RLHF中的「RL」是必需的嗎?有人用二進制交叉熵直接微調(diào)LLM,效果更好
近來,在大型數(shù)據(jù)集上訓練的無監(jiān)督語言模型已經(jīng)獲得了令人驚訝的能力。然而,這些模型是在具有各種目標、優(yōu)先事項和技能集的人類生成的數(shù)據(jù)上訓練的,其中一些目標和技能設定未必希望被模仿。
從模型非常廣泛的知識和能力中選擇其期望的響應和行為,對于構建安全、高性能和可控的人工智能系統(tǒng)至關重要。很多現(xiàn)有的方法通過使用精心策劃的人類偏好集將所需的行為灌輸?shù)秸Z言模型中,這些偏好集代表了人類認為安全和有益的行為類型,這個偏好學習階段發(fā)生在對大型文本數(shù)據(jù)集進行大規(guī)模無監(jiān)督預訓練的初始階段之后。
雖然最直接的偏好學習方法是對人類展示的高質(zhì)量響應進行監(jiān)督性微調(diào),但最近相對熱門的一類方法是從人類(或人工智能)反饋中進行強化學習(RLHF/RLAIF)。RLHF 方法將獎勵模型與人類偏好的數(shù)據(jù)集相匹配,然后使用 RL 來優(yōu)化語言模型策略,以產(chǎn)生分配高獎勵的響應,而不過度偏離原始模型。
雖然 RLHF 產(chǎn)生的模型具有令人印象深刻的對話和編碼能力,但 RLHF pipeline 比監(jiān)督學習復雜得多,涉及訓練多個語言模型,并在訓練的循環(huán)中從語言模型策略中采樣,產(chǎn)生大量的計算成本。
而最近的一項研究表明:現(xiàn)有方法使用的基于 RL 的目標可以用一個簡單的二進制交叉熵目標來精確優(yōu)化,從而大大簡化偏好學習 pipeline。也就是說,完全可以直接優(yōu)化語言模型以堅持人類的偏好,而不需要明確的獎勵模型或強化學習。

論文鏈接:https://arxiv.org/pdf/2305.18290.pdf
來自斯坦福大學等機構研究者提出了直接偏好優(yōu)化(Direct Preference Optimization,DPO),這種算法隱含地優(yōu)化了與現(xiàn)有 RLHF 算法相同的目標(帶有 KL - 發(fā)散約束的獎勵最大化),但實施起來很簡單,而且可直接訓練。
實驗表明,至少當用于 60 億參數(shù)語言模型的偏好學習任務,如情感調(diào)節(jié)、摘要和對話時,DPO 至少與現(xiàn)有的方法一樣有效,包括基于 PPO 的 RLHF。
DPO 算法
與現(xiàn)有的算法一樣,DPO 也依賴于理論上的偏好模型(如 Bradley-Terry 模型),以此衡量給定的獎勵函數(shù)與經(jīng)驗偏好數(shù)據(jù)的吻合程度。然而,現(xiàn)有的方法使用偏好模型定義偏好損失來訓練獎勵模型,然后訓練優(yōu)化所學獎勵模型的策略,而 DPO 使用變量的變化來直接定義偏好損失作為策略的一個函數(shù)。鑒于人類對模型響應的偏好數(shù)據(jù)集,DPO 因此可以使用一個簡單的二進制交叉熵目標來優(yōu)化策略,而不需要明確地學習獎勵函數(shù)或在訓練期間從策略中采樣。
DPO 的更新增加了首選 response 與非首選 response 的相對對數(shù)概率,但它包含了一個動態(tài)的、每個樣本的重要性權重,以防止模型退化,研究者發(fā)現(xiàn)這種退化會發(fā)生在一個樸素概率比目標上。
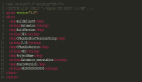
為了從機制上理解 DPO,分析損失函數(shù) 的梯度是很有用的。關于參數(shù) θ 的梯度可以寫成:
的梯度是很有用的。關于參數(shù) θ 的梯度可以寫成:

其中 是由語言模型
是由語言模型 和參考模型
和參考模型 隱含定義的獎勵。直觀地說,損失函數(shù)
隱含定義的獎勵。直觀地說,損失函數(shù) 的梯度增加了首選補全 y_w 的可能性,減少了非首選補全 y_l 的可能性。
的梯度增加了首選補全 y_w 的可能性,減少了非首選補全 y_l 的可能性。
重要的是,這些樣本的權重是由隱性獎勵模型 對不喜歡的完成度的評價高低來決定的,以 β 為尺度,即隱性獎勵模型對完成度的排序有多不正確,這也是 KL 約束強度的體現(xiàn)。實驗表明了這種加權的重要性,因為沒有加權系數(shù)的這種方法的 naive 版本會導致語言模型的退化(附錄表 2)。
對不喜歡的完成度的評價高低來決定的,以 β 為尺度,即隱性獎勵模型對完成度的排序有多不正確,這也是 KL 約束強度的體現(xiàn)。實驗表明了這種加權的重要性,因為沒有加權系數(shù)的這種方法的 naive 版本會導致語言模型的退化(附錄表 2)。
在論文的第五章,研究者對 DPO 方法做了進一步的解釋,提供了理論支持,并將 DPO 的優(yōu)勢與用于 RLHF 的 Actor-Critic 算法(如 PPO)的問題聯(lián)系起來。具體細節(jié)可參考原論文。
實驗
在實驗中,研究者評估了 DPO 直接根據(jù)偏好訓練策略的能力。
首先,在一個控制良好的文本生成環(huán)境中,他們思考了這樣一個問題:與 PPO 等常見偏好學習算法相比,DPO 在參考策略中權衡獎勵最大化和 KL-divergence 最小化的效率如何?接著,研究者還評估了 DPO 在更大模型和更困難的 RLHF 任務 (包括摘要和對話) 上的性能。
最終發(fā)現(xiàn),在幾乎沒有超參數(shù)調(diào)整的情況下,DPO 的表現(xiàn)往往與帶有 PPO 的 RLHF 等強大的基線一樣好,甚至更好,同時在學習獎勵函數(shù)下返回最佳的 N 個采樣軌跡結果。
從任務上說,研究者探索了三個不同的開放式文本生成任務。在所有實驗中,算法從偏好數(shù)據(jù)集 中學習策略。
中學習策略。
在可控情感生成中,x 是來自 IMDb 數(shù)據(jù)集的電影評論的前綴,策略必須生成具有積極情感的 y。為了進行對照評估,實驗使用了預先訓練好的情感分類器去生成偏好對,其中 。
。
對于 SFT,研究者微調(diào)了 GPT-2-large,直到收斂于 IMDB 數(shù)據(jù)集的訓練分割的評論。總之,x 是來自 Reddit 的論壇帖子,該策略必須生成帖子中要點的總結。基于此前工作,實驗使用了 Reddit TL;DR 摘要數(shù)據(jù)集以及 Stiennon et al. 收集的人類偏好。實驗還使用了一個 SFT 模型,該模型是根據(jù)人類撰寫的論壇文章摘要 2 和 RLHF 的 TRLX 框架進行微調(diào)的。人類偏好數(shù)據(jù)集是由 Stiennon et al. 從一個不同的但經(jīng)過類似訓練的 SFT 模型中收集的樣本。
最后,在單輪對話中,x 是一個人類問題,可以是從天體物理到建立關系建議的任何問題。一個策略必須對用戶的查詢做出有吸引力和有幫助的響應;策略必須對用戶的查詢做出有意思且有幫助的響應;實驗使用 Anthropic Helpful and Harmless 對話集,其中包含人類和自動化助手之間的 170k 對話。每個文本以一對由大型語言模型 (盡管未知) 生成的響應以及表示人類首選響應的偏好標簽結束。在這種情況下,沒有預訓練的 SFT 模型可用。因此,實驗只在首選完成項上微調(diào)現(xiàn)成的語言模型,以形成 SFT 模型。
研究者使用了兩種評估方法。為了分析每種算法在優(yōu)化約束獎勵最大化目標方面的效率,在可控情感生成環(huán)境中,實驗通過其實現(xiàn)獎勵的邊界和與參考策略的 KL-divergence 來評估每種算法。實驗可以使用 ground-truth 獎勵函數(shù) (情感分類器),因此這一邊界是可以計算得出的。但事實上,ground truth 獎勵函數(shù)是未知的。因此研究者通過基線策略的勝率評估算法的勝率,并用 GPT-4 作為在摘要和單輪對話設置中人類評估摘要質(zhì)量和響應有用性的代理。針對摘要,實驗使用測試機中的參考摘要作為極限;針對對話,選用測試數(shù)據(jù)集中的首選響應作為基線。雖然現(xiàn)有研究表明語言模型可以成為比現(xiàn)有度量更好的自動評估器,但研究者進行了一項人類研究,證明了使用 GPT-4 進行評估的可行性 GPT-4 判斷與人類有很強的相關性,人類與 GPT-4 的一致性通常類似或高于人類標注者之間的一致性。

除了 DPO 之外,研究者還評估了幾種現(xiàn)有的訓練語言模型來與人類偏好保持一致。最簡單的是,實驗在摘要任務中探索了 GPT-J 的零樣本 prompt,在對話任務中探索了 Pythia-2.8B 的 2-shot prompt。此外,實驗還評估了 SFT 模型和 Preferred-FT。Preferred-FT 是一個通過監(jiān)督學習從 SFT 模型 (可控情感和摘要) 或通用語言模型 (單回合對話) 中選擇的完成 y_w 進行微調(diào)的模型。另一種偽監(jiān)督方法是 Unlikelihood,它簡單地優(yōu)化策略,使分配給 y_w 的概率最大化,分配給 y_l 的概率最小化。實驗在「Unlikehood」上使用了一個可選系數(shù) α∈[0,1]。他們還考慮了 PPO,使用從偏好數(shù)據(jù)中學習的獎勵函數(shù),以及 PPO-GT。PPO-GT 是從可控情感設置中可用的 ground truth 獎勵函數(shù)學習的 oracle。在情感實驗中,團隊使用了 PPO-GT 的兩個實現(xiàn),一個是現(xiàn)成的版本,以及一個修改版本。后者將獎勵歸一化,并進一步調(diào)整超參數(shù)以提高性能 (在運行具有學習獎勵的「Normal」PPO 時,實驗也使用了這些修改)。最后,研究者考慮了 N 個基線中的最優(yōu)值,從 SFT 模型 (或?qū)υ捴械?Preferred-FT) 中采樣 N 個回答,并根據(jù)從偏好數(shù)據(jù)集中學習的獎勵函數(shù)返回得分最高的回答。這種高性能方法將獎勵模型的質(zhì)量與 PPO 優(yōu)化解耦,但即使對中度 N 來說,在計算上也是不切實際的,因為它在測試時需要對每個查詢進行 N 次采樣完成。
圖 2 展示了情緒設置中各種算法的獎勵 KL 邊界。

圖 3 展示了 DPO 收斂到其最佳性能的速度相對較快。

更多研究細節(jié),可參考原論文。