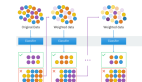
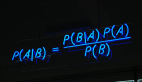用Madlib學習『機器學習』之KNN
原創前言
機器學習(ML)分為:監督學習,無監督學習,半監督學習等。
1.1 監督學習(supervised learning)
監督學習是訓練神經網絡和決策樹的常見技術,高度依賴事先確定的分類系統給出的信息,對于神經網絡,分類系統利用信息判斷網絡的錯誤,然后不斷調整網絡參數。對于決策樹,分類系統用它來判斷哪些屬性提供了最多的信息。
從給定的訓練數據集中學習出一個函數,當新的數據到來時,可以根據這個函數預測結果。
監督學習的訓練集要求包括輸入輸出,也可以說是特征和目標,訓練集中的目標是由人標注的。
常見的有監督學習算法:回歸分析和統計分類,最典型的算法是KNN和SVM。
有監督學習最常見的就是:regression & classification
Regression:Y是實數向量,回歸問題,就是擬合(x,y)的一條曲線,使得價值函數(cost function) L最小。
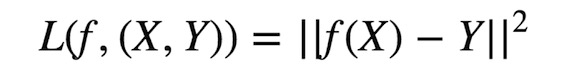
Classification:Y是一個有窮數(finite number),可以看做類標號,分類問題首先要給定有label的數據訓練分類器,故屬于有監督學習過程,分類過程中cost function l(X,Y)是X屬于類Y的概率的負對數。
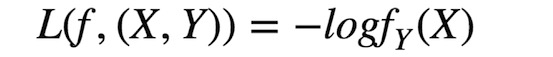
其中fi(X)=P(Y=i/X)。
有監督學習方法必須要有訓練集與測試樣本,在訓練集中找規律,而對測試樣本使用這種規律。
有監督學習的方法就是識別事物,識別的結果表現在給待識別數據加上了標簽,因此訓練樣本集必須由帶標簽的樣本組成。
1.2 名詞KNN
k-Nearest Neighbors
在一個給定的數據點上找出k個最近的數據點,在分類的情況下輸出輸出類的多數投票值,以及在回歸情況下目標值的平均值。
擼袖子
2.1 新新相映
軟件是基于***的postgresql 10.0加上***的madlib 1.12。
為了操作方便,我這里使用基于docker的ubuntu 16.04安裝madlib,這樣以后就可以拿著這個鏡像到處嗨了,以下操作就是在MAC里面進行的。
2.2 查看madlib版本
- #select madlib.version();
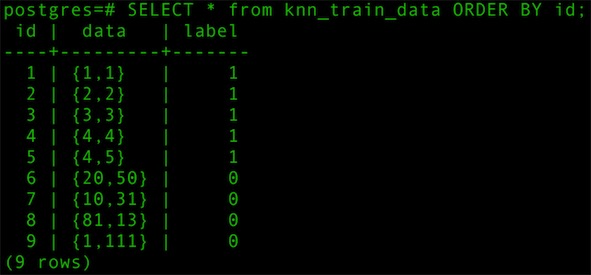
2.3 導入訓練數據
- DROP TABLE IF EXISTS knn_train_data;
- CREATE TABLE knn_train_data (
- id integer,
- data integer[],
- label float
- );
- INSERT INTO knn_train_data VALUES
- (1, '{1,1}', 1.0),
- (2, '{2,2}', 1.0),
- (3, '{3,3}', 1.0),
- (4, '{4,4}', 1.0),
- (5, '{4,5}', 1.0),
- (6, '{20,50}', 0.0),
- (7, '{10,31}', 0.0),
- (8, '{81,13}', 0.0),
- (9, '{1,111}', 0.0);
- SELECT * from knn_train_data ORDER BY id;
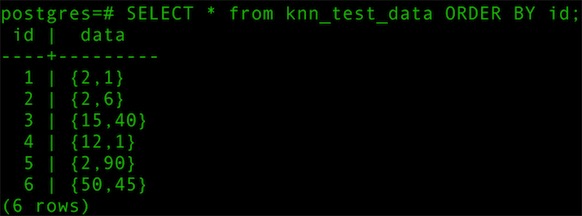
2.4 導入測試數據
- DROP TABLE IF EXISTS knn_test_data;
- CREATE TABLE knn_test_data (
- id integer,
- data integer[]
- );
- INSERT INTO knn_test_data VALUES
- (1, '{2,1}'),
- (2, '{2,6}'),
- (3, '{15,40}'),
- (4, '{12,1}'),
- (5, '{2,90}'),
- (6, '{50,45}');
- SELECT * from knn_test_data ORDER BY id;
2.5 分類訓練
- SELECT * FROM madlib.knn(
- 'knn_train_data', -- 訓練數據表名
- 'data', -- 訓練數據所在列
- 'label', -- 訓練標簽
- 'knn_test_data', -- 測試數據表名
- 'data', -- 測試數據所在列
- 'id', -- 測試數據列名id
- 'madlib_knn_result_classification', -- 結果輸出
- 'c', -- 分類
- 3 -- 最近相鄰數
- );
2.6 查看分類輸出結果
- SELECT * from madlib_knn_result_classification ORDER BY id;
圖形化示例:

2.7 進行回歸
- DROP TABLE IF EXISTS madlib_knn_result_regression;
- SELECT * FROM madlib.knn(
- 'knn_train_data', -- 訓練數據表名
- 'data', -- 訓練數據所在列
- 'label', -- 訓練標簽
- 'knn_test_data', -- 測試數據表名
- 'data', -- 測試數據所在列
- 'id', -- 測試數據列名id
- 'madlib_knn_result_regression', --結果輸出
- 'r', -- 回歸
- 3 -- 最近相鄰數
- );
2.8 查看回歸輸出結果
- SELECT * from madlib_knn_result_regression ORDER BY id;
圖形化示例:

小結
postgresql提供了對結構化數據的存儲和加工的便捷,madlib提供了ML算法的支持,強強聯手,相得益彰。
【作者簡介】孫輝,DataHunter技術總監。曾在索尼等知名公司任職,先后擔任過系統架構、技術總監等職位,負責過尚郵,索愛中文輸入法,快牙,mPush(魔推)等知名產品研發。擁有15年深厚IT技術行業經驗,熟悉掌控產品研發各個環節,有豐富的后端、前端、運維、DBA、測試經驗。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】