CFS 原理
CFS(Completely Fair Scheduler), 也即是完全公平調度器。
CFS 的產生就是為了在真實的硬件上模擬“理想的多任務處理器”,使每個進程都能夠公平的獲得 CPU。
CFS 調度器沒有時間片的概念,CFS 的理念就是讓每個進程擁有相同的使用 CPU 的時間。比如有 n 個可運行的進程,那么每個進程將能獲取的處理時間為 1/n。
在 CFS 調度器中引用權重來代表進程的優先級。各個進程按照權重的比例來分配使用 CPU 的時間。比如2個進程 A 和 B, A 的權重為 100, B 的權重為200,那么 A 獲得的 CPU 的時間為 100/(100+200) = 33%, B 進程獲得的CPU 的時間為 200/(100+200) = 67%。
在引入權重之后,在一個調度周期中分配給進程的運行時間計算公式如下:
實際運行時間 = 調度周期 * 進程權重 / 所有進程權重之和
可以看到,權重越大,分到的運行時間越多。
- 調度周期:在某個時間長度可以保證運行隊列中的每個進程至少運行一次,我們把這個時間長度稱為調度周期。也稱為調度延遲,因為一個進程等待被調度的延遲時間是一個調度周期。
- 調度最小粒度:為了防止進程切換太頻繁,進程被調度后應該至少運行一小段時間,我們把這個時間長度稱為調度最小粒度。
調度周期的默認值是20毫秒,調度最小粒度的默認值是4毫秒,如下所示,兩者的單位都是納秒。
//默認調度周期 20ms
unsigned int sysctl_sched_latency = 20000000ULL;
//默認調度最小粒度 4ms
unsigned int sysctl_sched_min_granularity = 4000000ULL;
// 默認一個調度周期內的進程數:sysctl_sched_latency / sysctl_sched_min_granularity
static unsigned int sched_nr_latency = 5;
如果運行隊列中的進程數量太多,導致把調度周期 sysctl_sched_latency 平分給進程時的時間片小于調度最小粒度,那么調度周期取 “調度最小粒度 × 進程數量”。
CFS 調度器中使用 nice 值(取值范圍為[-20 ~ 19])作為進程獲取處理器運行比的權重:nice 值越高(優先級越低)的進程獲得的 CPU使用的權重越低。
在用戶態進程的優先級 nice 值與 CFS 調度器中的權重又有什么關系?
在內核中通過 prio_to_weight 數組進行 nice 值和權重的轉換。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};從 nice 和權重的對應值可知,nice 值為 0 的權重為 1024(默認權重), nice 值為1的權重為 820,nice 值為 15 的權重值為 36,nice 值為19的權重值為 15。
例如:假設調度周期為12ms,2個相同nice的進程其權重也相同,那么2個進程各自的運行時間為 6ms。
假設進程 A 和 B 的 nice 值分別為0、1,那么權重也就分別為 1024、820。因此,A 實際運行時間為 12 * 1024/(1024+820)= 6.66ms ,B 實際運行時間為 12 * 820/(1024+820)= 5.34ms。
從結果來看,2個進程運行時間時不一樣的。由于A的權重高,優先級大,會出現 A 一直被調度,而 B 最后被調度,這就失去了公平性,所以 CFS 的存在就是為了解決 這種不公平性。
因此為了讓每個進程完全公平調度,因此就引入了一個 vruntime (虛擬運行時間,virtual runtime)的概念, 每個調度實體都有一個 vruntime,該vruntime 根據調度實體的調度而不停的累加,CFS 根據 vruntime 的大小來選擇調度實體。
調度實體的結構如下:
struct sched_entity {
struct load_weight load; // 調度實體的負載權重值
struct rb_node run_node; //用于添加到CFS運行隊列的紅黑樹中的節點
unsigned int on_rq;//用于表示是否在運行隊列中
u64 exec_start;//當前調度實體的開始運行時間
u64 sum_exec_runtime;//調度實體執行的總時間
/*虛擬運行時間,在時間中斷或者任務狀態發生改變時會更新
其會不停的增長,增長速度與load權重成反比,load越高,增長速度越慢,就越可能處于紅黑樹最左邊被調度
每次時鐘中斷都會修改其值。注意其值為單調遞增,在每個調度器的時鐘中斷時當前進程的虛擬運行時間都會累加。
單純的說就是進程們都在比誰的vruntime最小,最小的將被調度
*/
u64 vruntime;//虛擬運行時間,這個時間用于在CFS運行隊列中排隊
u64 prev_sum_exec_runtime;//上一個調度實體運行的總時間
...
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent; //指向調度實體的父對象
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq; //指向調度實體歸屬的CFS隊列,也就是需要入列的CFS隊列
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;//指向歸屬于當前調度實體的CFS隊列
#endif
};
虛擬時間和實際時間的關系如下:
虛擬運行時間 = 實際運行時間 *(NICE_0_LOAD / 進程權重)
其中,NICE_0_LOAD 是 nice為0時的權重(默認),也即是 1024。也就是說,nice 值為0的進程實際運行時間和虛擬運行時間相同。
虛擬運行時間一方面跟進程運行時間有關,另一方面跟進程優先級有關。
進程權重越大, 運行同樣的實際時間, vruntime 增長的越慢。
一個進程在一個調度周期內的虛擬運行時間大小為:
vruntime = 進程在一個調度周期內的實際運行時間 * 1024 / 進程權重= (調度周期 * 進程權重 / 所有進程總權重) * 1024 / 進程權重= 調度周期 * 1024 / 所有進程總權重。
可以看到, 一個進程在一個調度周期內的 vruntime 值大小是不和該進程自己的權重相關的, 所以所有進程的 vruntime 值大小都是一樣的。
接著上述的例子,通過虛擬運行時間公式可得:
A 虛擬運行時間為 6.66 * (1024/1024) = 6.66ms,
B 虛擬運行時間為 5.34* (1024/820) = 6.66ms,
在一個調度周期過程中,各個調度實體的 vruntime 都是累加的過程,保證了在一個調度周期結束后,每個調度實體的 vruntime 值大小都是一樣的。
由于權重越高,應該優先的得到運行,因此 CFS 采用虛擬運行時間越小,越先調度。
當權重越高的進程隨著調度的次數多,其 vruntime 的累加也就越多。當其 vruntime 的累加大于其他低優先級進程的 vruntime 時,低優先級的進程得以調度。這就保證了每個進程都可以調度而不會出現高優先級的一直得到調度,而優先級低的進程得不到調度而產生饑餓。
一言以蔽之:在CFS中,不管權重高低,根據 vruntime 大小比較,大家都輪著使用 CPU。
當然,根據一個調度周期中分配給進程的實際運行時間計算公式可知,在一個調度周期內,雖然大家都輪著使用 CPU,但是實際運行時間的多少和權重也是有關的,權重越高,總的實際運行的時間也就越多。在一個調度周期結束后,各個調度實體的 vruntime 最終還是相等的。
那么在 CFS 中 vruntime 是怎么使用的呢?
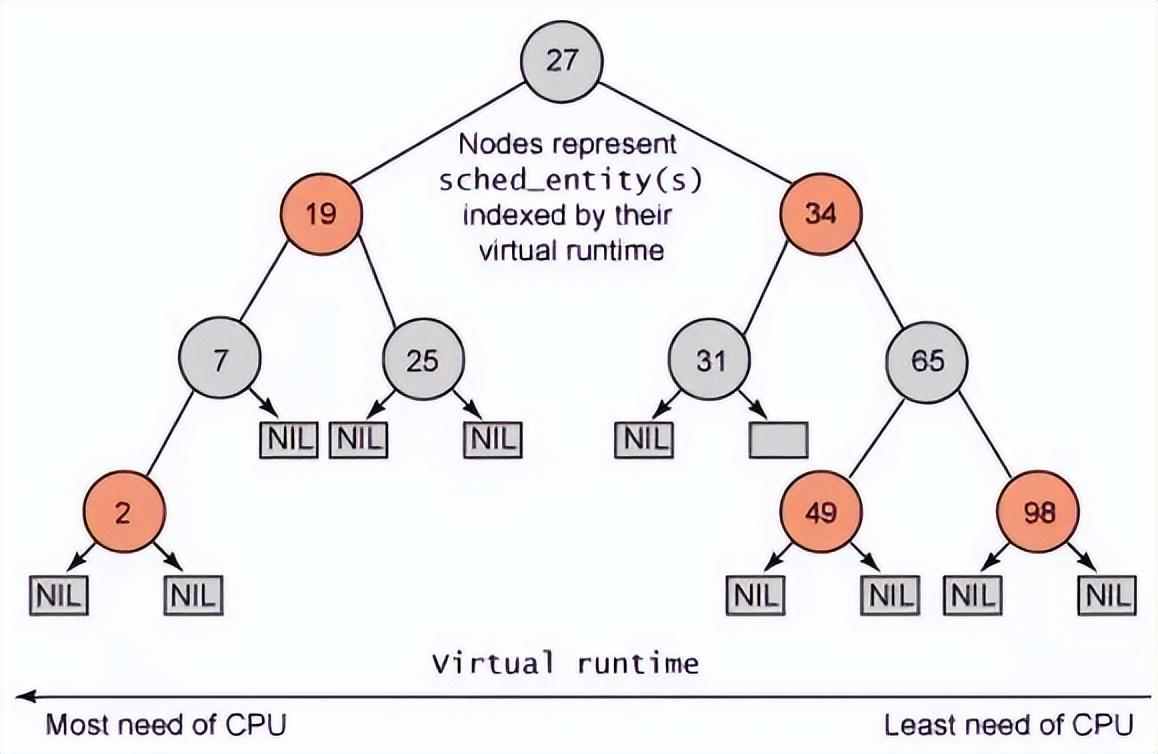
CFS 中的就緒隊列是一棵以 vruntime 為鍵值的紅黑樹,虛擬時間越小的進程越靠近整個紅黑樹的最左端。因此,調度器每次選擇位于紅黑樹最左端的那個進程,該進程的 vruntime 最小,也就最應該優先調度。
實際獲取最左葉子節點時并不會遍歷樹,而是 vruntime 最小的節點已經緩存在了 rb_leftmost 字段中了,因此 CFS 很快可以獲取 vruntime 最小的節點。
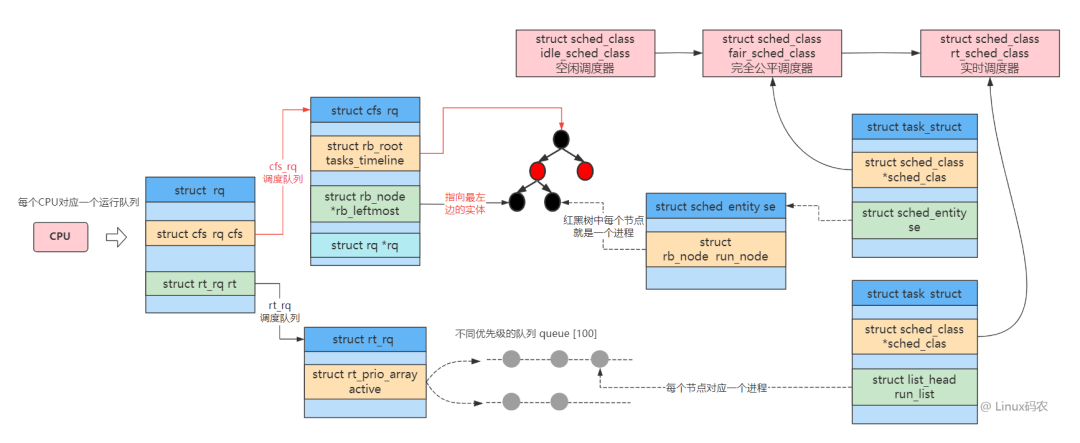
其中紅黑樹的結構如下:
CFS 調度時機
與 CFS 相關的有如下幾個過程:
- 創建新進程: 創建新進程時, 需要設置新進程的 vruntime 值以及將新進程加入紅黑樹中. 并判斷是否需要搶占當前進程。
- 進程的調度: 進程調度時, 需要把當前進程加入紅黑樹中, 還要從紅黑樹中挑選出下一個要運行的進程。
- 進程喚醒: 喚醒進程時, 需要調整睡眠進程的 vruntime 值, 并且將睡眠進程加入紅黑樹中. 并判斷是否需要搶占當前進程。
- 時鐘周期中斷: 在時鐘中斷周期函數中, 需要更新當前運行進程的 vruntime 值, 并判斷是否需要搶占當前進程。
創建新進程
創建新進程的系統調用 fork, vfork, clone. 這三個系統調用最終都是調用do_fork() 函數.在 do_fork() 函數中, 主要就是設置新進程的 vruntime 值, 將新進程加入到紅黑樹中, 判斷新進程是否可以搶占當前進程.
do_fork
--> wake_up_new_task
--> task_new_fair //設置新進程的vruntime值,并將其加入就緒隊列中
--> check_preempt_curr //檢查新進程是否可以搶占當前進程
task_new_fair 實現如下:
static void task_new_fair(struct rq *rq, struct task_struct *p)
{
struct cfs_rq *cfs_rq = task_cfs_rq(p);
struct sched_entity *se = &p->se, *curr = cfs_rq->curr;
int this_cpu = smp_processor_id();
sched_info_queued(p);
update_curr(cfs_rq); //更新當前進程的vruntime值
place_entity(cfs_rq, se, 1); //設置新進程的vruntime值, 1表示是新進程
/* 'curr' will be NULL if the child belongs to a different group */
//sysctl_sched_child_runs_first值表示是否設置了讓子進程先運行
if (sysctl_sched_child_runs_first && this_cpu == task_cpu(p) &&
curr && curr->vruntime < se->vruntime) {
/*
? Upon rescheduling, sched_class::put_prev_task() will place
? 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime); //當子進程的vruntime值大于父進程的vruntime時, 交換兩個進程的vruntime值
}
enqueue_task_fair(rq, p, 0);//將新任務加入到就緒隊列中
//設置TIF_NEED_RESCHED標志值,該標記標志進程是否需要重新調度,如果設置了,就會發生調度
resched_task(rq->curr);
}
該函數給新進程設置一個新的 vruntime,然后加入到就緒隊列中,等待調度。
check_preempt_curr 在 CFS 中 對應的為 check_preempt_wakeup 函數,其實現如下:
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
struct sched_entity *se = &curr->se, *pse = &p->se;
unsigned long gran;
...
// gran 為進程調度粒度
gran = sysctl_sched_wakeup_granularity; // 10 ms
if (unlikely(se->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, &se->load); //計算調度粒度
/*
調度粒度的設置, 是為了防止這么一個情況: 新進程的vruntime值只比當前進程的vruntime小一點點, 如果此時發生重新調度,則新進程只運行一點點時間后,其vruntime值就會大于前面被搶占的進程的vruntime值, 這樣又會發生搶占,所以這樣的情況下,系統會發生頻繁的切換。故, 只有當新進程的vruntime值比當前進程的vruntime值小于調度粒度之外,才發生搶占。
所以,當前進程的虛擬運行時間se->vruntime 比 下一個進程 pse->vruntime 大于一個調度粒度,說明當前進程應該被搶占,應該切換出去讓別vruntime小的進程進行運行,因此給當前進程設置是一個重新調度標記TIF_NEED_RESCHED,當某個時機根據該標記進行調用schedule(),這時會重新選擇一個進程進行切換。
*/
if (pse->vruntime + gran < se->vruntime)
resched_task(curr);
}
該功能就是根據調度粒度,判斷是否需要設置被搶占標記,若需要,這調用resched_task 把當前進程設置成被搶占標記TIF_NEED_RESCHED,該標記說明當前進程運行的時間夠多的了,應該切換出去,讓出 CPU 讓讓別的進程運行。
static void resched_task(struct task_struct *p)
{
int cpu;
assert_spin_locked(&task_rq(p)->lock);
if (unlikely(test_tsk_thread_flag(p, TIF_NEED_RESCHED)))
return;
//設置被被搶占標記
set_tsk_thread_flag(p, TIF_NEED_RESCHED);
cpu = task_cpu(p);
if (cpu == smp_processor_id())
return;
/* NEED_RESCHED must be visible before we test polling */
smp_mb();
if (!tsk_is_polling(p))
smp_send_reschedule(cpu);
}
設置完TIF_NEED_RESCHED 不代表當前進程立馬就切換出去了,而是等待一定時機,然后會根據TIF_NEED_RESCHED 標記調用schedule()進行調度切換。
進程的調度
進程調度的主要入口點是 schedule 函數,它正是內核其他部分用于調用進程調度器的入口:選擇哪個進程可以運行,何時投入運行。
schedule 通常要和一個具體的調度類相關聯,也即是,它會找到最高優先級的調度類,然后從就緒隊列中選擇下一個該運行的進程。
當調用 schedule() 進行任務切換的時候,調度器調用 pick_next_task 函數選擇下一個將要執行的任務,這是相對默認 nice 值進程的進程而言的。
asmlinkage void __sched schedule(void)
{
/*prev 表示調度之前的進程, next 表示調度之后的進程 */
struct task_struct *prev, *next;
long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable(); //關閉內核搶占
cpu = smp_processor_id(); //獲取所在的cpu
rq = cpu_rq(cpu); //獲取cpu對應的運行隊列
rcu_qsctr_inc(cpu);
prev = rq->curr; /*讓prev 成為當前進程 */
switch_count = &prev->nivcsw;
/釋放全局內核鎖,并開this_cpu 的中斷/
release_kernel_lock(prev);
need_resched_nonpreemptible:
__update_rq_clock(rq); //更新運行隊列的時鐘值
...
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
// 對應到CFS,則為 put_prev_task_fair
prev->sched_class->put_prev_task(rq, prev); //通知調度器類當前運行進程要被另一個進程取代
/*pick_next_task以優先級從高到底依次檢查每個調度類,從最高優先級的調度類中選擇最高優先級的進程作為
下一個應執行進程(若其余都睡眠,則只有當前進程可運行,就跳過下面了)*/
next = pick_next_task(rq, prev); //選擇需要進行切換的task
...
}
在選擇下一個進程前,先調用 put_prev_task (對應到 CFS 為put_prev_task_fair),計算下當前進程的運行時間,根據當前運行時間計算出虛擬運行時間,并累加到 vruntime,然后把當前進程根據 vruntime 重新加入到就緒隊列紅黑樹中,等待下一次被調度。
put_prev_task_fair
--> put_prev_entity
--> update_curr
--> __update_curr //更新當前調度實體的實際運行時間和虛擬運行時間
--> __enqueue_entity //把當前調度實體重新加入到就緒隊列紅黑樹中等待下一次調度
/*
cfs_rq:可運行隊列對象。
curr:當前進程調度實體。
delta_exec:實際運行的時間。
__update_curr() 函數主要完成以下幾個工作:
更新進程調度實體的總實際運行時間。
根據進程調度實體的權重值,計算其使用的虛擬運行時間。
把計算虛擬運行時間的結果添加到進程調度實體的 vruntime 字段。
*/
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,
unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
u64 vruntime;
schedstat_set(curr->exec_max, max((u64)delta_exec, curr->exec_max));
//// 增加當前進程總實際運行的時間
curr->sum_exec_runtime += delta_exec;
// 更新cfs_rq的實際執行時間cfs_rq->exec_clock
schedstat_add(cfs_rq, exec_clock, delta_exec);
//根據實際運行時間計算虛擬運行時間并累加到當前進程的虛擬運行時間
delta_exec_weighted = delta_exec;
//// 根據實際運行時間計算其使用的虛擬運行時間
if (unlikely(curr->load.weight != NICE_0_LOAD)) {
delta_exec_weighted = calc_delta_fair(delta_exec_weighted,
&curr->load);
}
curr->vruntime += delta_exec_weighted; // 更新進程的虛擬運行時間
/*
? maintain cfs_rq->min_vruntime to be a monotonic increasing
? value tracking the leftmost vruntime in the tree.
*/
if (first_fair(cfs_rq)) {
vruntime = min_vruntime(curr->vruntime,
__pick_next_entity(cfs_rq)->vruntime);
} else
vruntime = curr->vruntime;
/*min_vruntime記錄CFS運行隊列上vruntime最小值,但是實際上min_vruntime只能單調遞增,
所以,如果當前進程vruntime比min_vruntime小,是不會更新min_vruntime的。
那么min_vruntime的作用的是什么呢?試想一下如果一個進程睡眠了很長時間,則它的vruntime非常小,
一旦它被喚醒,將持續占用CPU,很容易引發進程饑餓。
CFS調度器會根據min_vruntime設置一個合適的vruntime值給被喚醒的進程,
既要保證它能優先被調度,又要保證其他進程也能得到合理調度。
*/
cfs_rq->min_vruntime =
max_vruntime(cfs_rq->min_vruntime, vruntime);
}
該函數的功能如下:
- 更新進程調度實體的總實際運行時間。
- 根據進程調度實體的權重值,計算其虛擬運行時間。
- 把計算虛擬運行時間的結果添加到進程調度實體的 vruntime 字段。
將調度實體加入紅黑樹中
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node; // 紅黑樹根節點
struct rb_node *parent = NULL;
struct sched_entity *entry;
s64 key = entity_key(cfs_rq, se);// 當前進程調度實體的虛擬運行時間
int leftmost = 1;
/*
? Find the right place in the rbtree:
*/
while (*link) { // 把當前調度實體插入到運行隊列的紅黑樹中
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
? We dont care about collisions. Nodes with
? the same key stay together.
*/
if (key < entity_key(cfs_rq, entry)) { // 比較虛擬運行時間
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
? Maintain a cache of leftmost tree entries (it is frequently
? used):
*/
if (leftmost) //緩存最左葉子節點
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
//把節點插入到紅黑樹中
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
__enqueue_entity() 函數的主要工作如下:
- 獲取運行隊列紅黑樹的根節點。
- 獲取當前進程調度實體的虛擬運行時間。
- 把當前進程調度實體添加到紅黑樹中。
- 緩存紅黑樹最左端節點。
- 對紅黑樹進行平衡操作。
獲取下一個合適的調度實體
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{
const struct sched_class *class;
struct task_struct *p;
/*
? Optimization: we know that if all tasks are in
? the fair class we can call that function directly:
*/
/選擇時并不是想象中的直接按照調度器的優先級對所有調度器類進行遍歷,而是假設下一個運行的進程屬于 cfs 調度器類,畢竟,系統中絕大多數的進程都是由 cfs 調度器進行管理,這樣做可以從整體上提高執行效率./
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
class = sched_class_highest; // #define sched_class_highest (&rt_sched_class)
for ( ; ; ) {
p = class->pick_next_task(rq);
if (p)
return p;
/*
? Will never be NULL as the idle class always
? returns a non-NULL p:
*/
class = class->next;
}
}
在 pick_next_task 中會遍歷所有的調度類,然后從就緒隊列中選取一個最合適的調度實體進行調度。
對于完全公平調度算法(CFS),會調用fair_sched_class.pick_next_task() 函數,從 fair_sched_class 中可知,也即是調用 pick_next_task_fair。
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.load_balance = load_balance_fair,
.move_one_task = move_one_task_fair,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_new = task_new_fair,
};pick_next_task_fair 調用過程如下:
pick_next_task_fair
---> pick_next_entity
---> __pick_next_entity 從就緒隊列中選取一個最合適的調度實體(虛擬時間最小的調度實體)
---> set_next_entity 把選中的進程從紅黑樹中移除,并更新紅黑樹
從 schedule 調用可知,其在選擇下一個運行任務前,先計算當前進程(待切換出去的進程)的時間運行時間,然后根據實際運行時間計算虛擬運行時間,在根據虛擬運行時間把當前進程加入到就緒隊列中的紅黑樹中等待下一次調度。
其次,從就緒隊列的紅黑樹中選擇虛擬運行時間最小的任務作為即將運行的任務。
進程喚醒
進程的默認喚醒函數是 try_to_wake_up(), 該函數主要是調整睡眠進程的 vruntime值, 以及把睡眠進程加入紅黑樹中, 并判斷是否可以發生搶占。
調用關系如下:
try_to_wake_up
--> activate_task
--> enqueue_task
--> check_preempt_curr
時鐘周期中斷
周期性調度器是基于 scheduler_tick 函數實現。系統都是以tick(節拍)來執行各種調度與統計,節拍可以通過 CONFIG_HZ 宏來控制。內核會以 1/HZ ms 為周期來執行周期性調度,這也是 CFS 實現的關鍵。CFS調度類會根據這個節拍來對所有進程進行記賬。每個 CPU 都會擁有自己的周期性調度器。周期性調度器可以把當前進程設置為 need resched 狀態,等待合適的時機當前的進程就會被重新調度。
時鐘周期中斷函數的調用過程:
tick_periodic
--> update_process_times
--> scheduler_tick
--> task_tick_fair
-->entity_tick
--> update_curr
--> check_preempt_tick
在 CFS 中,scheduler_tick 會調用 具體實現 task_tick_fair,在task_tick_fair 中會從當前進程開始獲取每個調度實體,對每個調度實體進行調用 entity_tick,在 entity_tick 中更新調度實體的實際運行時間和虛擬運行時間,同時檢查是否需要重新調度。
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
// ideal_runtime 為一個調度周期內理想的運行時間,也即是為 調度周期 * 進程權重 / 所有進程權重之和
ideal_runtime = sched_slice(cfs_rq, curr);
// sum_exec_runtime 指進程總共執行的實際時間;
// prev_sum_exec_runtime 指上次該進程被調度時已經占用的實際時間。
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
// delta_exec 這次調度占用實際時間,如果大于 ideal_runtime,則應該被搶占了
if (delta_exec > ideal_runtime)
resched_task(rq_of(cfs_rq)->curr);
}
若當前進程運行的時間超過時間限制,
則把當前進程設置為 被搶占重新調度標記 TIF_NEED_RESCHED,待一定時機后會根據 TIF_NEED_RESCHED 標記調用 schedule() 進行調度切換。關于“一定的時機”,后續文章進行分析。

































