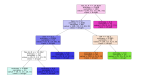
梯度提升算法決策過程的逐步可視化
梯度提升算法是最常用的集成機器學(xué)習(xí)技術(shù)之一,該模型使用弱決策樹序列來構(gòu)建強學(xué)習(xí)器。這也是XGBoost和LightGBM模型的理論基礎(chǔ),所以在這篇文章中,我們將從頭開始構(gòu)建一個梯度增強模型并將其可視化。
梯度提升算法介紹
梯度提升算法(Gradient Boosting)是一種集成學(xué)習(xí)算法,它通過構(gòu)建多個弱分類器,然后將它們組合成一個強分類器來提高模型的預(yù)測準確率。
梯度提升算法的原理可以分為以下幾個步驟:
- 初始化模型:一般來說,我們可以使用一個簡單的模型(比如說決策樹)作為初始的分類器。
- 計算損失函數(shù)的負梯度:計算出每個樣本點在當前模型下的損失函數(shù)的負梯度。這相當于是讓新的分類器去擬合當前模型下的誤差。
- 訓(xùn)練新的分類器:用這些負梯度作為目標變量,訓(xùn)練一個新的弱分類器。這個弱分類器可以是任意的分類器,比如說決策樹、線性模型等。
- 更新模型:將新的分類器加入到原來的模型中,可以用加權(quán)平均或者其他方法將它們組合起來。
- 重復(fù)迭代:重復(fù)上述步驟,直到達到預(yù)設(shè)的迭代次數(shù)或者達到預(yù)設(shè)的準確率。
由于梯度提升算法是一種串行算法,所以它的訓(xùn)練速度可能會比較慢,我們以一個實際的例子來介紹:
假設(shè)我們有一個特征集Xi和值Yi,要計算y的最佳估計

我們從y的平均值開始

每一步我們都想讓F_m(x)更接近y|x。

在每一步中,我們都想要F_m(x)一個更好的y給定x的近似。
首先,我們定義一個損失函數(shù)
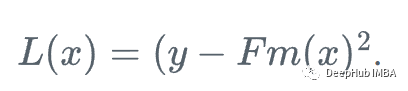
然后,我們向損失函數(shù)相對于學(xué)習(xí)者Fm下降最快的方向前進:
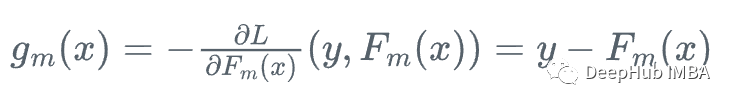
因為我們不能為每個x計算y,所以不知道這個梯度的確切值,但是對于訓(xùn)練數(shù)據(jù)中的每一個x_i,梯度完全等于步驟m的殘差:r_i!
所以我們可以用弱回歸樹h_m來近似梯度函數(shù)g_m,對殘差進行訓(xùn)練:
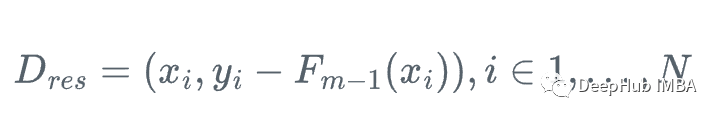
然后,我們更新學(xué)習(xí)器
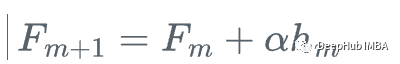
這就是梯度提升,我們不是使用損失函數(shù)相對于當前學(xué)習(xí)器的真實梯度g_m來更新當前學(xué)習(xí)器F_{m},而是使用弱回歸樹h_m來更新它。

也就是重復(fù)下面的步驟
1、計算殘差:

2、將回歸樹h_m擬合到訓(xùn)練樣本及其殘差(x_i, r_i)上
3、用步長\alpha更新模型

看著很復(fù)雜對吧,下面我們可視化一下這個過程就會變得非常清晰了
決策過程可視化
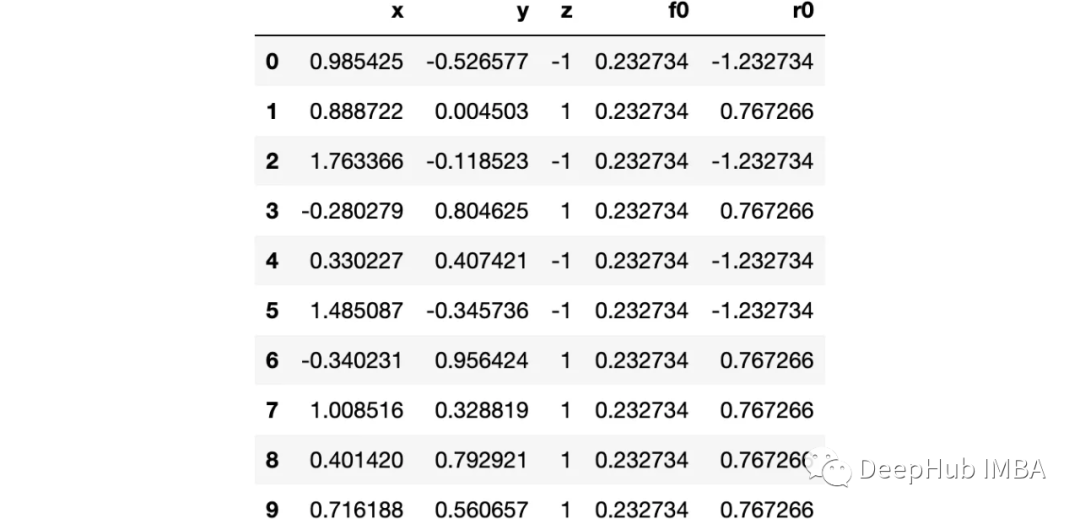
這里我們使用sklearn的moons 數(shù)據(jù)集,因為這是一個經(jīng)典的非線性分類數(shù)據(jù)
讓我們可視化數(shù)據(jù):
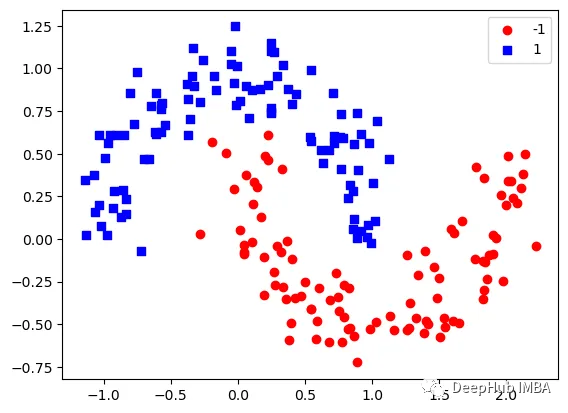
下圖可以看到,該數(shù)據(jù)集是可以明顯的區(qū)分出分類的邊界的,但是因為他是非線性的,所以使用線性算法進行分類時會遇到很大的困難。
那么我們先編寫一個簡單的梯度增強模型:
上面代碼執(zhí)行3個簡單步驟:
將決策樹與殘差進行擬合:
然后,我們將這個近似的梯度與之前的學(xué)習(xí)器相加:
最后重新計算殘差:
步驟就是這樣簡單,下面我們來一步一步執(zhí)行這個過程。
第1次決策

Tree Split for 0 and level 1.563690960407257

第2次決策
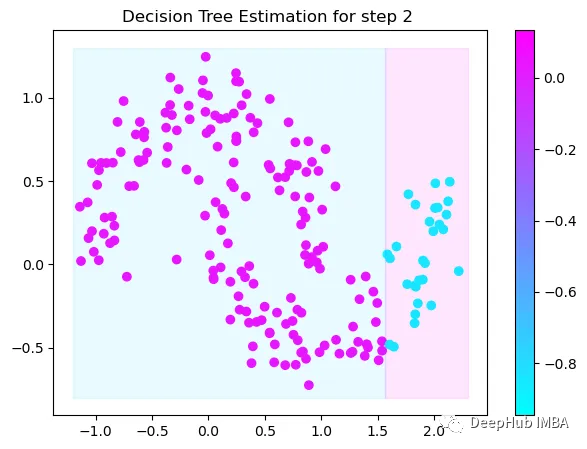
Tree Split for 1 and level 0.5143677890300751
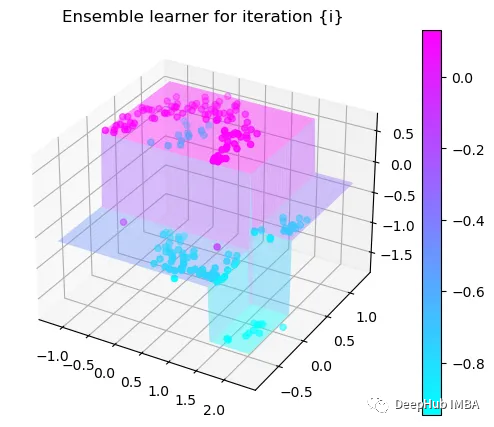
第3次決策
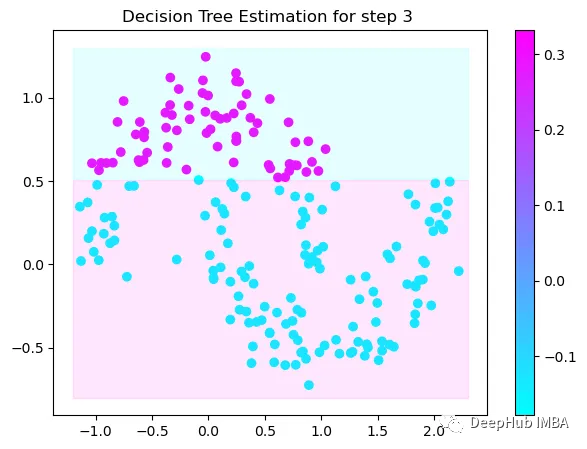
Tree Split for 0 and level -0.6523728966712952

第4次決策

Tree Split for 0 and level 0.3370491564273834

第5次決策

Tree Split for 0 and level 0.3370491564273834

第6次決策

Tree Split for 1 and level 0.022058885544538498

第7次決策

Tree Split for 0 and level -0.3030575215816498

第8次決策

Tree Split for 0 and level 0.6119407713413239

第9次決策

可以看到通過9次的計算,基本上已經(jīng)把上面的分類進行了區(qū)分

我們這里的學(xué)習(xí)器都是非常簡單的決策樹,只沿著一個特征分裂!但整體模型在每次決策后邊的越來越復(fù)雜,并且整體誤差逐漸減小。

這也就是上圖中我們看到的能夠正確區(qū)分出了大部分的分類
如果你感興趣可以使用下面代碼自行實驗:
??https://github.com/trenaudie/GradientBoostingVisualized/blob/main/fromScratch.ipynb??