













譯者 | 朱先忠?
審校 | 重樓?
圖像來自文章https://arxiv.org/abs/2303.10158,由作者本人制作?
人工智能在改變我們的生活、工作和與技術互動的方式方面取得了令人難以置信的進步。最近,一個取得重大進展的領域是大型語言模型(LLM)的開發,如??GPT-3??、??ChatGPT??和??GPT-4??。這些模型能夠以令人印象深刻的準確性執行語言完成翻譯、文本摘要和問答等任務。
雖然很難忽視大型語言模型不斷增加的模型規模,但同樣重要的是要認識到,它們的成功很大程度上歸功于用于訓練它們的大量高質量數據。?
在本文中,我們將從以數據為中心的人工智能角度概述大型語言模型的最新進展,參考我們最近的調查論文(末尾文獻1與2)中的觀點以及GitHub上的相應??技術資源??。特別是,我們將通過以數據為中心的??人工智能??的視角仔細研究GPT模型,這是數據科學界日益增長的一種觀點。我們將通過討論三個以數據為中心的人工智能目標——訓練數據開發、推理數據開發和數據維護,來揭示GPT模型背后以數據為核心的??人工智能概念??。
大型語言模型與GPT模型?
LLM(大型語言模型)是一種自然語言處理模型,經過訓練可以在上下文中推斷單詞。例如,LLM最基本的功能是在給定上下文的情況下預測丟失的令牌。為了做到這一點,LLM被訓練來從海量數據中預測每個候選令牌的概率。?

使用具有上下文的大型語言模型預測丟失令牌的概率的說明性示例(作者本人提供的圖片)?
GPT模型是指OpenAI創建的一系列大型語言模型,如??GPT-1??、??GPT-2??、??GPT-3??、??InstructGPT??和??ChatGPT/GPT-4??。與其他大型語言模型一樣,GPT模型的架構在很大程度上基于轉換器(Transformer),它使用文本和位置嵌入作為輸入,并使用注意力層來建模令牌間的關系。
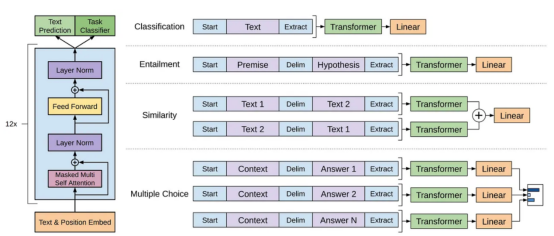
GPT-1模型體系架構示意圖,本圖像來自論文https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf?
后來的GPT模型使用了與GPT-1類似的架構,只是使用了更多的模型參數,具有更多的層、更大的上下文長度、隱藏層大小等。?

GPT模型的各種模型大小比較(作者提供圖片)?
什么是以數據為中心的人工智能??
以數據為中心的人工智能是一種新興的思考如何構建人工智能系統的新方式。人工智能先驅吳恩達(Andrew Ng)一直在倡導這一理念。?
以數據為中心的人工智能是對用于構建人工智能系統的數據進行系統化工程的學科。
——吳恩達
過去,我們主要專注于在數據基本不變的情況下創建更好的模型(以模型為中心的人工智能)。然而,這種方法可能會在現實世界中導致問題,因為它沒有考慮數據中可能出現的不同問題,例如不準確的標簽、重復和偏置。因此,“過度擬合”一個數據集可能不一定會導致更好的模型行為。?
相比之下,以數據為中心的人工智能專注于提高用于構建人工智能系統的數據的質量和數量。這意味著,注意力將集中在數據本身,而模型相對來說更固定。以數據為中心的方法開發人工智能系統在現實世界中具有更大的潛力,因為用于訓練的數據最終決定了模型的最大能力。?
值得注意的是,“以數據為中心”與“數據驅動”有根本不同,因為后者只強調使用數據來指導人工智能開發,而人工智能開發通常仍以開發模型而非工程數據為中心。?
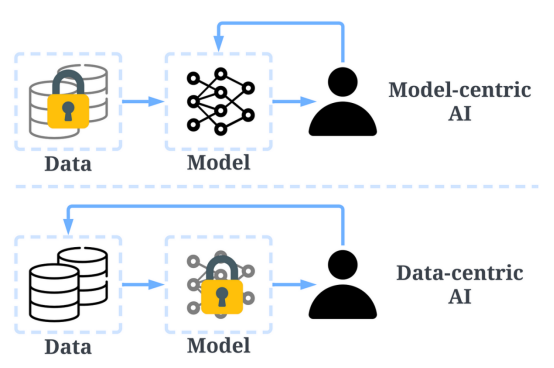
以數據為中心的人工智能與以模型為中心的AI的比較(圖片來自https://arxiv.org/abs/2301.04819論文作者)?
總體來看,以數據為中心的人工智能框架由三個目標組成:?
- 訓練數據開發是收集和產生豐富、高質量的數據,以支持機器學習模型的訓練。?
- 推理數據開發是為了創建新的評估集,這些評估集可以為模型提供更精細的見解,或者通過工程數據輸入觸發模型的特定能力。?
- 數據維護是為了確保數據在動態環境中的質量和可靠性。數據維護至關重要,因為現實世界中的數據不是一次性創建的,而是需要持續維護的。
以數據為中心的人工智能框架(圖像來自論文??https://arxiv.org/abs/2303.10158??的作者)?
為什么以數據為中心的人工智能使GPT模型如此成功??
幾個月前,人工智能界大佬Yann LeCun在其推特上表示,ChatGPT并不是什么新鮮事。事實上,在ChatGPT和GPT-4中使用的所有技術(Transformer和從人類反饋中強化學習等)都不是新技術。然而,他們確實取得了以前的模型無法取得的令人難以置信的成績。那么,他們成功的動力是什么呢??
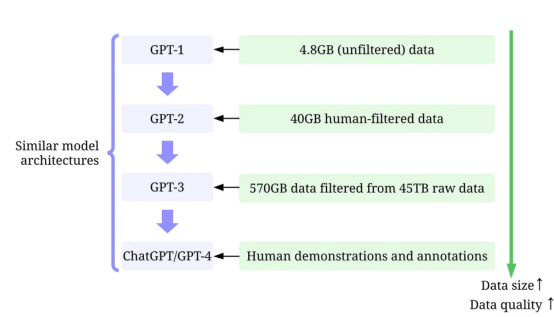
首先,加強訓練數據開發。通過更好的數據收集、數據標記和數據準備策略,用于訓練GPT模型的數據的數量和質量顯著提高。?
- GPT-1:??BooksCorpus數據集??用于訓練。該數據集包含4629MB的原始文本,涵蓋了冒險、幻想和浪漫等一系列流派的書籍。
- 沒有使用以數據為中心的人工智能策略。?
- 訓練結果:在該數據集上應用GPT-1可以通過微調來提高下游任務的性能。?
- 采用了以數據為中心的人工智能策略:(1)僅使用Reddit的出站鏈接來控制/過濾數據,該鏈接至少收到3個結果;(2)使用工具Dragnet和Newspaper提取“干凈”的內容;(3)采用重復數據消除和其他一些基于啟發式的凈化方法(論文中沒有提到細節)。?
- 訓練結果:凈化后得到40GB的文本。GPT-2無需微調即可實現強大的零樣本結果。?
- 使用了以數據為中心的人工智能策略:(1)訓練分類器,根據每個文檔與WebText的相似性篩選出低質量文檔,WebText是高質量文檔的代理。(2)使用Spark的MinHashLSH對文檔進行模糊的重復數據消除。(3)使用WebText、圖書語料庫和維基百科來增強數據。?
- 訓練結果:從45TB的明文中過濾得到570GB的文本(在本次質量過濾中僅選擇1.27%的數據)。在零樣本設置中,GPT-3顯著優于GPT-2。?
- 使用了以數據為中心的人工智能策略:(1)使用人工提供的提示答案,通過監督訓練調整模型。(2)收集比較數據以訓練獎勵模型,然后使用該獎勵模型通過來自人類反饋的強化學習(RLHF)來調整GPT-3。?
- 訓練結果:InstructGPT顯示出更好的真實性和更少的偏差,即更好的一致性。?
- GPT-2:使用??WebText??來進行訓練。這是OpenAI中的一個內部數據集,通過從Reddit中抓取出站鏈接創建。
- GPT-3:GPT-3的訓練主要基于??Common Crawl工具??。
- InstructGPT:讓人類評估調整GPT-3的答案,使其能夠更好地符合人類的期望。他們為注釋器設計了測試,只有那些能夠通過測試的人才有資格進行注釋。此外,他們甚至還設計了一項調查,以確保注釋者喜歡注釋過程。?
- ChatGPT/GPT-4:OpenAI未披露詳細信息。但眾所周知,ChatGPT/GPT-4在很大程度上遵循了以前GPT模型的設計,它們仍然使用RLHF來調整模型(可能有更多、更高質量的數據/標簽)。人們普遍認為,隨著模型權重的增加,GPT-4使用了更大的數據集。?
其次,進行推理數據開發。由于最近的GPT模型已經足夠強大,我們可以通過在固定模型的情況下調整提示(或調整推理數據)來實現各種目標。例如,我們可以通過提供摘要的文本以及“summarize it”或“TL;DR”等指令來進行文本摘要,以指導推理過程。?

??提示符微調??,圖片由作者提供
設計正確的推理提示是一項具有挑戰性的任務。它在很大程度上依賴于啟發式技術。一項很好的調查總結了目前為止人們使用的不同的提示方法。有時,即使在語義上相似的提示也可能具有非常不同的輸出。在這種情況下,可能需要基于軟提示的校準來減少差異。?
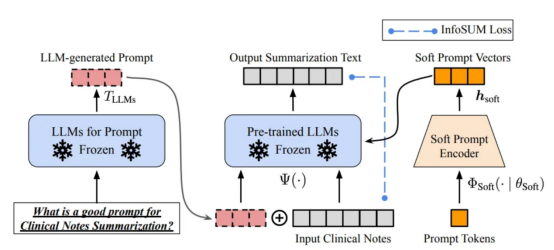
基于軟提示符的校準。本圖像來自于論文https://arxiv.org/abs/2303.13035v1,經原作者許可?
大型語言模型推理數據開發的研究仍處于早期階段。在不久的將來,已經在其他任務中使用的更多推理數據開發技術可能會應用于大型語言模型領域。?
就數據維護方面來說,ChatGPT/GPT-4作為一種商業產品,并不僅僅是訓練一次成功的,而是需要不斷更新和維護。顯然,我們不知道數據維護是如何在OpenAI之外執行的。因此,我們討論了一些以數據為中心的通用人工智能策略,這些策略很可能已用于或將用于GPT模型:?
- 持續數據收集:當我們使用ChatGPT/GPT-4時,我們的提示/反饋反過來可以被OpenAI用來進一步推進他們的模型。可能已經設計和實施了質量指標和保證策略,以便在此過程中收集高質量的數據。?
- 數據理解工具:有可能已經開發出各種工具來可視化和理解用戶數據,促進更好地理解用戶的需求,并指導未來的改進方向。?
- 高效的數據處理:隨著ChatGPT/GPT-4用戶數量的快速增長,需要一個高效的數據管理系統來實現快速的數據采集。
ChatGPT/GPT-4系統能夠通過如圖所示的“拇指向上”和“拇指向下”兩個圖標按鈕收集用戶反饋,以進一步促進他們的系統發展。此處屏幕截圖來自于https://chat.openai.com/chat。?
數據科學界能從這一波大型語言模型中學到什么?
大型語言模型的成功徹底改變了人工智能。展望未來,大型語言模型可能會進一步徹底改變數據科學的生命周期。為此,我們做出兩個預測:?
- 以數據為中心的人工智能變得更加重要。經過多年的研究,模型設計已經非常成熟,尤其是在Transformer之后。工程數據成為未來改進人工智能系統的關鍵(或可能是唯一)方法。此外,當模型變得足夠強大時,我們不需要在日常工作中訓練模型。相反,我們只需要設計適當的推理數據(即時工程)來從模型中探索知識。因此,以數據為中心的人工智能的研發將推動未來的進步。?
- 大型語言模型將實現更好的以數據為中心的人工智能解決方案。在大型語言模型的幫助下,許多乏味的數據科學工作可以更有效地進行。例如,ChaGPT/GPT-4已經可以編寫可操作的代碼來處理和清理數據。此外,大型語言模型甚至可以用于創建用于訓練的數據。例如,最近的工作表明,使用大型語言模型生成合成數據可以提高臨床文本挖掘中的模型性能。?
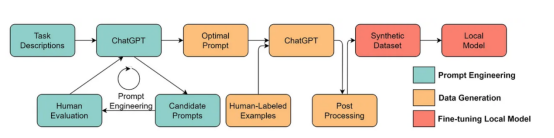
使用大型語言模型生成合成數據以訓練模型,此處圖像來自論文https://arxiv.org/abs/2303.04360,經原作者許可?
參考資料
我希望這篇文章能在你自己的工作中給你帶來啟發。您可以在以下論文中了解更多關于以數據為中心的人工智能框架及其如何為大型語言模型帶來好處:?
[1]??以數據為中心的人工智能綜述??。
[2]??以數據為中心的人工智能前景與挑戰??。
注意,我們還維護了一個??GitHub代碼倉庫??,它將定期更新相關的以數據為中心的人工智能資源。
在以后的文章中,我將深入研究以數據為中心的人工智能的三個目標(訓練數據開發、推理數據開發和數據維護),并介紹具有代表性的方法。?
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。?
原文標題:??What Are the Data-Centric AI Concepts behind GPT Models???,作者:Henry Lai?













