譯者 | 崔皓
審校 | 孫淑娟
摘要
本文介紹什么是重采樣以及如何使用重采樣技術提高模型的整體性能。
在使用數據模型時,由于模型的算法不同而導致接受數據時有不同的學習模式。通過這種直觀的學習方式,讓模型通過給定數據集的學習從而找出其中的規律,這個過程稱為訓練模型。
然后,將訓練完畢的模型在測試數據集上測試,這些測試數據是模型之前沒有見過的。實際上,我們希望達到的最佳效果是模型在訓練和測試數據集上都能產生準確的輸出,也就是模型在訓練集和測試集上的表現一致。
你可能也聽說過驗證集的方式。這種方式是將數據集分成兩部分:訓練數據集和測試數據集。一部分的數據被用來訓練模型,而另一部分的數據被用來測試訓練好的模型。
然而,這種驗證集的方法有缺點。
該模型將學習訓練數據集中的所有模式,由于它從來沒有接觸過測試集的數據,因此它可能遺漏測試數據集中的相關信息。這導致模型失去了提高整體性能的重要信息。
另一個缺點是,訓練數據集可能面臨數據中的異常值或錯誤,而模型將學習這些有問題的數據,并將這些數據作為模型知識庫的一部分,然后在第二階段的測試中應用。
那么,我們如何糾正上述的缺點呢?答案是:重新采樣。
什么是重采樣?
重采樣是一種方法,包括從訓練數據集中反復抽取樣本。然后,這些樣本被用來重新擬合一個特定的模型,以檢索更多關于擬合模型的信息。其目的是收集更多關于樣本的信息,提高準確性并估計不確定性。
例如,如果你正在研究線性回歸擬合,并想檢查變異性。就可以重復使用訓練數據中的不同樣本,并對每個樣本進行線性回歸擬合。這將使你能夠檢查結果在不同樣本上的不同表現,從而獲得新的信息。
重新取樣的顯著優勢是,你可以從同一群體中反復抽取小樣本,直到你的模型達到最佳性能。由于能夠循環使用同一個數據集,你將節省大量的時間和金錢,而不必去尋找新的數據。
欠采樣和過度采樣
如果你正在處理高度不平衡的數據集,重采樣是可以提升模型準確率的一種技術。
欠采樣是指從多數類中移除樣本,以提供更多的平衡。
過度采樣是指由于收集的數據不足,從少數類別中復制隨機樣本并充當樣本。
然而,上述的兩種方法都存在劣勢,在取樣不足的情況下刪除樣本會導致信息的損失。從少數類中重復隨機樣本會導致過度擬合。
數據科學中經常使用兩種重抽樣方法:
- Bootstrap法(引導法)
- 交叉驗證法
Bootstrap法
這種方法用在一些不遵循典型正態分布的數據集。因此,可以應用Bootstrap方法來檢查數據集的隱藏信息和分布。
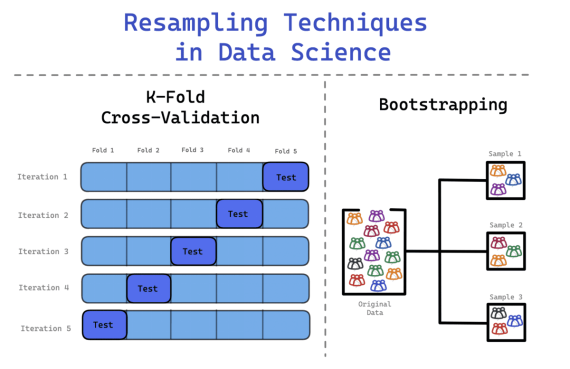
在使用Bootstrap方法時,抽出的樣本會被替換,而不包括在樣本中的數據被用來測試模型。它是一種靈活的統計方法,可以幫助數據科學家和機器學習工程師量化不確定性。
其過程包括如下:
1. 反復從數據集中抽取樣本觀測值
2. 替換這些樣本,以確保原始數據集保持在相同的規模。
3. 一個觀察值可以出現不止一次,也可以完全不出現。
你可能聽說過Bagging,即合集技術。它是Bootstrap Aggregation的簡稱,它結合了Bootstrap和聚合來形成一個集合模型。它創建了多個原始訓練數據集,然后匯總得出最終的預測結果。每個模型都會學習前一個模型的錯誤。
引導法的一個優點是,與上面提到的訓練-測試分割法相比,它們的方差較低。
交叉驗證法
當你重復地隨機分割數據集時,會導致樣本最終進入訓練集或測試集。這可能會不幸地對你的模型產生不平衡的影響,使其無法做出準確的預測。
為了避免這種情況,你可以使用K-Fold交叉驗證法來更有效地分割數據。在這個過程中,數據被分為k個相等的集合,其中一個集合被定義為測試集,而其余的集合則用于訓練模型。這個過程將一直持續到每個集合都作為測試集,并且所有的集合都經過了訓練階段。
其個過程包括:
1. 數據被分割成k個部分。例如,一個數據集被分成10個部分--10個相等的集合。
2. 在第一次迭代中,模型在(k-1)上進行訓練,并在剩余的一組上進行測試。假設每個數據集合都有編號,第一次訓練把1-9號數據集合作為訓練集,把10號集合作為測試集。第二訓練把1-8號集合以及10號集合作為測試集,把9號集合作為測試集。第三次把1-7號集合以及9、10號集合作為訓練集合,把8號集合作為測試集合。
3. 這個過程不斷重復(10次),直到所有的集合都作為測試集合進行訓練為止。
這使每個樣本有平衡的代表性,確保所有的數據都被用來改善模型的學習,以及測試模型的性能。
總結
在這篇文章中,你將了解什么是重采樣,以及如何以3種不同的方式對你的數據集進行采樣:訓練-測試分割、bootstrap和交叉驗證。
所有這些方法的目標是幫助模型以有效的方式吸收盡可能多的信息。確保模型成功學習的唯一方法是在數據集中的各種數據點上訓練模型。
重新采樣是預測性建模階段的一個重要元素;確保準確的輸出、創建高性能的模型和有效的工作流程。
譯者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。
原文標題:??The Role of Resampling Techniques in Data Science??,作者:Nisha Arya