Pandas圖鑒之一:Pandas vs Numpy
 圖片
圖片
Pandas[1]是用Python分析數(shù)據(jù)的工業(yè)標準。只需敲幾下鍵盤,就可以加載、過濾、重組和可視化數(shù)千兆字節(jié)的異質信息。它建立在NumPy庫的基礎上,借用了它的許多概念和語法約定,所以如果你對NumPy很熟悉,你會發(fā)現(xiàn)Pandas是一個相當熟悉的工具。即使你從未聽說過NumPy,Pandas也可以讓你在幾乎沒有編程背景的情況下輕松拿捏數(shù)據(jù)分析問題。
Pandas 給 NumPy 數(shù)組帶來的兩個關鍵特性是:
異質類型 —— 每一列都允許有自己的類型
索引 —— 提高指定列的查詢速度
事實證明,這些功能足以使Pandas成為Excel和數(shù)據(jù)庫的強大競爭者。
Polars[2]是Pandas最近的轉世(用Rust編寫,因此速度更快,它不再使用NumPy的引擎,但語法卻非常相似,所以學習 Pandas 后對學習 Polars 幫助非常大。
Pandas 圖鑒系列文章由四個部分組成:
Part 1. Motivation
Part 2. Series and Index
Part 3. DataFrames
Part 4. MultiIndex
我們將拆分成四個部分,依次呈現(xiàn)~建議關注和星標@公眾號:數(shù)據(jù)STUDIO,精彩內容等你來~
假設你有一個文件,里面有一百萬行逗號分隔的數(shù)值,像這樣:
 圖片
圖片
冒號后的空格僅用于說明問題。通常情況下,沒有空格。
而你需要用NumPy對 "哪些城市的面積超過450平方公里,人口低于1000萬" 這樣的基本問題給出答案。
通常情況下,不推薦使用將整個表送入NumPy數(shù)組的粗暴解決方案。NumPy數(shù)組是同質類型的(=所有的值都有相同的類型),所以所有的字段都會被解譯為字符串,在比大小方面也不盡人意。
雖然NumPy也有結構化數(shù)組和記錄數(shù)組,允許不同類型的列,但它們主要是為了與C代碼對接。當用于一般用途時,它們有以下缺點:
不太直觀(例如,你將面臨到處都是<f8和<U8這樣的常數(shù));
與普通的NumPy數(shù)組相比,有一些性能問題;
在內存中連續(xù)存儲,所以每增加或刪除一列都需要對整個數(shù)組進行重新分配;
仍然缺乏Pandas DataFrames的很多功能。
如果將每一列存儲為一個單獨的NumPy向量。之后可以把它們包成一個dict,這樣,如果以后需要增加或刪除一兩行,就可以更容易恢復 "數(shù)據(jù)庫" 的完整性。下面是它的樣子:
 圖片
圖片
至此我們已經(jīng)邁出了重新實現(xiàn)Pandas的第一步。
現(xiàn)在,下面有幾個例子來說明Pandas可以做一些NumPy不能做的事情(或者需要付出巨大努力才能完成)。
如下表所示:
 圖片
圖片
它描述了一個網(wǎng)上商店的多樣化產品線,總共有四種不同的產品。與前面的例子相比,它既可以用NumPy數(shù)組表示,也可以用Pandas DataFrame表示,效果同樣不錯。但來看看它的一些常見操作。
用Pandas按列排序更有可讀性,你可以看到如下:
 圖片
圖片
這里argsort(a[:,1])計算了使a的第二列以升序排序的排列方式,然后外部的a[...]相應地重新排列a的行。Pandas可以在一個步驟中完成。
如果我們需要使用權重列按價格列打破平局進行排序,那么對于NumPy來說卻有些糟糕:
 圖片
圖片
如果選擇使用NumPy,我們首先按重量排序,然后再按價格應用第二次排序。一個穩(wěn)定的排序算法可以保證第一次排序的結果在第二次排序時不會丟失。用NumPy還有其他方法,但都不如用Pandas簡單和優(yōu)雅。
從語法和架構上來說,用Pandas添加列要好得多:
 圖片
圖片
Pandas不需要像NumPy那樣為整個數(shù)組重新分配內存;它只是為新的列添加一個引用,并更新一個列名的 registry。
對于NumPy數(shù)組,即使搜索的元素是第一個,仍然需要與數(shù)組大小成比例的時間來找到它。使用Pandas,可以對我們預期最常被查詢的列進行索引,并將搜索時間減少到On。
 圖片
圖片
索引欄有以下限制:
它需要記憶和時間來建立。
它是只讀的(在每次追加或刪除操作后需要重新建立)。
這些值不需要是唯一的,但只有當元素是唯一的時候才會發(fā)生加速。
它需要熱身:第一次查詢比NumPy慢一些,但隨后的查詢就明顯快了。
5.按列連接
如果想用另一個表的信息來補充一個基于共同列的表,NumPy幾乎沒有用。而Pandas更好,特別是對于1:n的關系。
 圖片
圖片
Pandas連接有所有熟悉的 inner, left, right, 和 full outer 連接模式。
6.按列分組
數(shù)據(jù)分析中另一個常見的操作是按列分組。例如,為了獲得每種產品的總銷售量,可以做如下操作:
 圖片
圖片
除了sum,Pandas還支持各種聚合函數(shù):mean, max,min, count等等。
7.透視表
Pandas最強大的功能之一是 pivot 表。它類似于將多維空間投射到一個二維平面。
 圖片
圖片
雖然用NumPy當然可以實現(xiàn)。而Pandas也有df.pivot_table,它將分組和透視結合在一個工具中。
說到這里,你可能會想,既然Pandas這么好,為什么還會有人使用NumPy呢?NumPy沒有好壞之分,它只是有不同的使用情況:
- 隨機數(shù)(例如,用于測試)
- 線性代數(shù)(例如,用于神經(jīng)網(wǎng)絡)。
- 圖像和圖像堆疊(例如,用于CNN)。
- 微分、積分、三角學和其他科學人員。
簡而言之,NumPy和Pandas的兩個主要區(qū)別如下:
 圖片
圖片
現(xiàn)在看看這些功能是否以性能的降低為代價。
Pandas的速度
下面對NumPy和Pandas的典型工作負載進行了基準測試:5-100列;103-10?行;整數(shù)和浮點數(shù)。下面是1行和1億行的結果:
 圖片
圖片
從測試結果來看,似乎在每一個操作中,Pandas都比NumPy慢!而這并不意味著Pandas的速度比NumPy慢!
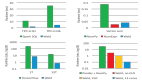
當列的數(shù)量增加時,沒有什么變化。而對于行的數(shù)量,二者的對比關系(在對數(shù)尺度上)如下圖所示:
 圖片
圖片
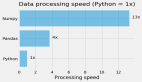
對于小數(shù)組(百行以下),Pandas似乎比NumPy慢30倍,對于大數(shù)組(百萬行以上)則慢3倍。
怎么可能呢?我們提交一個功能請求,建議Pandas通過df.column.values.sum()重新實現(xiàn)df.column.sum()了?這里的values屬性提供了對底層NumPy數(shù)組的訪問,并帶來了3-30倍的速度提升。
答案是否定的。Pandas 在這些基本操作上是如此緩慢,因為它正確地處理了缺失值。在Pandas中,做了大量的工作來統(tǒng)一NaN在所有支持的數(shù)據(jù)類型中的用法。根據(jù)定義(在CPU層面上強制執(zhí)行),nan+任何東西的結果都是nan。
所以在numpy中計算求和時:
>>> np.sum([1, np.nan, 2])
nan但使用pandas計算求和時:
>>> pd.Series([1, np.nan, 2]).sum()
3.0一個公平的比較是用np.nansum代替np.sum,np.nanmean代替np.mean,等等。突然間...
 圖片
圖片
對于超過一百萬元素的數(shù)組,Pandas變得比NumPy快1.5倍。對于較小的數(shù)組,它仍然比NumPy慢15倍,但通常情況下,操作在0.5毫秒或0.05毫秒內完成并不重要--反正是快了。
如果你100%確定你的列中沒有缺失值,那么使用df.column.values.sum()而不是df.column.sum()來獲得x3-x30的性能提升是有意義的。在存在缺失值的情況下,Pandas的速度是相當不錯的,對于巨大的數(shù)組(超過10?個元素)來說,甚至比NumPy還要好。
我們將連載個后續(xù)部分,敬請期待~
參考資料
[1]Pandas: https://pandas.pydata.org/
[2]Polars: https://www.pola.rs/