan_sum,nan_last
這里可以不使用平均值,而是使用修正的平均值,如基于時間的加權平均值或 HMA(hull moving average)。
總結
在本文中介紹了一些在現實世界中用于預測違約風險的最常見的手工特性策略。但是總是有新的和創新的方法來設計特征,并且手工設置特征的方法是費時費力的,所以我們將在后面的文章中介紹如何實用工具進行自動的特征生成。