【大數據】Hive 分區和分桶的區別及示例講解
一、概述
在大數據處理過程中,Hive是一種非常常用的數據倉庫工具。Hive分區和分桶是優化Hive性能的兩種方式,它們的區別如下:
1、分區概述
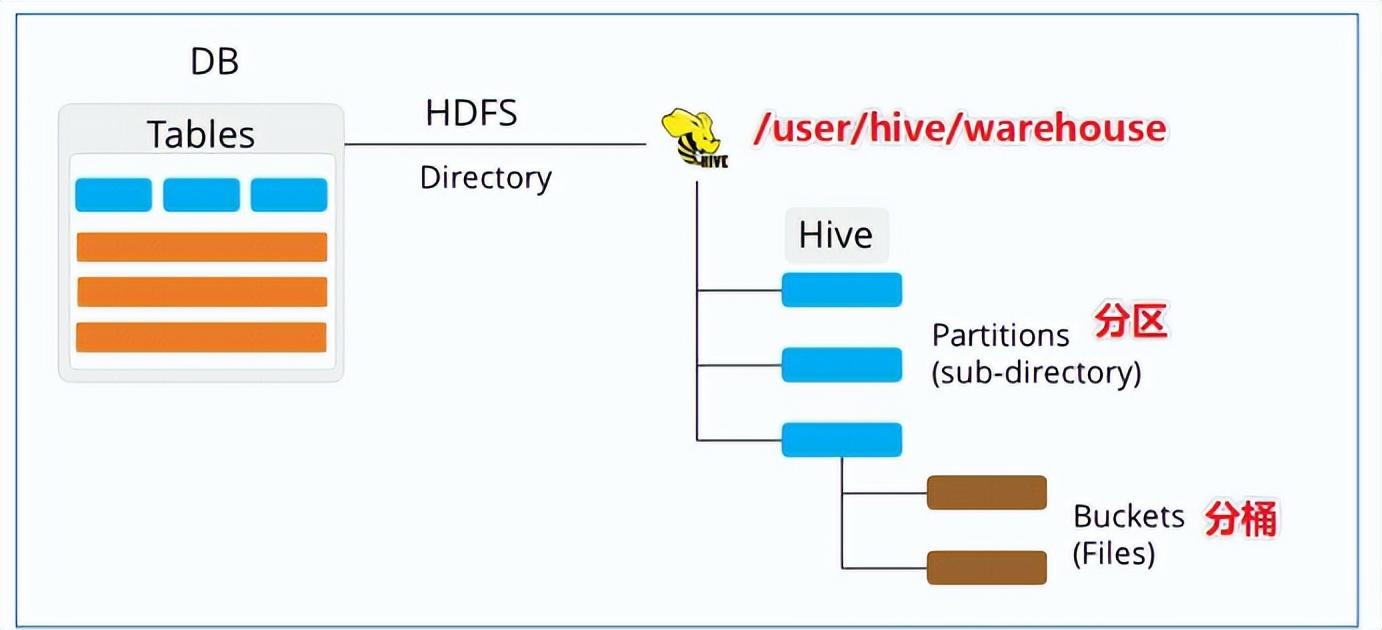
Hive分區是把數據按照某個屬性分成不同的數據子集。
- 在Hive中,數據被存儲在HDFS中,每個分區實際上對應HDFS下的一個文件夾,這個文件夾中保存了這個分區的數據。
- 因此,在Hive中使用分區,實際上是將數據按照某個屬性值進行劃分,然后將相同屬性值的數據存儲在同一個文件夾中。Hive分區的效率提升主要是因為,當進行查詢操作時,只需讀取與查詢相關的數據分區,避免了全表掃描,節約了查詢時間。
Hive分區的主要作用是:
- 提高查詢效率: 使用分區對數據進行訪問時,系統只需要讀取和此次查詢相關的分區,避免了全表掃描,從而顯著提高查詢效率。
- 降低存儲成本: 分區可以更加方便的刪除過期數據,減少不必要的存儲。
2、分桶概述
Hive分桶是將數據劃分為若干個存儲文件,并規定存儲文件的數量。
- Hive分桶的實現原理是將數據按照某個字段值分成若干桶,并將相同字段值的數據放到同一個桶中。在存儲數據時,桶內的數據會被寫入到對應數量的文件中,最終形成多個文件。
- Hive分桶主要是為了提高分布式查詢的效率。它能夠通過將數據劃分為若干數據塊來將大量數據分發到多個節點,使得數據均衡分布到多個機器上處理。這樣分發到不同節點的數據可以在本地進行處理,避免了數據的傳輸和網絡帶寬的浪費,同時提高了查詢效率。
分桶的主要作用是:
- 數據聚合: 分桶可以使得數據被分成較小的存儲單元,提高了數據統計和聚合的效率。
- 均衡負載: 數據經過分桶后更容易實現均衡負載,數據可以分發到多個節點中,提高了查詢效率。
綜上所述,分區和分桶的區別在于其提供的性能優化方向不同。分區適用于對于數據常常進行的聚合查詢數據分析,而分桶適用于對于數據的均衡負載、高效聚合等方面的性能優化。當數據量較大、查詢效率比較低時,使用分區和分桶可以有效優化性能。分區主要關注數據的分區和存儲,而分桶則重點考慮數據的分布以及查詢效率。
二、環境準備
如果已經有了環境了,可以忽略,如果想快速部署環境可以參考我這篇文章:通過 docker-compose 快速部署 Hive 詳細教程
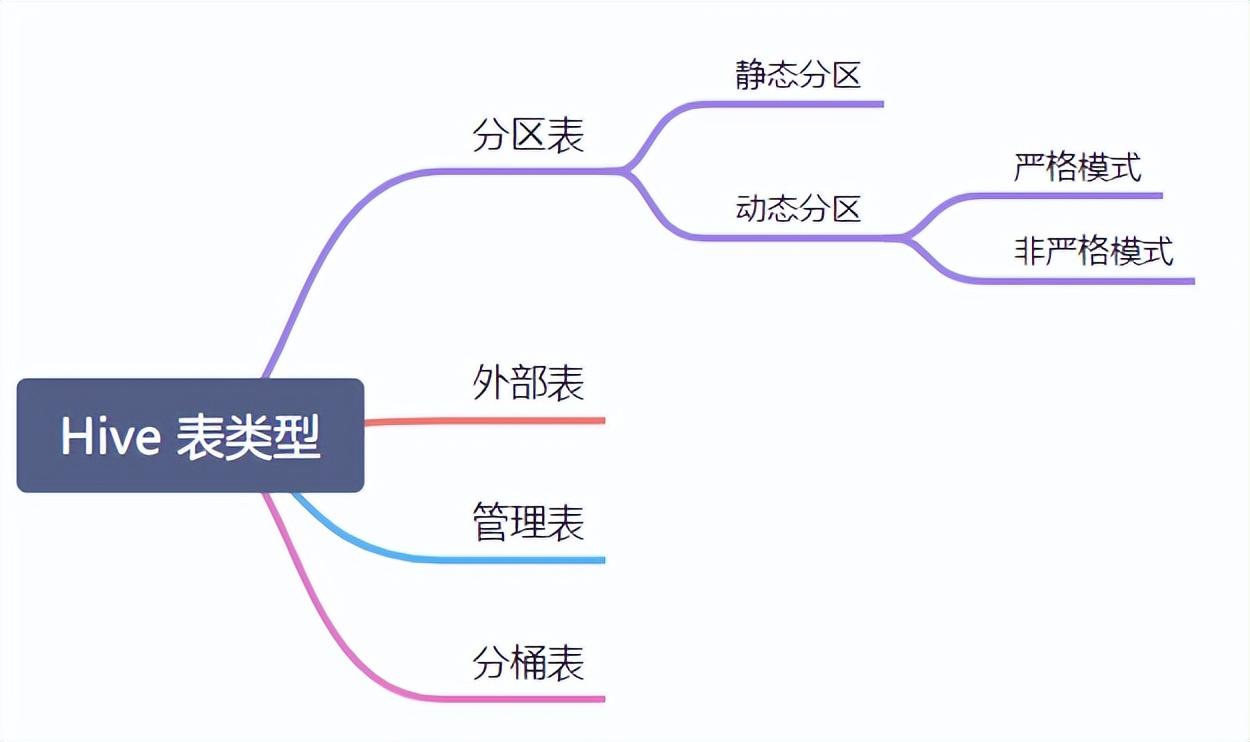
三、外部表和管理表
在Hive中,可以創建兩種類型的表:外部表和管理表。它們之間的主要區別如下:
1、外部表
1)外部表介紹
外部表是指在Hive中創建的表,實際上其數據是存儲在外部文件系統(HDFS或本地文件系統)中的。
- 外部分區表是一種特殊類型的表,它們的數據存儲在Hive之外的文件系統上,例如HDFS、S3等。
- 對于外部分區表,Hive只會管理它們的元數據信息,而不會管理數據文件本身,這意味著,如果你使用Hive命令刪除一個外部分區表,只會刪除該表的元數據,而不會刪除數據文件。
- 外部分區表通常用于存儲和管理原始數據,這些數據通常需要在多個系統和工具之間共享。
2)示例講解
【示例一】下面是創建Hive外部表的一個示例(數據存儲在HDFS):
假設我們有一個存儲在 HDFS 上的數據文件,其路徑為'/user/hive/external_table/data',我們可以通過以下語句,在Hive中創建一個外部表:
# 登錄容器
docker exec -it hive-hiveserver2
# 登錄hive客戶端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 建表
CREATE EXTERNAL TABLE external_table1 (
column1 STRING,
column2 INT,
column3 DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hive/external_table/data';在該表中,我們指定了表的各列的數據類型和分隔符等信息,并且使用了LOCATION 關鍵字來指定數據文件的存儲位置。這樣,在Hive中對該外部表進行查詢操作時,Hive會自動去對應的位置讀取數據文件,并據此返回查詢結果。
load 數據
# 模擬一些數據
cat >data<<EOF
c1,12,56.33
c2,14,58.99
c3,15,66.34
c4,16,76.78
EOF
# 登錄hive客戶端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 加載數據,local 是加載本機文件數據
load data local inpath './data' into table external_table1;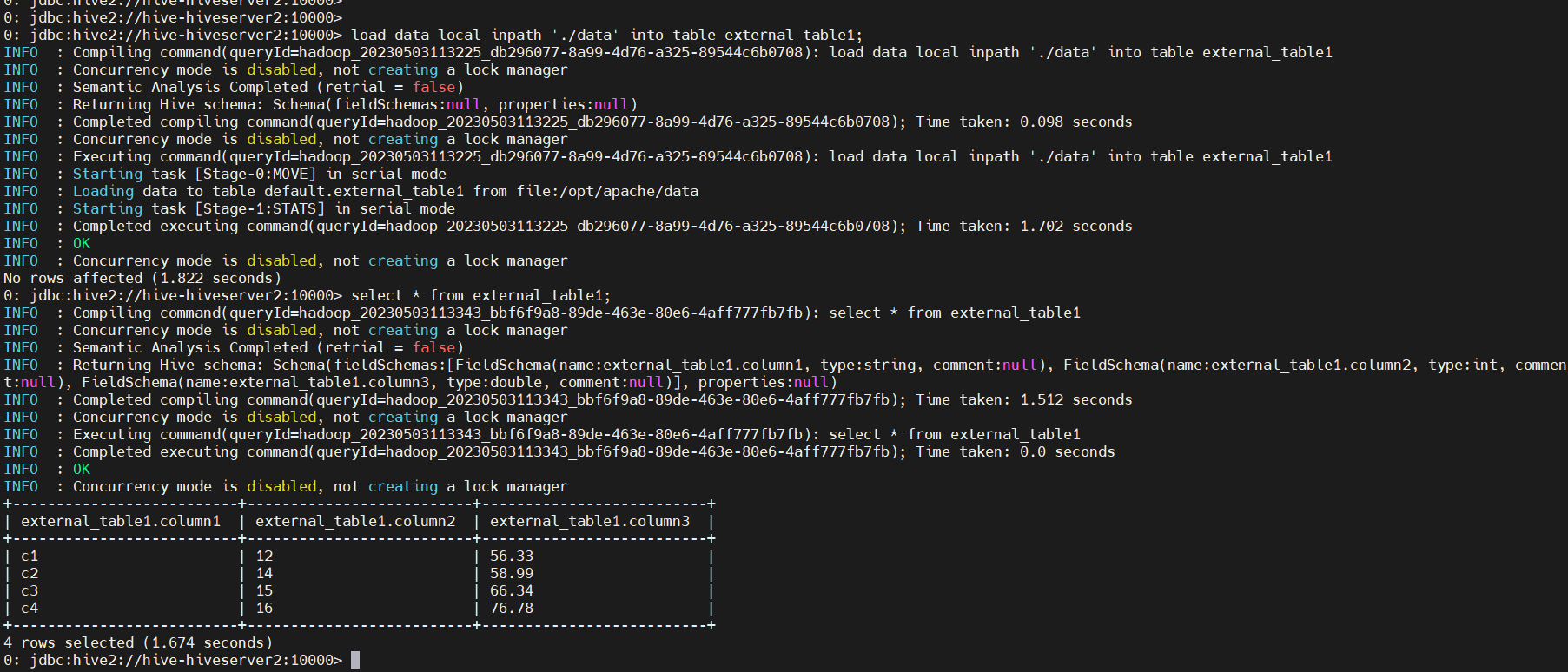
需要注意的是,在使用外部表時,我們必須保證Hive對數據文件的訪問權限與HDFS的文件權限相同,否則會導致外部表的查詢失敗。此外,在使用外部表時,務必不要刪除外部表的數據文件,否則將會導致查詢結果的不準確。
【示例一】下面是創建外部表訪問本地數據文件的示例(數據存儲在本地,很少使用):
在Hive中,我們同樣可以創建外部表來訪問本地文件系統上的數據文件。在這種情況下,我們需要注意的是,在Hive的配置中,必須開啟hive.stats.autogather 功能。否則,在查詢外部表時可能會出現錯誤。
假設我們有一個存儲在本地文件系統上的數據文件,路徑為'/path/to/local/file',我們可以通過以下語句,在Hive中創建一個外部表:
CREATE EXTERNAL TABLE external_table2 (
column1 STRING,
column2 INT,
column3 DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION 'file:///path/to/local/file';
### hive文件存儲格式包括以下幾類(STORED AS TEXTFILE):
#1、TEXTFILE
#2、SEQUENCEFILE
#3、RCFILE
#4、ORCFILE(0.11以后出現)
#其中TEXTFILE為默認格式,建表時不指定默認為這個格式,導入數據時會直接把數據文件拷貝到hdfs上不進行處理;需要注意的是,我們在使用LOCATION關鍵字時,要指定為'file:///path/to/local/file',而不是 '/path/to/local/file' ,這是因為我們需要使用文件系統的URL來訪問本地文件系統上的數據文件。
2、管理表(內部表)
1)管理表(內部表)介紹
管理表是利用Hive自身的存儲能力來對數據進行存儲和管理的表。在Hive中創建管理表時,必須指定數據的存儲路徑。
- 管理表也稱為內部表(Internal Table),管理表是Hive默認創建的表類型,它的數據存儲在Hive默認的文件系統上(通常是HDFS)。
- Hive會自動管理這些表的數據和元數據,包括表的位置、數據格式等。如果你使用Hive命令刪除了一個管理表,那么該表的數據也會被刪除。
- 通常情況下,管理表用于存儲和管理中間結果、匯總數據和基礎數據。當數據規模較小時,管理表是一個不錯的選擇,因為它可以提供更好的查詢性能,同時也更容易管理。
2)示例講解
在Hive中,除了外部表,我們還可以創建內部表來存儲數據。與外部表不同的是,內部表存儲的數據位于Hive自身管理的HDFS上,因此,在創建內部表時,我們需要確保數據可以被正確地上傳到HDFS上。下面是創建內部表并存儲在本機的示例:
假設我們有以下數據文件,名為data.csv,存儲在本地文件系統的/path/to/local目錄下:
cat >data.csv<<EOF
value1,1,2.3
value2,2,3.4
value3,3,4.5
EOF我們可以使用以下語句,在Hive中創建一個內部表:
CREATE TABLE internal_table (
column1 STRING,
column2 INT,
column3 DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
# 加載本地數據,LOCAL
LOAD DATA LOCAL INPATH './data.csv' INTO TABLE internal_table;
# 加載HDFS數據
# 先將文件推送到HDFS上
hdfs dfs -put ./data.csv /tmp/
# 登錄hive客戶端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 加載HDFS上的數據
LOAD DATA INPATH '/tmp/data.csv' INTO TABLE internal_table;
# 查詢
select * from internal_table;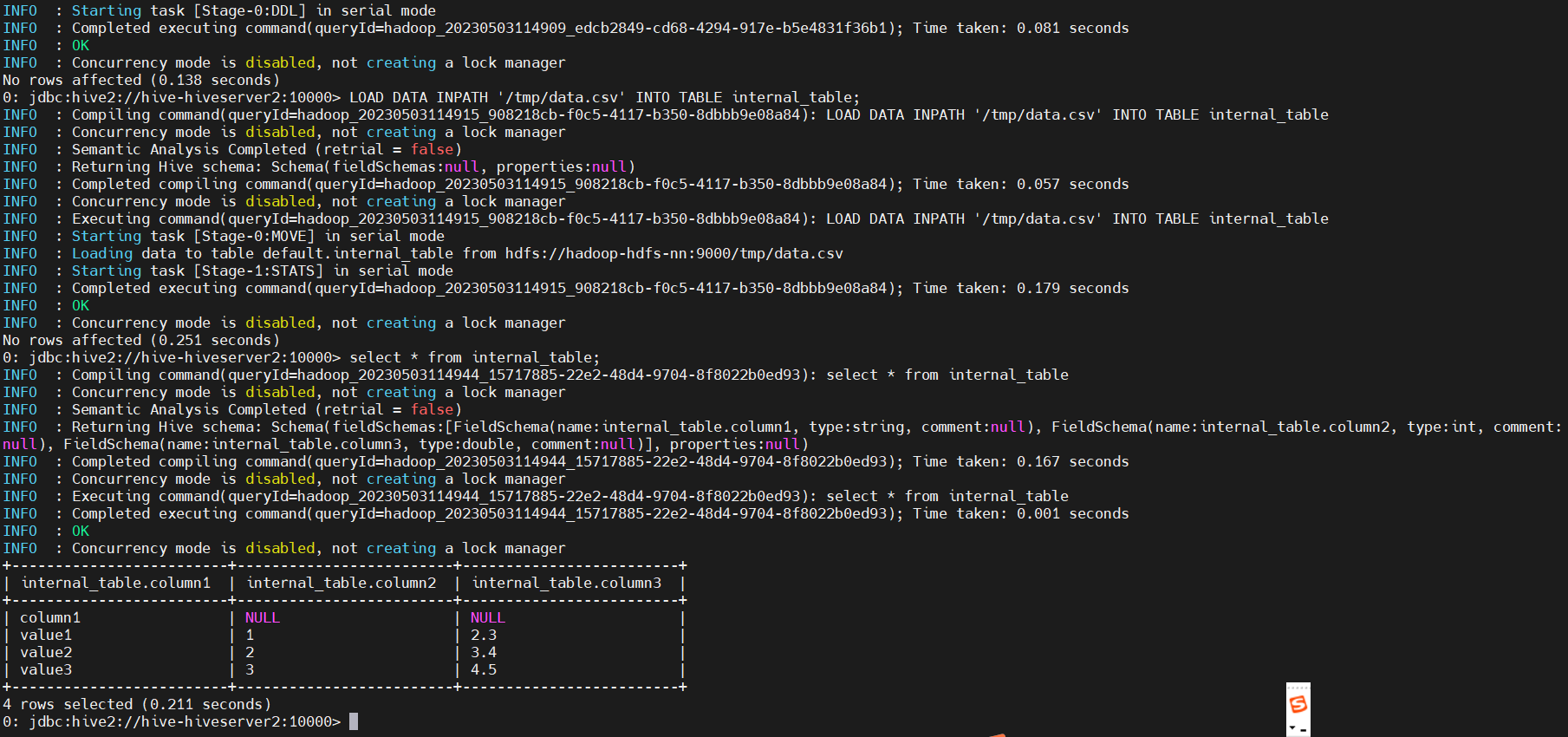
總之,外部表和管理表都可以在Hive中實現數據的存儲和管理,但它們之間的不同主要體現在數據的存儲和處理方式上。
四、分區表之靜態分區和動態分區
Hive中的分區表可以進一步細分為靜態分區和動態分區。
靜態分區是指通過手動指定分區列的值來創建分區。例如,在創建一個基于年份的分區表時,我們可以手動指定每個分區名對應的年份:
CREATE TABLE sales (
id int,
date string,
amount double
)
PARTITIONED BY (year string);
ALTER TABLE sales ADD PARTITION (year='2019') location '/data/sales/2022';
ALTER TABLE sales ADD PARTITION (year='2020') location '/data/sales/2023';在上述示例中,我們通過 ALTER TABLE 語句手動添加了2019和2020兩個年份的分區。
動態分區是指在加載數據時通過SQL語句自動創建分區。例如,在從一個包含銷售記錄的數據文件中加載數據時,可以自動根據數據中的年份信息創建相應的分區:
INSERT INTO TABLE sales PARTITION (year)
SELECT id, date, amount, YEAR(date)
FROM raw_sales;在上述示例中,我們使用 PARTITION 子句指定在 CREATE TABLE 語句中定義的分區列year,并使用 YEAR(date) 表達式從數據中提取出年份信息。
動態分區的優點在于它可以大大簡化創建和管理分區表的過程并提高效率;但是需要注意的是,它可能會在某些情況下產生不可預期的行為,例如可能創建太多分區。
總之,靜態分區和動態分區都是用于在Hive中管理大型數據集的有效工具,具體使用需要根據具體情況選擇最適合的方法,并理解它們的優點和缺點。
五、hive分區表嚴格模式和非嚴格模式
Hive分區表的嚴格模式和非嚴格模式可以通過以下兩個參數進行設置:
- hive.exec.dynamic.partition.mode:該參數用于設置分區模式,其默認值為strict,即嚴格模式。可以將其設置為nonstrict,即非嚴格模式:
# 登錄hive客戶端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 設置
SET hive.exec.dynamic.partition.mode=nonstrict;- hive.exec.max.dynamic.partitions:該參數用于限制動態分區的最大數量。在非嚴格模式下,當動態分區的數量超過該參數指定的值時,Hive將拋出異常。可以通過以下語句來修改該參數:
SET hive.exec.max.dynamic.partitions=<value>;其中,<value> 為一個整數值,表示限制的動態分區數量。如果需要取消該限制,可以將該參數設置為一個非正數,例如:
SET hive.exec.max.dynamic.partitions=-1;需要注意的是,這些參數的設置僅對當前會話有效,也可以將其添加到Hive的配置文件中以在每個會話中自動應用。
總之,hive.exec.dynamic.partition.mode 和 hive.exec.max.dynamic.partitions 是控制Hive分區表嚴格模式和非嚴格模式的兩個重要參數,開發人員可以根據自己的需求進行設置。
1)嚴格模式
嚴格模式要求在加載數據時必須指定所有分區列的值,否則將會導致拋出異常。例如,在下面的分區表中:
CREATE TABLE sales (
id int,
date string,
amount double
)
PARTITIONED BY (year string, month string, day string)
CLUSTERED BY (id) INTO 10 BUCKETS;在嚴格模式下,我們必須為year、month和day三個分區列的所有可能取值指定一個分區:
INSERT INTO TABLE sales PARTITION (year='2019', month='01', day='03')
SELECT id, date, amount
FROM raw_sales
WHERE YEAR(date) = 2019 AND MONTH(date) = 1 AND DAY(date) = 3;在上述示例中,我們使用 PARTITION 子句手動為分區列year、month、day指定取值。
2)非嚴格模式
非嚴格模式則允許忽略某些分區列的值,這樣使用 INSERT INTO 語句時只需指定提供的分區值即可。例如:
#
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO TABLE sales PARTITION (year, month, day)
SELECT id, YEAR(date), MONTH(date), DAY(date), amount
FROM raw_sales
WHERE YEAR(date) = 2019;在上述示例中,我們使用 SET 語句設置分區模式為非嚴格模式,然后只提供了year分區列的值,而month和day分區列的值是從數據中動態計算得出的。
使用非嚴格模式可以簡化分區表的創建和管理,但需要注意,它可能會產生一些意料之外的結果(例如可能創建太多分區),所以需要謹慎使用。
總之,分區表的嚴格模式和非嚴格模式都具有一些優點和缺點,具體使用需要根據具體情況選擇最適合的方式。
六、分區表和分桶表示例講解
1)分區表示例講解
在Hive中,我們可以使用分區表來更有效地組織和管理數據。分區表將數據分為子集,每個子集對應一個或多個分區。這樣,我們就可以更快地訪問和查詢數據,而不必掃描整個數據集。
創建分區表的語法類似于創建普通表,只不過要使用 PARTITIONED BY 子句指定一個或多個分區列,例如:
# 內部表
CREATE TABLE partitioned_internal_table (
id INT,
mesg STRING
)
PARTITIONED BY (
year INT,
month INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
# 外部表
CREATE EXTERNAL TABLE partitioned_external_table (
id INT,
mesg STRING
)
PARTITIONED BY (
year INT,
month INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hive/partitioned_table/data';上述語句創建了一個分區表,在列column1和column2的基礎上,按照year和month兩列進行了分區。
【注意】分區的實現依賴于Hive的底層存儲Hadoop分布式文件系統(HDFS)。為了確定如何分配數據,Hive要求每個分區對應一個目錄,該目錄包含該分區數據的所有文件。因此,在將數據加載到分區表中時,必須提供與分區對應的目錄。
例如,如果我們要將一個CSV文件加載到分區表中,我們可以使用以下語句:
LOAD DATA LOCAL INPATH './file.csv' INTO TABLE partitioned_external_table PARTITION (year=2019, month=1);
# 查看分區
show partitions partitioned_external_table;在上述語句中,我們使用 LOAD DATA 子句將 /data/file.csv 文件加載到partitioned_table 表中,并指定了分區year為2019,分區month為1。
假設我們的CSV文件具有以下內容:
1,test1,2019,1
1,test2,2019,1
2,test3,2022,1
3,test4,2023,1使用以下語句查詢分區表:
SELECT * FROM partitioned_external_table WHERE year=2019 AND month=1;分區表的優點在于可以更高效地組織數據,同時也允許我們根據需要刪除或添加分區。例如,我們可以使用以下語句刪除分區:
ALTER TABLE partitioned_table DROP PARTITION (year=2019, month=1);可以使用以下語句添加分區:
ALTER TABLE partitioned_external_table ADD PARTITION (year=2020, month=2);
# 查看分區
show partitions partitioned_external_table;總之,分區表是管理和查詢大型數據集的有效方式,可以幫助我們更輕松地處理大量數據。
2)分桶表示例講解
除了分區表之外,Hive還提供了另一種將數據分割成可管理單元的方式,即分桶。
分區和分桶的概念有一些相似之處,但也存在一些重要的區別。
- 分區是指基于表的某些列將數據分割成不同的存儲單元;
- 而分桶是指將數據根據哈希函數分成一組固定的桶。
類比于分區,在創建一個分桶表時,我們需要指定分桶的數量和分桶的列。例如,以下是一個創建分桶表的示例:
CREATE TABLE bucketed_table (
column1 data_type,
column2 data_type,
...
)
CLUSTERED BY (column1) -- 分桶列
INTO 10 BUCKETS; -- 桶數量在上述示例中,我們將column1作為分桶列,并將數據分成10個桶。
加載數據時,Hive根據指定的桶列計算哈希值,并將數據存儲在對應的桶中。
INSERT INTO TABLE bucketed_table VALUES ('value1', 1, 2.3)查詢時,可以使用以下格式指定桶列:
SELECT * FROM bucketed_table TABLESAMPLE(BUCKET x OUT OF y ON column1);在上述示例中,我們使用用于抽樣數據的 TABLESAMPLE 子句,指定從桶x中抽取數據,并在分桶列column1上進行抽樣。
分桶表的優點在于,我們可以更容易地執行等值和范圍查詢,并更好地利用MapReduce 的數據本地性,從而提高查詢性能。但分桶表也有一些缺點,例如添加和刪除數據涉及重新計算哈希函數和移動數據的成本。
總之,分區表和分桶表都是Hive管理和處理大型數據集的重要工具,可以幫助我們更輕松地組織、查詢和分析大量數據。在具體使用時,需要考慮表的存儲和查詢需求,選擇最適合的表類型。在實際場景中分區用的居多。