編譯 | 汪昊
審校 | 重樓
信息安全是一個古老的計算機領域。許多 80 后還記得自己小時候經常聽到的瑞星殺毒和江民殺毒軟件。這些 90 年代火遍大江南北的信息安全工具,至今仍然影響著使用互聯網和信息技術的千家萬戶。隨著人工智能的興起和普及,有越來越多的商業軟件使用了人工智能技術,因此也有黑客盯上了相關的技術產品,研發出了專門攻擊人工智能軟件的黑客手段。

在 2023 年的人工智能頂級會議 AAAI 2023 上,來自新加坡和中國的研究團隊發表了一篇題為 Backdoor Attack through Machine Unlearning 的論文,講述了在新的信息流通環境下的黑客攻與防。論文的下載地址在這里:2310.10659v1.pdf (arxiv.org) 。
作者在文中提出了一種新的攻擊人工智能算法的手段叫做 BAMU。基本原理就是利用機器非學習將一個善良的機器學習模型變成一個邪惡的機器學習模型。
例如在下圖中,攻擊者一開始的時候給數據集合植入了紅色圓圈和綠色圓圈,隨后基于隱私要求或者其他正當要求,請求系統執行機器非學習步驟,導致機器學習的決策邊界發生了偏移:
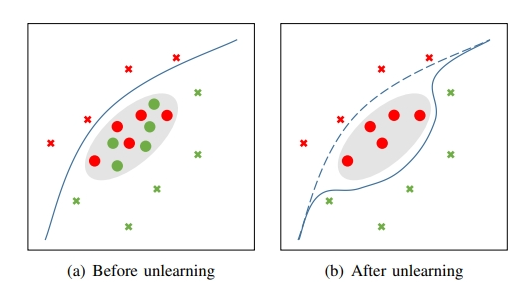
本文作者不僅提出了 BAMU 攻擊方法,也提出了防御 BAMU 的方法。
BAMU 共分為下面幾種攻擊方法:
- 針對輸入的攻擊方法。主要方法是在數據點附近采樣構造有毒樣例(紅色圓圈)和解藥樣例(綠色圓圈)。
- 邪惡網絡方法。該方法更加高效。利用如下公式構造有毒樣例和解藥樣例:
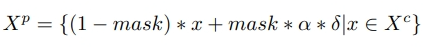
論文作者通過在實驗數據上作比較,分析了攻擊的效果。因為本文篇幅的原因,作者不在此詳細討論實驗結果。需要注意的是,在有的知名數據測試集合上,邪惡網絡方法能夠取得 5% 的成功率。
作者在文章中提到了 2 種防御 BAMU 的方法:
1.模型不確定性方法:因為解藥樣本本身靠近分類器邊界的原因,因此解藥樣本的分類誤差通常很大。所以,我們用下面的公式來評估某樣本是否是可能利用 BAMU 注入的壞樣本:
通過該公式計算出來的 Impurity 值越高,說明該樣本是壞樣本的可能性越大。
2.子模型相似性:模型在解藥樣本的可擴展性差,因此我們利用下面的公式來檢查系統是否被 BAMU 入侵了:
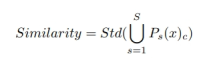
該值越小,表明該樣本越有可能是干凈樣本。
作者隨后利用實驗數據,證明了兩種入侵檢測方法的有效性。
這篇論文選材新穎,利用了一項新的技術——機器非學習的漏洞,詳細闡述了作者最新的發明和發現,值得我們人工智能從業者認真學習。畢竟信息安全至關重要,不能等到事情發生了之后再去補救。千里之堤,潰于蟻穴。因此,哪怕是極其微小的信息安全隱患,也應該引起我們的高度重視。
作者介紹
汪昊,前 Funplus 人工智能實驗室負責人。曾在 ThoughtWorks, 豆瓣,百度,新浪,網易等公司有超過 13 年的技術研發和技術高管經驗。先后在科技公司上線過 10 余款成功的商業產品。擔任過創業公司的 CTO和技術副總裁。精通數據挖掘、計算機圖形學和數字博物館領域的技術、技術管理和技術變現等內容。在國際學術會議和期刊如 IEEE TVCG 和 IEEE / ACM ASONAM 上發表論文 39 篇,獲得最佳論文獎 1 次(IEEE SMI 2008)和最佳論文報告獎 4 次(ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024)。