索引合并,能不用就不要用吧!
在前面的文章中,松哥和小伙伴們分享了 MySQL 中,InnoDB 存儲引擎的數據結構,小伙伴們知道,當我們使用索引進行搜索的時候,每一次的搜索都是在某一棵 B+Tree 中搜索的,如果使用了二級索引的話,可能還會涉及到回表。
那么現在問題來了,如果我們的搜索條件中包含兩個字段,且這兩個字段都有獨立的索引,那么 MySQL 會怎么處理?今天我們就來討論下這個話題。
1. 問題重現
為了方便小伙伴們理解,我先通過 SQL 來把我的問題重復一下。
我使用的測試數據是 MySQL 官網提供的測試數據,相關的介紹文檔在:
- https://dev.mysql.com/doc/employee/en/
相應的數據庫腳本在:
- https://github.com/datacharmer/test_db
小伙伴們可以自行下載這個數據庫腳本并導入到自己的數據庫之中。
在官方提供的案例中,有一個這樣的表:
CREATE TABLE `film_actor` (
`actor_id` smallint unsigned NOT NULL,
`film_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`,`film_id`),
KEY `idx_fk_film_id` (`film_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;在這個表中有兩個索引,其中一個是主鍵索引,主鍵索引是一個聯合索引,還有一個是根據 film_id 建立的普通索引。現在假設我有如下 SQL 需要執行:
select * from film_actor where film_id=1 or actor_id=1;那么問題來了,這個查詢會用到索引嗎?
想知道有沒有用到索引,用 explain 關鍵字看一下就知道了:
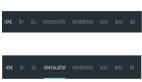
explain select * from film_actor where film_id=1 or actor_id=1;執行結果如下:

小伙伴們看到,此時 type 是 index_merge,possible_keys 和 key 中,都給出來了兩個索引,Extra 中的值為 Using union(idx_fk_film_id,PRIMARY); Using where。
看起來是用了索引,但是具體是怎么用的,這個執行計劃該如何解讀呢?
這個其實就是一個索引合并,接下來我們就來看下到底什么是索引合并。
2. 索引合并
index_merge 表示索引合并,當同一個表中的搜索條件中同時存在多個索引的時候,MySQL 會分別對這些索引進行掃描,然后將掃描結果進行合并,合并分三種情況:
- 對各自掃描結果求并集(unions)。
- 對各自掃描結果求交集(intersections)。
- 前兩者的組合。
在官方文檔中給了四個可能會用到索引合并的例子:
SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20;
SELECT * FROM tbl_name
WHERE (key1 = 10 OR key2 = 20) AND non_key = 30;
SELECT * FROM t1, t2
WHERE (t1.key1 IN (1,2) OR t1.key2 LIKE 'value%')
AND t2.key1 = t1.some_col;
SELECT * FROM t1, t2
WHERE t1.key1 = 1
AND (t2.key1 = t1.some_col OR t2.key2 = t1.some_col2);有的時候,我們寫的 SQL,明明可以合并,但是系統卻沒有合并,此時我們對查詢條件做一些調整,例如:
- (x AND y) OR z => (x OR z) AND (y OR z)
- (x OR y) AND z => (x AND z) OR (y AND z)
另外需要注意的是,索引合并不適用于全文索引。
在 explain 執行計劃中,如果用到了索引合并,Extra 字段的值一般分為三種情況,分別是:
- Using intersect(...)
- Using union(...)
- Using sort_union(...)
上文案例屬于第二種情況。
那么接下來把這三種情況都來和小伙伴們聊一下。
2.1 Using intersect(...)
這個就是對多個掃描結果求交集。
并不是只要涉及到多個索引,且是 AND,就會觸發 Using intersect,有兩個條件:
- 如果是二級索引,則必須是等值查詢。如果二級索引是復合索引,則復合索引的每一列都必須覆蓋到,不能只是其中的某幾列。
- 主鍵索引可以是范圍查詢。
我們來看官方給出的一個例子,如下:
key_part1 = const1 AND key_part2 = const2 ... AND key_partN = constNkey_part1 - key_partN 就是復合索引中的所有列(必須是所有列)。
對于第 2 點,如果涉及到主鍵索引,則主鍵索引可以是范圍查詢,例如下面這樣(但是二級索引依然只能是等值查詢):
SELECT * FROM innodb_table WHERE primary_key < 10 AND key_col1 = 20;如果是復合索引和普通索引,那么復合索引必須覆蓋到所有列且復合索引和普通索引都要是等值匹配才可以,例如下面這樣:
SELECT * FROM tbl_name WHERE key1_part1 = 1 AND key1_part2 = 2 AND key2 = 2;key1_part1 和 key1_part2 分別表示同一個復合索引的第一列和第二列(一共就兩列),此時和 key2 一起作為查詢條件,也有可能會用到索引合并。
上面這些情況都是在各自搜索完成之后求交集。
舉一個簡單的例子吧,還是 MySQL 官方的測試數據,sakila 庫中有一個 actor 表,該表結構如下:
CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb3;可以看到,有一個主鍵,有一個普通索引,我執行如下 SQL:
select * from actor where actor_id<10 and last_name='WAHLBERG'執行計劃如下:

可以看到,用到了索引合并,且是 Using intersect。
2.2 Using union(...)
求并集的跟求交集的比較像,就是 AND 變成了 OR。
當二級索引是等值查詢,或者是組合索引,但是要求組合索引的每一列都必須覆蓋到,不能只是覆蓋到部分列,例如下面這個查詢條件:
key_part1 = const1 OR key_part2 = const2 ... OR key_partN = constNkey_part1~key_partN 就是同一個復合索引的不同列,同時在該復合索引中,也一共就只有這 N 個字段,這種情況就會用到 Using union。
InnoBD 表上的主鍵范圍查詢也有可能會觸發 Using union。
符合 2.1 小節的情況,將 AND 換成 OR 之后,也有可能會觸發 Using union。
這個例子就不用舉了,文章一開始的就是。
2.3 Using sort_union(...)
很明顯,2.2 小節的條件比較苛刻,二級索引必須是等值查詢才能觸發 Using union,而我們日常使用的時候,范圍查詢也是非常常見的,所以又有了 Using sort_union,這個的要求就寬松一些了:
- 二級索引也可以按照范圍匹配
- 復合索引也不用覆蓋所有列
舉個例子,如下面的 SQL:
SELECT * FROM tbl_name
WHERE key_col1 < 10 OR key_col2 < 20;
SELECT * FROM tbl_name
WHERE (key_col1 > 10 OR key_col2 = 20) AND nonkey_col = 30;二級索引范圍搜索,也有可能觸發 Using sort_union 的。
2.4 索引合并原理
在 2.1 小節和 2.2 小節,分別是求交集和求并集,為了 intersect 和 union 操作方便,在各個單獨的索引掃描的時候,都是要獲取到有序的主鍵值的合集,各個索引都獲取到有序的主鍵,然后求交集或者并集就會比較方便。
因此,在 2.1 和 2.2 小節,都是主鍵索引可以范圍搜索,因為主鍵索引本身主鍵就是有序的;二級索引則有諸多限制,這諸多限制的最終目的都是為了做到最終拿到的主鍵值是有序的。
例如:
- 二級索引必須等值匹配,等值匹配意味著最終拿到的 B+Tree 的葉子上的主鍵值就是唯一的;二級索引如果可以按照范圍查找,那么最終從二級索引的 B+Tree 的葉子結點上拿到的主鍵值就不是有序的了。
- 類似的,復合索引必須覆蓋到所有列也是相似的原因,因為如果沒有覆蓋到所有列,意味著最終拿到的主鍵值也是無序的。
2.3 小節允許二級索引按照范圍搜索,這是因為在 Using sort_union 中,會先對拿到的主鍵值進行排序,然后才會去求交集或者并集,當然,相比于 2.1 和 2.2 小節,2.3 小節的性能也會降低一些。
3. 索引合并的問題
索引合并看著似乎提升了 MySQL 搜索的性能,然而,一般出現索引合并,大概率都是因為索引創建的不合理,我們需要重新審視自己的索引。
如上面 2.3 小節所述,這種方式在查詢的過程中需要緩存臨時數據、需要排序然后才能求交集或者并集,這些操作都會消耗掉大部分的 CPU 和內存資源。并且這些消耗不會被計算到查詢成本中,因為 MySQL 優化器只關心隨機頁面的讀取問題,并不會關心這里涉及到的這些額外計算問題,所以,在一些極端情況下,索引合并的性能可能還不如全表掃描。
因此,有時候如果我們確定自己不需要索引合并,那么可以通過 ignore index 來忽略掉一些索引,如下(對比 2.1 小節截圖):

也可以通過 optimizer_switch 來關閉索引合并功能,如下:

好啦,索引合并就和小伙伴們聊這么多吧~感興趣的小伙伴也可以嘗試下哦!