只要模型夠大、樣本夠多,AI就可以變得更智能!
?AI模型與人腦在數(shù)學(xué)機(jī)制上并沒有什么區(qū)別。
只要模型夠大、樣本夠多,AI就可以變得更智能!
chatGPT的出現(xiàn),實(shí)際上已經(jīng)證明了這點(diǎn)。
1,AI和人腦的底層細(xì)節(jié)都是基于if else語(yǔ)句
邏輯運(yùn)算,是產(chǎn)生智能的基礎(chǔ)運(yùn)算。
編程語(yǔ)言的基本邏輯是if else,它會(huì)根據(jù)條件表達(dá)式把代碼分成兩個(gè)分支。
在這個(gè)基礎(chǔ)上,程序員可以寫出非常復(fù)雜的代碼,實(shí)現(xiàn)各種各樣的業(yè)務(wù)邏輯。
人腦的基本邏輯也是if else,if else這兩個(gè)詞就來(lái)自英語(yǔ),對(duì)應(yīng)的中文詞匯是如果...否則...
人腦在思考問(wèn)題時(shí)也是這么一個(gè)邏輯思路,這點(diǎn)上跟電腦沒有區(qū)別。
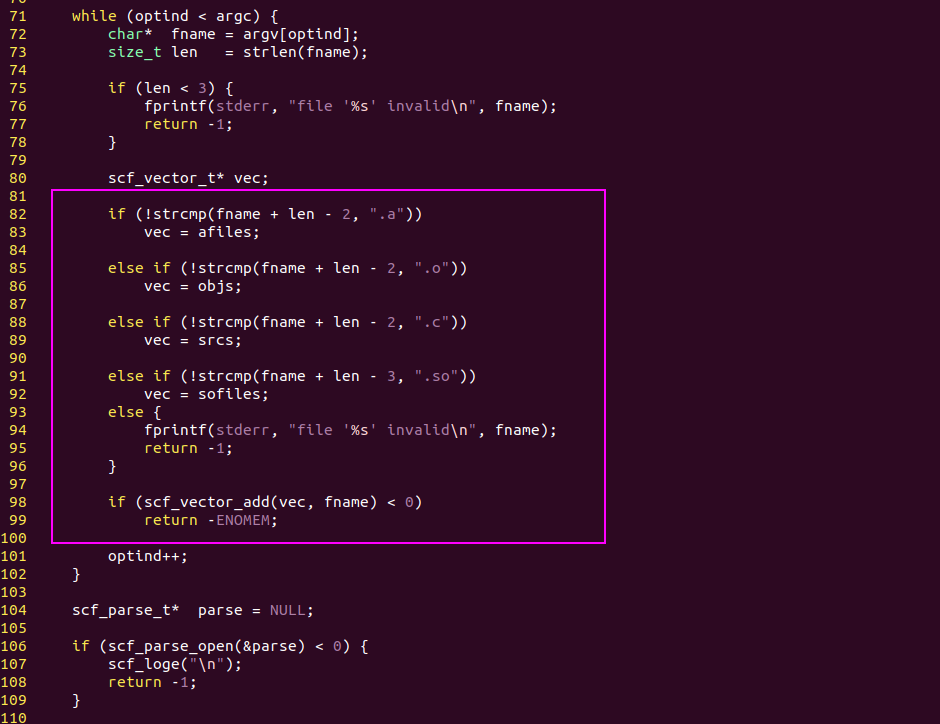
if else語(yǔ)句,邏輯的核心
AI模型的“if else語(yǔ)句”就是激活函數(shù)!
AI模型的一個(gè)運(yùn)算節(jié)點(diǎn),我們也可以叫它“神經(jīng)元”。
它有一個(gè)輸入向量X,一個(gè)權(quán)值矩陣W,一個(gè)偏置向量b,還有一個(gè)激活函數(shù)。
激活函數(shù)的作用實(shí)際就是if else語(yǔ)句,而WX + b這個(gè)線性運(yùn)算就是條件表達(dá)式。
在激活之后,AI模型的代碼相當(dāng)于運(yùn)行在 if分支,而不激活時(shí)相當(dāng)于運(yùn)行在else分支。
多層神經(jīng)網(wǎng)絡(luò)的不同激活狀態(tài),實(shí)際上也是對(duì)樣本信息的二進(jìn)制編碼。
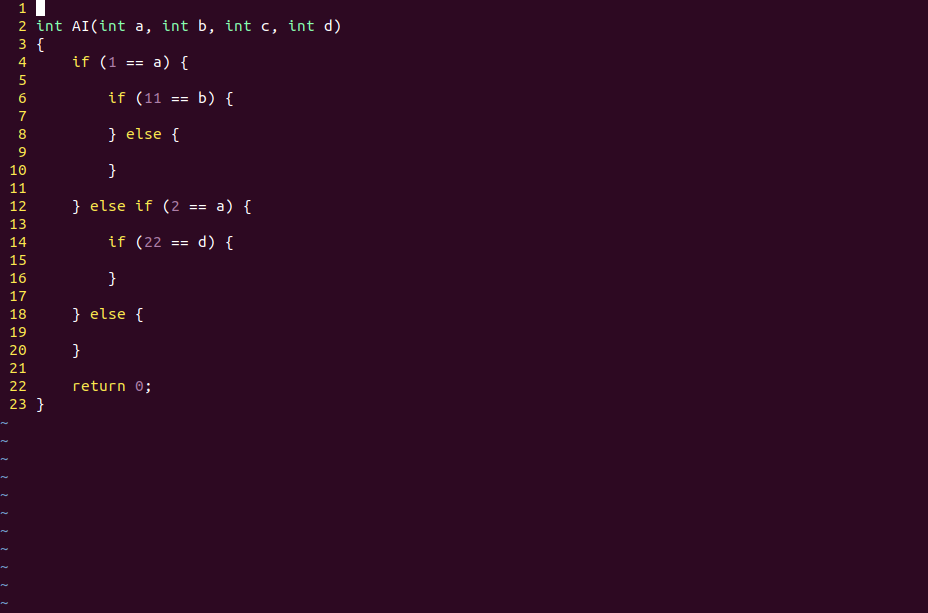
深度學(xué)習(xí)也是對(duì)樣本信息的二進(jìn)制編碼
AI模型對(duì)樣本信息的編碼是動(dòng)態(tài)的、并行的,而不是和CPU代碼一樣是靜態(tài)的、串行的,但它們的底層基礎(chǔ)都是if else。
在電路層面要實(shí)現(xiàn)if else并不難,一個(gè)三極管就可以實(shí)現(xiàn)。
2,人腦比電腦聰明,是因?yàn)槿祟惈@得的信息更多
人腦每時(shí)每刻都在獲取外界的信息,每時(shí)每刻都在更新自己的“樣本數(shù)據(jù)庫(kù)”,但程序代碼沒法自我更新,這是很多人能做到的事而電腦做不到的原因。
人腦的代碼是活的,電腦的代碼是死的。
“死代碼”當(dāng)然不可能比“活代碼”更聰明,因?yàn)椤盎畲a”可以主動(dòng)查找“死代碼”的BUG。
而根據(jù)實(shí)數(shù)的連續(xù)性,只要“死代碼”編碼的信息是可數(shù)的,那么它就總存在編碼不到的BUG點(diǎn)。
這在數(shù)學(xué)上可以用康托三分集來(lái)佐證。
不管我們用多少位的三進(jìn)制小數(shù)去編碼[0, 1]區(qū)間上的實(shí)數(shù),總有至少1個(gè)點(diǎn)是沒法編碼進(jìn)去的。
所以當(dāng)兩個(gè)人抬杠的時(shí)候,總是能找到可抬杠的點(diǎn)?
但是電腦的代碼一旦寫好就沒法主動(dòng)更新了,所以程序員可以想出各種辦法去欺騙CPU。
例如,intel的CPU本來(lái)要求在進(jìn)程切換時(shí)要切換任務(wù)門的,但Linux就想出了一個(gè)辦法只切換頁(yè)目錄和RSP寄存器?
在intel CPU看來(lái),Linux系統(tǒng)一直在運(yùn)行同一個(gè)進(jìn)程,但實(shí)際上不是。這就是所謂的進(jìn)程軟切換。
所以,只要CPU的電路固定了,那么CPU編碼的信息也就固定了。
CPU編碼的信息固定了,那么它編碼不到的信息就是無(wú)限的,就是可以被程序員利用的。
而程序員之所以可以利用這種信息,是因?yàn)槌绦騿T的大腦是活的,可以動(dòng)態(tài)的更新樣本。
3,神經(jīng)網(wǎng)絡(luò)的出現(xiàn)改變了這種情況
神經(jīng)網(wǎng)絡(luò)真是一個(gè)偉大的發(fā)明,它在固定的電路上實(shí)現(xiàn)了動(dòng)態(tài)的信息更新。
所有寫好的程序能處理的信息都是固定的,包括CPU電路,也包括各種系統(tǒng)的代碼。
但神經(jīng)網(wǎng)絡(luò)不是這樣,它的代碼雖然是寫好的,但它只需要更新權(quán)值數(shù)據(jù),就可以改變模型的邏輯脈絡(luò)。
實(shí)際上只要不斷地輸入新樣本,AI模型就可以不斷地用BP算法(梯度下降算法)更新權(quán)值數(shù)據(jù),從而適應(yīng)新的業(yè)務(wù)場(chǎng)景。
AI模型的更新不需要修改代碼,而只需要修改數(shù)據(jù),所以同樣的CNN模型用不同的樣本訓(xùn)練,它就可以識(shí)別不同的物體。
在這個(gè)過(guò)程中,不管是tensorflow框架的代碼,還是AI模型的網(wǎng)絡(luò)結(jié)構(gòu)都是不變的,變的是每個(gè)節(jié)點(diǎn)的權(quán)值數(shù)據(jù)。
理論上來(lái)說(shuō),只要AI模型可以通過(guò)網(wǎng)絡(luò)抓取數(shù)據(jù),它就可以變得更智能。
這跟人們通過(guò)瀏覽器看東西(從而變得更聰明),有本質(zhì)的區(qū)別嗎?好像也沒有。
4,只要模型夠大、樣本夠多,或許ChatGPT真可以挑戰(zhàn)人腦
人腦有150億個(gè)神經(jīng)元,而且人的眼睛和耳朵每時(shí)每刻都在給它提供新的數(shù)據(jù),AI模型當(dāng)然也可以做到這點(diǎn)。
或許比起AI來(lái),人類的優(yōu)勢(shì)在于“產(chǎn)業(yè)鏈”更短?
一個(gè)嬰兒的出生只需要Ta父母,但一個(gè)AI模型的誕生顯然不是一兩個(gè)程序員可以做到的。
僅僅是GPU的制造就不止幾萬(wàn)人。
GPU上的CUDA程序并不難寫,但GPU制造的產(chǎn)業(yè)鏈太長(zhǎng)了,遠(yuǎn)不如人類的出生和成長(zhǎng)。
這或許是AI相對(duì)于人的真正劣勢(shì)。