什么是生成式人工智能?人工智能的進化
生成式人工智能是使用算法生成、操作或合成數據的任何自動化過程的總稱,通常以圖像或人類可讀文本的形式出現。之所以稱之為生成,是因為人工智能創造了以前不存在的東西。這就是它與判別式人工智能的不同之處,后者會區分不同類型的輸入。換句話說,辨別性人工智能試圖回答這樣的問題:“這張圖片是一只兔子還是一只獅子?”而生成式人工智能則會回應“給我畫一張獅子和一只兔子坐在一起的圖片”這樣的提示。

主要介紹生成式AI及其與ChatGPT和DALL-E等流行模型的使用。我們還將考慮這項技術的局限性,包括為什么“太多的手指”已經成為人工生成藝術的死贈品。
生成式人工智能的出現
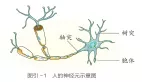
自從1966年麻省理工學院(MIT)開發出模擬與治療師交談的聊天機器人ELIZA以來,生成式人工智能已經存在多年。但是,隨著新的生成式人工智能系統的發布,人工智能和機器學習領域多年的工作最近取得了成果。人們肯定聽說過ChatGPT,這是一種基于文本的人工智能聊天機器人,可以產生非常像人類的散文。DALL-E和StableDiffusion也因其基于文本提示創建充滿活力和逼真的圖像的能力而引起關注。我們經常將這些系統和其他類似的系統稱為模型,因為它們代表了基于一個子集(有時是一個非常大的子集)的信息來模擬或建模現實世界的某些方面的嘗試。
這些系統的輸出是如此的不可思議,以至于很多人對意識的本質提出了哲學問題,并擔心生成式人工智能對人類工作的經濟影響。但是,盡管所有這些人工智能創造都是不可否認的大新聞,但表面之下的事情可能比一些人想象的要少。我們稍后會討論這些大問題。首先,讓我們看看像ChatGPT和DALL-E這樣的模型下面發生了什么。
生成式人工智能是如何工作的?
生成式人工智能使用機器學習來處理大量的視覺或文本數據,其中大部分是從互聯網上抓取的,然后確定哪些東西最有可能出現在其他東西附近。生成式人工智能的大部分編程工作都是為了創建算法,這些算法可以區分人工智能創造者感興趣的“事物”——比如ChatGPT這樣的聊天機器人的單詞和句子,或者DALL-E的視覺元素。但從根本上說,生成式人工智能是通過評估一個龐大的數據語料庫來創造它的輸出的,然后用語料庫確定的概率范圍內的東西來回應提示。
自動補全——當你的手機或Gmail提示你正在輸入的單詞或句子的剩余部分可能是什么——是一種低級形式的生成式人工智能。像ChatGPT和DALL-E這樣的模型只是把這個想法帶到了更先進的高度
訓練生成式人工智能模型
開發模型以適應所有這些數據的過程稱為訓練。對于不同類型的模型,這里使用了一些基礎技術。ChatGPT使用所謂的轉換器(T就是這個意思)。轉換器從長文本序列中獲取意義,以理解不同的單詞或語義組件之間的關系,然后確定它們彼此接近出現的可能性。這些變形器在一個被稱為預訓練(PinChatGPT)的過程中,在無人監督的情況下在大量自然語言文本的語料庫上運行,然后由人類與模型交互進行微調。
另一種用于訓練模型的技術被稱為生成對抗網絡(GAN)。在這種技術中,有兩種算法相互競爭。一種是基于從大數據集獲得的概率生成文本或圖像;另一種是判別人工智能,它經過人類的訓練,可以評估輸出是真實的還是人工智能生成的。生成式AI會反復嘗試“欺騙”具有辨別能力的AI,自動適應成功的結果。一旦生成式人工智能持續“贏得”這場競爭,具有辨別能力的人工智能就會被人類微調,這個過程就會重新開始。
這里要記住的最重要的事情之一是,盡管在訓練過程中存在人工干預,但大多數學習和適應都是自動發生的。為了使模型產生有趣的結果,需要進行許多次迭代,因此自動化是必不可少的。這個過程需要大量的計算。
生成式人工智能有感知能力嗎?
用于創建和訓練生成AI模型的數學和編碼相當復雜,遠遠超出了本文的范圍。但如果你與這個過程的最終結果模型互動,這種體驗肯定是不可思議的。你可以讓戴爾-e生產出看起來像真正的藝術品的東西。您可以與ChatGPT進行對話,就像與另一個人進行對話一樣。研究人員真的創造了一臺會思考的機器嗎?
ChrisPhipps是IBM公司前自然語言處理主管,曾參與沃森人工智能產品的開發。他將ChatGPT描述為“非常好的預測機器”。
它非常擅長預測人類會發現什么是連貫的。它并不總是連貫的(大多數情況下是),但這并不是因為ChatGPT“理解”。事實恰恰相反:消費產出的人真的很擅長做出我們需要的任何隱含假設,以使產出有意義。
菲普斯也是一名喜劇演員,他將其與一種名為MindMeld的常見即興游戲進行了比較。
兩個人每人想到一個詞,然后同時大聲說出來——你可以說“boot”,我說“tree”。我們完全獨立地想出了這些詞,一開始,它們彼此之間沒有任何關系。接下來的兩個參與者拿著這兩個詞,試著找出他們的共同點,同時大聲說出來。游戲繼續進行,直到兩個參與者說出同一個單詞。
也許兩個人都說“伐木工人”。這看起來很神奇,但實際上是我們用人類的大腦來推理輸入(“boot”和“tree”),并找到其中的聯系。我們做的是理解的工作,而不是機器。在ChatGPT和DALL-E中發生的事情比人們承認的要多得多。ChatGPT可以編寫故事,但我們人類要做很多工作才能使其有意義。
測試計算機智能的極限
人們可以給這些人工智能模型一些提示,這將使菲普斯的觀點變得相當明顯。例如,想想這個謎題:“一磅鉛和一磅羽毛,哪個更重?”答案當然是它們的重量相同(一磅),盡管我們的本能或常識可能會告訴我們羽毛更輕。
ChatGPT將正確地回答這個謎題,您可能會認為它這樣做是因為它是一臺冷酷的邏輯計算機,沒有任何“常識”來絆倒它。但這并不是幕后發生的事情。ChatGPT不是邏輯推理出答案;它只是根據一個關于一磅羽毛和一磅鉛的問題的預測來產生輸出。因為它的訓練集包含了一堆解釋謎題的文本,所以它組裝了一個正確答案的版本。但是,如果你問ChatGPT兩磅羽毛是否比一磅鉛重,它會自信地告訴你它們的重量相同,因為根據它的訓練集,這仍然是最有可能輸出到關于羽毛和鉛的提示的結果。