網易有數 BI 圖表查詢性能優化實踐

一、有數 BI 圖表的數據查詢原理
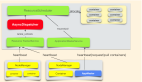
1、可視化的數據分析流程
可視化的數據分析流程,主要分成三部分:數據接入、數據建模和報告制作。

(1)數據接入
目前有數已經支持 30 多種數據源,且支持多種數據源類型,包含關系型數據庫、分布式數據庫、restAPI、數據表單等。
(2)數據建模
數據接入后,我們就可以進行數據建模。
目前我們支持通過拖拽式的 Join/Union 建模,如果用戶有復雜需求,也可以通過自定義 SQL 方式建模。另外我們也具備計算字段的能力,可以進行一些計算字段的擴展。同時,我們也支持字段元信息定義,比如字段類型、指標口徑等等。
(3)報告制作
數據模型建好了,就可以進行拖拽式的報告制作。
目前我們支持豐富的圖表庫以及強大的分析能力,讓用戶做報告就像制作 PPT 一樣簡單。同時,用戶也可以把做好的報告通過移動端、微信小程序、分享鏈接等形式分享出去,進行數據的分發和共享。
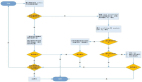
2、圖表背后的數據查詢和處理技術

(1)Query DSL:圖表數據查詢語言
首先圖表配置好以后會先生成 Query DSL(圖表數據查詢語言),它包含模型依賴的數據源連接信息、寬表信息以及用戶拖上去的維度、度量、篩選、排序等等。
(2)所有操作都可以轉換成 Query DSL
用戶配置的圖表最終都能轉換成一套 Query DSL。
(3)抽象語法樹的生成
有了 Query DSL,就可以生成對應的 AST(抽象語法樹),它包含 Table 節點、Select 節點、From 節點、Group By 節點和一些計算節點等。
(4)SQL 語法適配:屏蔽數據源差異
有了抽象語法樹,我們就可以針對不同的數據源進行 SQL 的適配,然后從不同的數據源將數據查詢回來并返回給用戶。這樣,對于用戶來說是不需要感知到底層數據源的類型的。
3、圖表查詢核心能力

首先,最基礎的部分,支持排序、篩選、聚合、數據字典、計算字段和分組字段等等。
另外,支持圖表聯動、上卷下鉆、地圖計算等強大的分析能力。
同時,還支持行列權限(同一個圖表不同用戶看到不同數據)以及跨視圖粒度分析(同一張圖表可以看到不同聚合粒度的數據)的能力。
最后總結下,前面講到的圖表提供的一些能力,背后的核心其實都是對數據字段行為的處理,比如我們常用的聚焦下鉆,當點擊地區 = “東北”這個柱子下鉆下去看下東北下面各個省份求和銷售額的分布,其實背后的處理行為就是,我們會把 x 軸的維度字段從地區轉換為省份,然后再加一個地區 = “東北”的字段篩選器,所以這里聚焦下鉆其實背后被轉換成了兩個對字段行為的處理,最后這些字段都會轉換成統一的語法樹。

二、有數 BI 智能緩存的設計和實現
前面我們講到,針對用戶配置的圖表會對應生成 SQL,然后去對應的落庫查詢。整個查詢過程有以下幾個特點:
① 高并發:早上看數高峰期。
② 大數據量:很多千萬、億級數據查詢場景。
③ 離線數據:大部分都是 T + 1 的數據。
針對以上特點最有效的手段就是通過緩存去解決,可以看到下圖是我們線上最近一個月的查詢耗時對比(綠色線表示落庫查詢、紅色線表示緩存查詢),很明顯命中緩存以后查詢效率可以有上百倍的提升。

那么,圖表緩存的是什么數據呢?
答案是圖表數據。
這里可能很多同學會問,為什么不緩存模型數據?
首先,模型數據可能較大;其次,當緩存模型數據時,圖表查詢時依然需要進行二次聚合運算,因此也存在一定的計算成本。

可以看到我們緩存的對象由圖表和用戶組成,這里的主要原因是由于前面講到的同一圖表不同用戶可以看到不同數據,因此一個圖表會存在多份緩存。
除此之外,我們還引入了二級緩存的概念。
一級緩存,主要緩存前端圖表通過 queryData 查詢出來的數據。
二級緩存,主要緩存生成的 SQL 查詢出來的數據,同時,二級緩存可以實現緩存復用,例如:同一套數據展示成折線圖和柱狀圖,雖然他們的展示形式不同,但底層生成的 SQL 是一樣的,此時就可以復用二級緩存。
下圖展示了智能緩存的整體架構。

第一層是調度器:包括緩存的刷新計劃、OpenAPI、表產出訂閱、MPP 抽取和手動觸發。
第二層是運算器:包括數據產出驅動、圖表血緣計算、用戶查詢行為分析和基于 ROI 的優先級計算。
第三層是執行器:通過運算器會生產一個緩存對象,緩存對象就會被放入隊列進行排隊執行,最終生成緩存的數據。
另外,我們我們還會實時地監控緩存數據,進行一些緩存的監控和報警。
接下來,我們看一下緩存運算器中的基于數據產出驅動緩存的原理。

因為大部分數據是 T+1 離線數據,因此這里也是以天為單位進行實現。它的輸入是離線表的產出消息,當消息推送過來時,我們可以根據圖表的血緣關系找到該表關聯的圖表,然后對圖表進行緩存。
當然,有些表不是每天都有產出任務的,因此這里我們引入了產出預測模塊。它可以根據數據任務的調度信息計算出某個表今天有沒有產出,另外還可以根據表產出歷史推測出今天該表有沒有產出。
該方式的優點是可以提升緩存效率,進行錯峰緩存,從而保障緩存的實時性和有效性。
它的應用場景有三點:
① 一是與有數數據中臺的數據服務打通,天然就具備了這個能力。
② 二是內置 MPP 抽取完進行數據驅動,例如物化視圖完或數據抽取完以后可以實時觸發緩存。
③ 三是用戶可以通過調用 API 的方式,主動觸發緩存。
下面介紹緩存運算器的原理。

這里主要講四點:
第一點是用戶行為分析:用戶在打開報告后,會默認進行一些篩選,然后用戶可以進行篩選器切換、圖表聯動、圖表跳轉等行為,此時隨著圖表的變換,緩存數據也會隨之變動。因此,用戶行為分析是希望從中找出規律,提高用戶行為分析時的緩存命中率。
第二點是 QueryData:QueryData 是圖表的查詢請求輸入,它主要分為兩類,一類是圖表默認的 QueryData;另一類是根據圖表歷史分析行為采集器生成的 QueryData,它可能有很多份,我們會選取 TopN 進行緩存。
第三點是權限判斷:因為用戶權限每天可能發生變化,因此我們會結合用戶的資源權限和數據權限,最終選取 TopN 的用戶進行緩存。
第四點是優先級計算:可以看到我們這里是根據 ROI 算法進行緩存的優先級判斷的,計算因子包括 PV、UV、產出頻率等等,最終計算出每一個用戶和 queryData 的優先級。
除此之外,我們可以計算出:緩存總數量 = 用戶數量 * queryData 數量。
下面是我們在云音樂環境下緩存實踐效果統計:
① 首次緩存命中率從 35% 提高到 93%+。
② 整體緩存命中率從 70% 提高到 92%+。
③ 5 秒內頁面響應占比從 70% 提高到 90%+。

下面是用戶行為分析緩存的統計,可看到用戶行為分析緩存命中率從 35% 提高到 80%+,效果比較明顯。

三、圖表查詢的合并和優化
下圖是一個報告的示例,可以看到該報告可能包含上百個圖表,且每個圖表都會產生一到多個 SQL 查詢,而整體并發 SQL 查詢越多,整體查詢也就越慢。通過對比 SQL 分析,可以發現大部分 SQL 只是 select 字段不一樣,where 和 group by 等條件可能都一樣,那么對于這種查詢就可以進行查詢合并。

圖表查詢的合并和優化是通過查詢視圖的構建來實現的。
首先我們以報告為粒度進行查詢視圖的構建,一份報告對應多個查詢視圖,一個查詢視圖可以承載多個圖表的查詢,查詢視圖的聚合規則包含:Filter、Dimensions、Sorters 等。
假設一個報告內 Query DSL 有 N 個,Query DSL View 有 M 個,那么 N/M 越大,查詢視圖的價值就越大。

接下來我們介紹一下查詢視圖的查詢流程優化:
首先,前端輸入一個 Query Data,我們會找到對應的原始的 Query DSL,然后生成對應的查詢視圖,然后進行重組生成一個新的 Query DSL,新的 Query DSL 返回數據的時候,也會對查詢結果進行反向還原。
然后 Query DSL 會經過緩存模塊進行處理,這里有一個好處就是,多個相似圖表的緩存可以進行復用,從而減少緩存數據大小和預緩存次數。
如果沒有命中緩存,請求會經過我們的查詢攔截器,攔截器可以保證同一個查詢視圖的請求只會下發一次。
以上的整個過程對前端來說是透明的,前端無需感知整個查詢過程。

下面是圖表查詢合并后的實踐效果:
其中 13000 多個查詢視圖可以承載 84000 多個查詢,也就是 N/M≈1:7。
其中每日落庫查詢量從 7000 次下降到 3000 次左右,效果比較明顯。

四、圖表查詢的其他優化
1、維值加速
下圖是一家客戶的查詢報告,可以看到其中篩選器數量非常多,并且是根據明細數據進行去重聚合的,其查詢也相對頻繁,查詢出來的成員較少且是固定的,此時我們可以通過維值加速進行優化。

我們可以通過以下幾種方式進行維值加速:
動態值:可以把被查詢的字段綁定到單獨的維表字段上,最終查詢篩選器數據時實際上查的是對應維表的數據。
靜態值:對于靜態值,可以直接對查詢字段設置枚舉,例如:性別的男、女等。
總體思路是減少對于明細表高頻且耗時的聚合查詢。
2、分區篩選器優化
因為大部分數據源都具備分區概念,如果能命中分區索引,就可以減少全表掃描,從而提升查詢速度。
這里的分區查詢篩選器優化,是結合了有數數據中臺元數據中心,去獲取對應表的分區字段,從而生成分區篩選器。當圖表在查詢的時候,我們會動態的獲取分區篩選器的最近分區,同時會進行分區篩選的強制下推,從而提升查詢性能。

分區篩選器有以下兩個特點:
第一是由建模人員決定是否使用分區篩選器,這樣可以規范分析師的使用流程。
第二是報告必須繼承模型分區篩選器,同時不能進行刪除。

3、查詢分級優化
查詢分級優化主要從四個方面介紹:
(1)查詢分流
針對不同場景使用不同查詢引擎,比如使用 Impala 數據源時支持使用 Spark 進行抽取和導出 Excel 相關查詢。
(2)高低優先級查詢隊列
控制同一個數據源的并發 SQL。
優先保障重點用戶(例如老板等)的看數需求等。
(3)重點報告/普通報告
重點報告優先緩存。
重點報告支持單獨切換數據連接,比如 Impala 數據源可以走不同的分組。
(4)VIP 查詢服務
部分報告的查詢走單獨的后端服務;
資源隔離,保障可用性。

4、前端渲染優化
主要包括以下三個方面:
① 查詢組件分級:例如圖表及 topN 篩選器可以進行高優先級加載,圖片和普通篩選器做低優先級加載。
② 局部渲染優化:優先渲染視窗內的組件,非可視區域進行懶加載。
③ 請求隊列控制:前端做了請求隊列的控制,減少查詢并發,從而避免一個用戶就把數據源資源吃光。

5、SQL 生成優化
第五個就是我們會對第一章的講到的 Query DSL 去生成 SQL 這個過程也做了一些通用的優化,比如篩選條件等價下推,Join 條件篩選傳遞,動態模型剪枝等優化。這些優化都會對特定場景的查詢有較大的優化效果,右邊這個圖是我們字段類型轉換做篩選的優化效果圖,雖然該字段做了類型轉換,其實我們也可以背后讓他用原始的類型進行篩選,提高查詢效率。

6、MPP 查詢加速
對于一些異構數據源,我們可以通過數據抽取、數據準備、物化視圖等方式,將數據抽取到 MPP 數倉,達到查詢加速的目的。

五、圖表的性能查詢分析和診斷
前面我們介紹了很多圖表查詢性能優化的方式和方法,但是并不能解決所有的性能問題,新的性能問題總是會不斷的產生。同時,有數 BI 的圖表查詢鏈路也較長,性能排查過程耗時耗力。雖然我們提供了很多圖表性能的優化手段,分析師具體該如何選擇也是問題。
我們做性能分析和診斷的目標是:
① 幫助用戶快速定位問題。
② 輸出準確的方案。
③ 直接賦能用戶自我解決問題。
這個功能在我們產品功能上叫做“數據醫生”,下面是我們數據醫生實現的方案:
① 第一步是根據性能統計,發現到底是哪個圖表慢。
② 第二步是找到某個具體圖表以后我們可以進行全鏈路 timeline 計算和分析。
③ 第三步結合我們診斷的規則庫,推斷具體問題原因。
④ 第四步針對不同的問題,給出不同的解決方案。

另外我們還專門做了一層統一的針對 SQL profile 的性能解析層,會把不同數據源的 profile 進行統一的抽象,比如統計 SQL 的資源消耗,分區、存儲格式等表的元信息,另外會對 Join 或者 Scan 算子的性能進行定義和解析,目前我們已經適配了 Impala 和 Clickhouse 兩種數據源,右邊是我們針對這個抽象的 SQL 粒度的性能解析在產品上的診斷結果的體現,我們會告知用戶哪些表的掃描數據比較慢,哪些 Join 節點的計算比較慢,這樣用戶就很方便的發現具體的問題。

數據醫生自助幫助用戶解決了基本的性能問題,釋放了技術支持和開發的人力。同時我們的診斷規則和經驗也在不斷持續積累。

六、總結
最后來做一個簡單的總結。
(1)性能是 BI 產品的有理保障和核心競爭力,性能是保障用戶體驗的根基。
(2)解決性能問題一定要從用戶使用場景出發,具體問題具體分析。
(3)提效和易用:盡可能地賦能用戶自助解決問題的能力,提升產品效率和易用性。

七、問答環節
Q1:緩存是行列級別的嗎?
A1:我們的緩存是緩存一份圖表的數據,所以一個圖表看能有多份緩存,不同用戶不同權限看到圖表數據可能不一樣,同時我們也會對相同權限的用戶進行去重和合并。
Q2:MPP 查詢負載打滿后怎么處理?
A2:MPP 這邊我們有專人進行維護,會對 MPP 數據庫的查詢進行監控和告警,同時我們也會對 MPP 進行一些治理,例如:發現一些大查詢我們會進行攔截等。
Q3:查詢合并只針對指標卡嗎?還是所有圖表類型都會進行合并?
A3:查詢合并目前最主要還是指標卡的應用場景,其他場景我們后面也會慢慢支持。
Q4:請問數據存儲最終是存儲到 MPP 里面的嗎?還是說支持外部?
A4:對于有數 BI 來說,我們的圖表查詢是落到 MPP 數倉里面。對于外部數倉來說,我們支持 ETL 數據準備能力,進行一個數據清洗,可以把我們的數據準備清洗到外部數據庫,目前 ETL 外部數據庫已經支持 MySQL、Doris 等,然后用戶可以通過建立數據連接在有數 BI 上進行查詢和分析。
Q5:目前的性能診斷的數據醫生,對于優化性能最大的是哪種手段?
A5:對于數據醫生來說,只是診斷工具,并不是用來提升性能的。具體性能的提升,還是要通過物化視圖、維值加速、分區篩選等手段進行,物化視圖目前的性能提升相對較大。
Q6:查詢視圖與物化視圖如何區分與使用?
A6:查詢視圖其實是物化視圖前面的部分,為了構建 Query DSL 的輸入,請求的鏈路到達查詢器,才會命中后面的物化視圖。