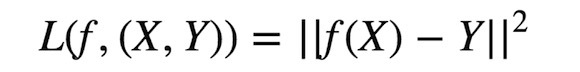漲知識!用邏輯規(guī)則進(jìn)行機(jī)器學(xué)習(xí)
Skope-rules使用樹模型生成規(guī)則候選項。首先建立一些決策樹,并將從根節(jié)點到內(nèi)部節(jié)點或葉子節(jié)點的路徑視為規(guī)則候選項。然后通過一些預(yù)定義的標(biāo)準(zhǔn)(如精確度和召回率)對這些候選規(guī)則進(jìn)行過濾。只有那些精確度和召回率高于其閾值的才會被保留。最后,應(yīng)用相似性過濾來選擇具有足夠多樣性的規(guī)則。一般情況下,應(yīng)用Skope-rules來學(xué)習(xí)每個根本原因的潛在規(guī)則。

項目地址:https://github.com/scikit-learn-contrib/skope-rules
- Skope-rules是一個建立在scikit-learn之上的Python機(jī)器學(xué)習(xí)模塊,在3條款BSD許可下發(fā)布。
- Skope-rules旨在學(xué)習(xí)邏輯的、可解釋的規(guī)則,用于 "界定 "目標(biāo)類別,即高精度地檢測該類別的實例。
- Skope-rules是決策樹的可解釋性和隨機(jī)森林的建模能力之間的一種權(quán)衡。

schema
安裝
可以使用 pip 獲取最新資源:
快速開始
SkopeRules 可用于描述具有邏輯規(guī)則的類:

注意:
如果出現(xiàn)如下錯誤:

解決方案:
關(guān)于 Python 導(dǎo)入錯誤 : cannot import name 'six' from 'sklearn.externals' ,云朵君在Stack Overflow上找到一個類似的問題:https://stackoverflow.com/questions/61867945/
解決方案如下
親測有效!
如果使用“score_top_rules”方法,SkopeRules 也可以用作預(yù)測器:

實戰(zhàn)案例
本案例展示了在著名的泰坦尼克號數(shù)據(jù)集上使用skope-rules。
skope-rules適用情況:
- 解決二分類問題
- 提取可解釋的決策規(guī)則
本案例分為5個部分
- 導(dǎo)入相關(guān)庫
- 數(shù)據(jù)準(zhǔn)備
- 模型訓(xùn)練(使用ScopeRules().score_top_rules()方法)
- 解釋 "生存規(guī)則"(使用SkopeRules().rules_屬性)。
- 性能分析(使用SkopeRules.predict_top_rules()方法)。
導(dǎo)入相關(guān)庫
數(shù)據(jù)準(zhǔn)備
模型訓(xùn)練
"生存規(guī)則" 的提取

模型性能檢測

在ROC曲線上,每個紅點對應(yīng)于激活的規(guī)則(來自skope-rules)的數(shù)量。例如,最低點是1個規(guī)則(最好的)的結(jié)果點。第二低點是2條規(guī)則結(jié)果點,等等。
在準(zhǔn)確率-召回率曲線上,同樣的點是用不同的坐標(biāo)軸繪制的。警告:左邊的第一個紅點(0%召回率,100%精度)對應(yīng)于0條規(guī)則。左邊的第二個點是第一個規(guī)則,等等。
從這個例子可以得出一些結(jié)論。
- skope-rules的表現(xiàn)比決策樹好。
- skope-rules的性能與隨機(jī)森林/梯度提升相似(在這個例子中)。
- 使用4個規(guī)則可以獲得很好的性能(61%的召回率,94%的精確度)(在這個例子中)。

predict_top_rules(new_data, n_r)方法用來計算對new_data的預(yù)測,其中有前n_r條skope-rules規(guī)則。