【大數(shù)據(jù)】Yarn Proxyserver 和 Historyserver 講解
一、YARN Proxy 概述
Web應用程序代理是YARN的一部分。默認情況下,它將作為資源管理器(RM)的一部分運行,但可以配置為以獨立模式運行。代理的原因是為了減少通過YARN進行基于網(wǎng)絡的攻擊的可能性。
- 在YARN中,應用主機(AM)有責任提供web UI并將該鏈接發(fā)送到RM。這引發(fā)了許多潛在的問題。RM以受信任用戶的身份運行,訪問該網(wǎng)址的人會將其及其提供給他們的鏈接視為受信任,而實際上AM是以不受信任用戶身份運行的,并且它提供給RM的鏈接可能指向任何惡意或其他內(nèi)容。Web應用程序代理通過警告不擁有給定應用程序的用戶他們正在連接到不受信任的網(wǎng)站來減輕這種風險。
- 除此之外,代理還試圖減少惡意AM可能對用戶造成的影響。它主要通過從用戶身上剝離cookie,并用一個提供登錄用戶用戶名的cookie來替換它們。這是因為大多數(shù)基于網(wǎng)絡的身份驗證系統(tǒng)都會根據(jù)cookie來識別用戶。通過將此cookie提供給不受信任的應用程序,它打開了利用此cookie的可能性。如果cookie設計得當,那么潛力應該相當小,但這只是為了減少潛在的攻擊向量。
使用YARN Proxy,您可以做到以下幾點:
- 查看YARN集群的基本信息,包括作業(yè)的概述、cluster的Metrics和最近的作業(yè)歷史。
- 查看當前正在運行的作業(yè)列表,并對其進行管理。
- 查看每個NodeManager的概述,以及它們所在的機器的系統(tǒng)和硬件資源使用情況。
- 查看和搜索集群日志。
- 查看簡化的配置和狀態(tài)信息,以及錯誤報告。
- 使用REST API進行遠程調(diào)用和管理。
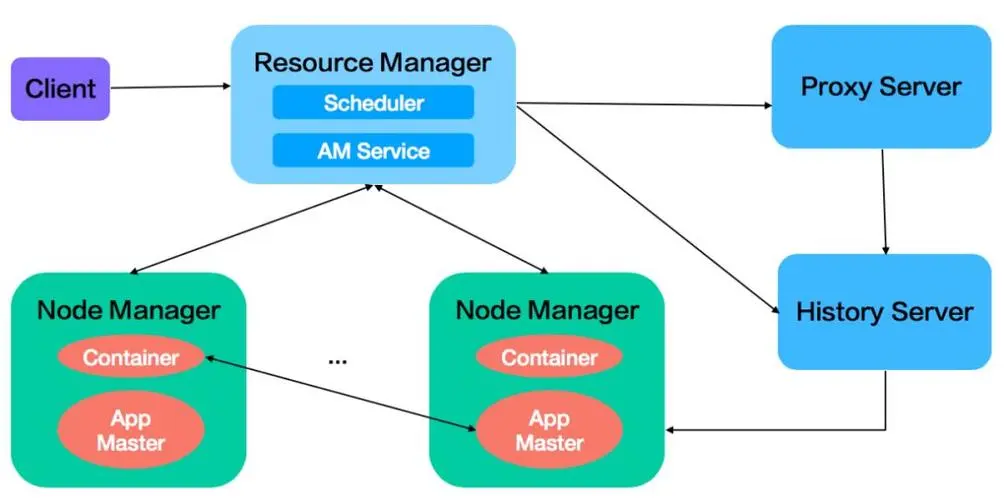
yarn proxyserver 配置參數(shù) yarn.web-proxy.address。用于分發(fā)Resource Manager訪問請求。
從Resourcemanager上點擊正在執(zhí)行的app,會跳轉(zhuǎn)到 yarn.web-proxy.address,這里展現(xiàn)正在執(zhí)行的job信息,job執(zhí)行結(jié)束后,會跳轉(zhuǎn)到historyserver上;若是沒有配置 yarn.web-proxy.address,則這個功能會集成到RM中。
官方文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WebApplicationProxy.html
二、環(huán)境準備
如果已經(jīng)有了環(huán)境了,可以忽略,如果想快速部署環(huán)境進行測試可以參考我這篇文章:通過 docker-compose 快速部署 Hive 詳細教程
# 登錄容器
docker exec -it hive-hiveserver2 bash
# 連接hive
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop三、Hadoop 中的 historyserver
1)MapReduce Job History
MapReduce Job History,通常簡稱為“Job History”,是Hadoop MapReduce框架的一部分,用于記錄已完成作業(yè)(job)的信息,包括它們的輸入輸出、計數(shù)器、任務(task)嘗試次數(shù)和任務失敗原因等。By默認情況下,Job History將日志聚合到本地文件系統(tǒng),可以通過啟用HistoryServer來統(tǒng)一管理和監(jiān)視所有作業(yè)的歷史記錄。
2)Spark History Server
Spark通過Spark History Server記錄了應用程序的歷史記錄。Spark History Server是一個可選的Web界面,用于查看已完成的應用程序的事件和元數(shù)據(jù)。Spark集群中的所有工作節(jié)點都會將應用程序的事件信息存儲在本地磁盤上。當應用程序完成后,它們的事件信息會被拷貝到Spark History Server節(jié)點所在的位置。
Spark History Server默認情況下會監(jiān)聽 18080 端口,您可以在瀏覽器中訪問http://<host>:18080檢查已完成的應用程序。
Spark History Server提供了以下幾種功能:
- 查看已完成應用程序的摘要信息,包括完成時間、運行時間、狀態(tài)、應用程序ID和應用程序名稱等。
- 查看應用程序的所有階段和任務的摘要信息,包括階段ID、父級階段、任務ID、任務類型和任務執(zhí)行時間等。
- 查看應用程序的計數(shù)器信息,了解它們所使用的資源。
- 查看應用程序執(zhí)行期間的事件信息,例如Spark應用程序的RDD、計算圖或輸出操作,以及在內(nèi)存、磁盤或網(wǎng)絡中執(zhí)行的任務。
總之,Spark History Server提供了一種簡單的方法,可以查看Spark應用程序的歷史記錄,包括成功或失敗的應用程序的事件和元數(shù)據(jù),以便進行分析和性能調(diào)整。
3)Flink History Server
Flink也有類似于Spark的History Server功能來記錄應用程序的歷史記錄。Flink History Server是一個用于查看和管理已完成的Flink應用程序的Web界面。
Flink History Server會收集已完成的應用程序的事件信息和日志并保存在HDFS上。Flink歷史服務器本身本身是一個獨立的Flink應用程序,它會檢索、解析和存儲存儲在HDFS上的事件信息和日志,用戶可以在Web界面中查看所有已完成應用程序的詳細信息和日志。
Flink History Server提供以下幾個功能:
- 查看已完成應用程序的總體摘要信息,包括DAG、計數(shù)器、開始時間、結(jié)束時間和狀態(tài)等,可以從每個應用程序的監(jiān)視視圖鏈接到此處。
- 查看已完成應用程序的詳細摘要信息,包括自定義計數(shù)器和速率指標等,同時還提供查看作業(yè)執(zhí)行計劃、Web UI日志和單個任務的摘要信息的鏈接。
- 通過不同的方式搜索和過濾應用程序,例如按作業(yè)ID、作業(yè)名稱、狀態(tài)、起始日期和結(jié)束日期等查詢。
- 查看歷史記錄詳情,可以查看Flink任務、操作符和物理執(zhí)行計劃的完整概覽,并提供任務日志和操作符跟蹤的鏈接。
總之,F(xiàn)link History Server是一個很有用的工具,可以允許您查看和分析Flink作業(yè)的執(zhí)行情況。它提供了豐富的功能,如過濾、搜索、摘要等,使得您可以更好地了解應用程序的執(zhí)行過程。
四、相關配置
1)yarn proxyserver 配置
配置如下:
$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
...
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop-yarn-proxyserver:9111</value>
</property>
...
</configuration>2)historyserver 配置
1、MapReduce Job History
mapreduce.jobhistory.address 和 mapreduce.jobhistory.webapp.address 都是與MapReduce作業(yè)歷史記錄(JobHistory)相關的配置屬性。它們分別指定JobHistory服務器運行的地址(IP地址或域名)和端口號,以及Web界面的地址和端口號。
- mapreduce.jobhistory.address 用于指定JobHistory服務器的地址(IP地址或域名)和端口號,讓MapReduce框架知道將作業(yè)歷史記錄發(fā)送到哪個服務器。例如:
- mapreduce.jobhistory.webapp.address 用于指定JobHistory服務器的Web界面地址和端口號,讓用戶可以通過Web訪問作業(yè)歷史記錄。例如:
配置文件:$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
...
<!-- MR程序歷史服務地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-mr-historyserver:10020</value>
</property>
<!-- MR程序歷史服務web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-mr-historyserver:19888</value>
</property>
...
</configuration>2、Spark History Server
修改 spark-defaults.conf,添加如下內(nèi)容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-hdfs-nn:9000/sparkhistory
spark.driver.memory 64g
spark.eventLog.compress true修改spark-env.sh,添加如下內(nèi)容:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=7777 -Dspark.history.fs.logDirectory=hdfs://hadoop-hdfs-nn:9000/sparkhistory"3、Flink History Server
Flink 提供了 history server,可以在相應的 Flink 集群關閉之后查詢已完成作業(yè)的統(tǒng)計信息。此外,它暴露了一套 REST API,該 API 接受 HTTP 請求并返回 JSON 格式的數(shù)據(jù)。
配置項 jobmanager.archive.fs.dir 和 historyserver.archive.fs.refresh-interval 需要根據(jù) 作業(yè)存檔目錄 和 刷新作業(yè)存檔目錄的時間間隔 進行調(diào)整。
# 監(jiān)視以下目錄中已完成的作業(yè)
historyserver.archive.fs.dir: hdfs:///hadoop-hdfs-nn:9000/flinkhistory
historyserver.web.address: 0.0.0.0:8082
# 每 10 秒刷新一次
historyserver.archive.fs.refresh-interval: 10000五、yarn proxyserver 和 historyserver 啟停
1)yarn proxyserver 啟停
$HADOOP_HOME/bin/yarn --daemon start proxyserver
$HADOOP_HOME/bin/yarn --daemon stop proxyserver2)historyserver 啟停
1、MapReduce Job History 啟停
$HADOOP_HOME/bin/mapred --daemon start historyserver
$HADOOP_HOME/bin/mapred --daemon stop historyserver2、Spark History Server 啟停
$SPARK_HOME/sbin/start-history-server.sh
$SPARK_HOME/sbin/stop-history-server.sh【溫馨提示】start-history-server.sh 腳本默認情況下啟動Spark History Server只是將文件存儲在/tmp/spark-events目錄下,這是本地文件系統(tǒng)路徑。如果您沒有在配置文件中指定spark.history.fs.logDirectory屬性,則Spark History Server將在該目錄下保存事件日志和歷史記錄。對于開發(fā)和測試目的而言,這個默認的存儲路徑是足夠的。
3、Flink History Server 啟停
$FLINK_HOME/bin/historyserver.sh start
$FLINK_HOME/bin/historyserver.sh stop