基于深度學習的姿態估計
譯文譯者 | 李睿
審校 | 重樓
什么是人體姿勢估計?
人體姿態估計是檢測和估計圖像或視頻中人物姿態的過程。它包括檢測人物身體的關鍵點或關節,例如頭部、肩膀、肘部、手腕、臀部、膝蓋和腳踝,并估計它們在圖像中的位置。這可以使用各種計算機視覺技術來完成,例如特征檢測和機器學習算法。
估計人體姿勢的方法
自上而下的方法
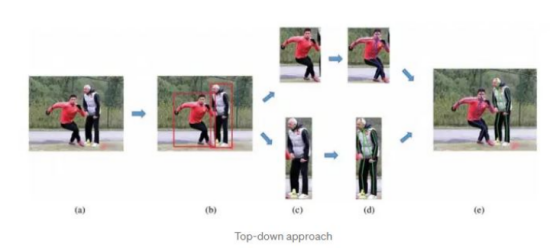
在自上而下的人體姿勢估計方法中,人工智能算法首先檢測圖像或視頻幀中的人物,然后通過分析被檢測到的人物的身體部位及其相互之間的關系來估計人物姿勢。
這種方法通常包括檢測人物的頭部、軀干和四肢,然后使用這些信息來估計人物的姿勢。它還可能涉及使用關于人物的身體比例和身體上關鍵點(例如關節)的位置的信息來改進姿勢估計。
自上而下的方法可以有效地估計圖像或視頻幀中人物的姿勢,但在處理遮擋或同一幀中的多個人物時可能不太有效。它們也可能比自下而上的方法計算更密集,自下而上的方法通過分析圖像或視頻幀的局部特征來估計人體姿態。
自下而上的方法
在一種自下而上的人體姿勢估計方法中,首先分析圖像或視頻幀中的局部特征,例如邊緣和角落,然后使用這些信息來檢測和跟蹤人物身體的各個部位,最后組合檢測到的身體部位以估計幀中單人或多人的姿勢。
自下而上的方法通常比自上而下的方法更快、更有效,因為它們不需要對人物進行初步檢測,也不需要使用關于身體比例和身體關鍵點的信息。然而,它們可能不如自上而下的方法準確,特別是在局部特征不明確或人物姿勢變化很大的情況下。
自下而上的方法對同一幀中的遮擋和多人的檢測更加有效,因為它們不依賴于人物的整體檢測。然而,他們可能很難準確地估計人物的姿勢是部分或完全遮擋。
自下而上方法的工作方式
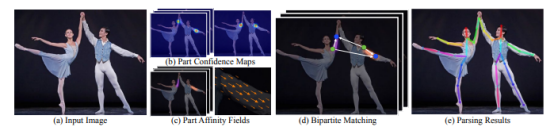
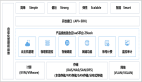
姿態估計的組件
上圖顯示了從圖像中估計一個人的姿勢所涉及的不同組件。以下詳細介紹每個組件。
組件置信度圖
人體姿態估計的第一步是檢測圖像或視頻中人體關節的位置。這通常是通過結合機器學習算法和計算機視覺技術來完成的。一種流行的方法是使用卷積神經網絡(CNN)將圖像中的像素分類為不同的身體部位。卷積神經網絡(CNN)是在一個帶注釋的圖像的大型數據集上訓練的,其中包括關于身體關節的位置和方向的信息。
部位關聯字段
部位關聯字段(PAF)是人體不同部位之間關系的表示。它用于建模人體部位之間的連接,并提供一種估計圖像或視頻幀中的人物姿勢的方法。部位關聯字段(PAF)通常表示為一個2D數組,數組中的每個元素表示人體部位連接到圖像中特定位置的可能性。部位關聯字段(PAF)通常是使用卷積神經網絡(CNN)或其他機器學習模型生成的,這些模型是在各種姿勢的帶注釋的圖像或視頻的大型數據集上訓練的。
為了生成部位關聯字段(PAF),卷積神經網絡(CNN)處理輸入圖像并生成一組特征圖,然后通過一系列卷積層和池化層來提取關于人體部位之間關系的相關信息。例如,為了估計人物手臂的姿勢,算法可能會使用部位關聯字段(PAF)根據肘關節的存在來確定肩關節的可能位置,然后使用該信息來估計手臂其余部分的姿勢。部位關聯字段(PAF)被廣泛應用于人體姿態估計,因為它們能夠捕捉身體部位之間的復雜關系,并且可以比其他方法更有效地處理遮擋和可變姿態。然而,生成它們可能需要大量的計算,并且可能需要大量的帶注釋的圖像或視頻數據集進行訓練。
雙方的匹配
用于確保同一圖像中一個人的關鍵點與另一個人的關鍵點不匹配。這是通過計算關鍵點之間的漢明距離并根據最小距離進行映射來實現的,其中流行的算法是匈牙利算法。
解析結果
該過程的最后一步是解析結果,包括顯示圖像中每個人身的圖像關鍵點。這有助于每個人的人體姿勢的可視化。
在Python中進行人體姿勢估計
谷歌發布了一個易于導入和運行的名為Mediapipe的框架,該框架支持多種編程語言。本文將展示如何使用Mediapipe訓練過的姿態估計模型。姿態估計模型經過優化,可以在輕量級設備上運行。用戶可以使用該程序輸入包含人類的圖像,并估計圖像中人類的姿勢并解釋結果。
安裝Mediapipe
pip install mediapipe讀取圖像并將圖像轉換為矩陣
Python
#Read an image
img = cv2.imread("image.jpg")將圖像從RGB轉換為BGR,以一種可以被Mediapipe接受的方式。
Python
# Run MediaPipe Pose and draw pose landmarks.
with mp_pose.Pose(static_image_mode=True, min_detection_cnotallow=0.5, model_complexity=2) as pose:
# Convert the BGR image to RGB and process it with MediaPipe Pose.
results = pose.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))將世界坐標轉換為圖像坐標。
Python
# Print nose landmark.
image_hight, image_width, _ = img.shape
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_hight})'
)類中帶有landmark變量的結果對象的坐標存儲在世界坐標中,而不是精確的圖像坐標中。上面代碼片段中的print語句顯示了轉換并打印圖像上的實際坐標。
結果可視化
Python
# Draw pose landmarks.
print(f'Pose landmarks of {name}:')
annotated_image = raw_img.copy()
mp_drawing.draw_landmarks(
annotated_image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
cv2.imshow(annotated_image)
cv2.waitKey(0)上面的代碼將有助于可視化的人物的姿態與骨架關鍵點。
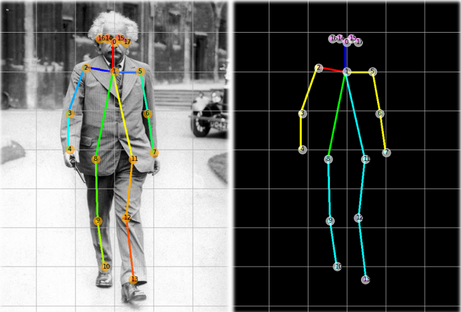
解讀結果
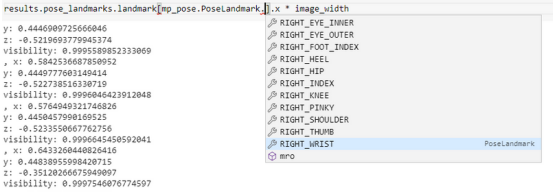
上圖顯示了人體每個點的坐標存儲位置。在業務用例中,如果可以檢索精確的坐標來重用以解決業務問題,例如使用頭部坐標來估計特定健身運動的次數或檢查手部坐標以查看游泳時劃水的角度,那么姿勢估計是有用的。
完整的代碼
Python
#Import all dependencies
#Source - https://google.github.io/mediapipe/solutions/pose.html
import cv2 #For all image processing related information
import math
import numpy as np #For matrix operations
import mediapipe as mp #Importing the library to run pose estimation
#Read an image
raw_img = cv2.imread("image.jpg")
img = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB)
# Run MediaPipe Pose and draw pose landmarks.
with mp_pose.Pose(static_image_mode=True, min_detection_cnotallow=0.5, model_complexity=2) as pose:
# Convert the BGR image to RGB and process it with MediaPipe Pose.
results = pose.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Print nose landmark.
image_hight, image_width, _ = img.shape
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_hight})'
)
# Draw pose landmarks.
print(f'Pose landmarks of {name}:')
annotated_image = raw_img.copy()
mp_drawing.draw_landmarks(
annotated_image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
cv2.imshow(annotated_image)
cv2.waitKey(0)姿態估計在國際足聯2022年世界杯中的應用

姿態估計應用比較廣泛,它被用于各種業務案例中。其中一些是在醫療保健、零售、健身和體育領域。最近舉辦的國際足聯2022年世界杯也使用了姿態估計技術,通過使用視覺傳感器和硬件傳感器來識別球員越位。
判斷越位是足球比賽中的一項規則,要求進攻球員在傳球前必須落后于對手球隊的最后兩名球員,這兩名球員通常是守門員和后衛。判罰越位的錯誤可能會發生,因為比賽進行得很快,裁判員必須離得很近才能判斷是否越位。此外,助理裁判可能無法做出準確的決定,可能導致錯誤的判罰。主裁判和助理裁判的錯誤會給輸球的球隊造成損失,這些錯誤通常涉及越位判罰和判斷進球是否準確。根據研究,裁判在大約20%~26%的越位判罰中會犯錯誤。以下深入了解國際足聯如何使用姿勢估計來識別越位。
鷹眼攝像頭

2022年世界杯在每個球場使用12個鷹眼攝像頭,并放置在球場周圍。攝像頭在現場進行校準,以識別本地坐標和全局坐標。來自攝像頭的幀也有手動標記的線條,以幫助識別足球場地上的線條。
足球傳感器

除了用于跟蹤球員在場上運動的12個攝像頭之外,傳感器通常被放置在足球內部,以幫助準確跟蹤它的位置。在足球里使用傳感器可以讓系統以很高的精度跟蹤它的運動,即使它在高速運動。
在足球上使用傳感器的一個原因是為了提高人工智能系統在場上檢測球位置的準確性。僅靠攝像頭可能不足以在任何時候準確跟蹤球的運動,特別是在足球快速移動或被場上球員或其他物體部分遮擋的情況下。通過使用傳感器,該系統可以更準確地檢測到足球的位置和運動,即使是在具有挑戰性的條件下。
傳感器還可以用來測量足球的其他特性,例如速度和旋轉速度,這對某些類型的比賽(例如任意球和點球)很重要。通過準確跟蹤這些特征,人工智能系統可以為視頻助理裁判(VAR)提供額外的信息,這些信息可能對足球比賽中的決策有用。
視頻助理裁判(VAR)
它包括一個被稱為視頻助理裁判(VAR)箱的控制室,可以訪問足球比賽的所有攝像頭視圖,以及一個視頻助理裁判(VAR)團隊,他們與場上的主裁判保持不斷的溝通。
人工智能裁判:將一切結合在一起
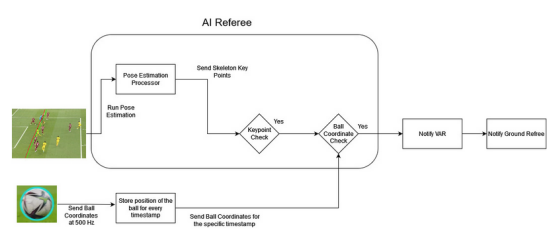
鷹眼攝像頭的每一幀都經過姿勢估計處理器進行處理,它預測幀中球員的骨架關鍵點。與此同時,用時間戳連續記錄足球的坐標。關鍵點檢查器將進攻球員(試圖進球的球員)和防守球員(試圖阻止進球的對方球員)的預測關鍵點進行比較。如果進攻球員的關鍵點比進攻和防守球員的關鍵點都更靠近球門線,就可能出現越位情況。如果關鍵點檢查器確定可能存在越位情況,它將從特定的時間戳中檢索進攻球員的坐標,并檢查是否越位。如果所有條件都滿足,并且越位情況得到確認,則決定將被發送給視頻助理裁判(VAR)團隊。視頻助理裁判(VAR)團隊可以查看錄像,并為場內裁判提供更多的信息,以幫助他們做出更明智的決定。
結論
在本文中,你學習了使用深度學習的姿態估計的概念,使用谷歌Mediapipe實現姿態估計,以及已經解決了現實問題的姿態估計的應用。
原文標題:Deep Learning-Based Pose Estimation,作者:Sumedh Datar