vivo 帳號(hào)服務(wù)穩(wěn)定性建設(shè)之路-平臺(tái)產(chǎn)品系列06

一、前言
vivo帳號(hào)是用戶(hù)暢享整個(gè)vivo生態(tài)服務(wù)的必備通行證,也是生態(tài)內(nèi)各業(yè)務(wù)開(kāi)展的基石。伴隨公司業(yè)務(wù)快速增長(zhǎng),帳號(hào)系統(tǒng)目前服務(wù)的在網(wǎng)用戶(hù)已達(dá)到2.7億,日均調(diào)用量破百億,作為一個(gè)典型的三高(高性能、高并發(fā)、高可用)屬性的系統(tǒng),帳號(hào)系統(tǒng)的穩(wěn)定性顯得尤為重要。而要保障系統(tǒng)的穩(wěn)定性,我們需要綜合考慮多方面因素。本文將從應(yīng)用服務(wù)、數(shù)據(jù)架構(gòu)、監(jiān)控三個(gè)維度出發(fā),分享帳號(hào)服務(wù)端在穩(wěn)定性建設(shè)方面的經(jīng)驗(yàn)總結(jié)。
二、應(yīng)用服務(wù)治理
《架構(gòu)整潔之道》書(shū)中將軟件的價(jià)值總結(jié)為“行為”、“架構(gòu)”兩個(gè)維度。
行為價(jià)值:讓機(jī)器按照某種指定方式運(yùn)轉(zhuǎn),給系統(tǒng)的使用者創(chuàng)造或提高利潤(rùn)。
架構(gòu)價(jià)值:始終保持軟件的靈活性,以便讓我們可以靈活地改變機(jī)器的工作行為。
行為價(jià)值描述的是當(dāng)下,對(duì)于用戶(hù)最直觀的感受就是易用性、功能豐富程度等。好的行為價(jià)值能夠吸引用戶(hù),進(jìn)而對(duì)服務(wù)提供者能有一個(gè)正向回報(bào)。
架構(gòu)價(jià)值描述的是未來(lái),指服務(wù)系統(tǒng)的內(nèi)在結(jié)構(gòu)、技術(shù)體系、穩(wěn)定性等,這些價(jià)值雖然對(duì)用戶(hù)是不可見(jiàn)的,但它決定了服務(wù)的延續(xù)性。
應(yīng)用服務(wù)的治理目的是讓系統(tǒng)保持“架構(gòu)價(jià)值”,進(jìn)而延續(xù)“行為價(jià)值”,我們?cè)凇胺?wù)治理”章節(jié)將重點(diǎn)介紹兩點(diǎn)內(nèi)容:“服務(wù)拆分”、“關(guān)系治理”。
2.1 服務(wù)拆分
服務(wù)拆分是指將一個(gè)服務(wù)拆分為多個(gè)小型、相對(duì)獨(dú)立的微服務(wù)。服務(wù)拆分有非常多的收益,包括提高系統(tǒng)的可擴(kuò)展性、可維護(hù)性、穩(wěn)定性等等。下面將介紹我們?cè)谙到y(tǒng)建設(shè)過(guò)程中遇到的拆分場(chǎng)景。
2.1.1 基于組織架構(gòu)調(diào)整拆分
康威定律 ( Conway's Law) 由馬爾文·康威于1967年提出:"設(shè)計(jì)系統(tǒng)的架構(gòu)受制于產(chǎn)生這些設(shè)計(jì)的組織的溝通結(jié)構(gòu)。"。即系統(tǒng)設(shè)計(jì)本質(zhì)上反映了企業(yè)的組織結(jié)構(gòu),系統(tǒng)各個(gè)模塊間的關(guān)系也反映了企業(yè)各個(gè)部門(mén)之間的信息流動(dòng)和合作方式,內(nèi)容示意如下圖(圖1):

圖1 (圖片來(lái)源:WORK LIFE)
組織架構(gòu)調(diào)整是企業(yè)發(fā)展過(guò)程中常常需要面對(duì)的重要挑戰(zhàn),其原因通常與市場(chǎng)需求、業(yè)務(wù)變化、協(xié)同效率相關(guān)。如果不及時(shí)跟進(jìn)服務(wù)拆分,跨團(tuán)隊(duì)協(xié)作不暢、溝通困難等問(wèn)題就會(huì)接踵而來(lái)。本質(zhì)上,這些問(wèn)題都源于團(tuán)隊(duì)分工和核心目標(biāo)的差異。
案例介紹
vivo在互聯(lián)網(wǎng)早期就開(kāi)展了游戲聯(lián)運(yùn)業(yè)務(wù),游戲聯(lián)運(yùn)全稱(chēng)是游戲聯(lián)合運(yùn)營(yíng),具體指的是游戲研發(fā)廠商以合作分成的方式將產(chǎn)品嫁接到vivo平臺(tái)上運(yùn)營(yíng)。起初vivo互聯(lián)網(wǎng)團(tuán)隊(duì)規(guī)模較小,和帳號(hào)相關(guān)的業(yè)務(wù)統(tǒng)一歸屬于現(xiàn)在的系統(tǒng)帳號(hào)團(tuán)隊(duì)。在游戲聯(lián)運(yùn)業(yè)務(wù)中,我們提供為不同的游戲創(chuàng)建對(duì)應(yīng)的子帳號(hào)(即游戲小號(hào))的服務(wù),子帳號(hào)下包括游戲角色等相關(guān)信息。
隨著游戲業(yè)務(wù)快速發(fā)展,游戲事業(yè)部成立,其核心目標(biāo)是服務(wù)好游戲用戶(hù)。而系統(tǒng)帳號(hào)的目標(biāo),則是要從整個(gè)vivo生態(tài)出發(fā),為我們的手機(jī)用戶(hù),提供簡(jiǎn)單、安全的使用體驗(yàn)。在組織架構(gòu)變動(dòng)后不久,兩個(gè)團(tuán)隊(duì)便快速達(dá)成了業(yè)務(wù)邊界共識(shí),并完成了對(duì)應(yīng)服務(wù)的拆分。

圖2(游戲小號(hào)拆分)
2.1.2 基于穩(wěn)定性述求拆分
針對(duì)組織架構(gòu)調(diào)整導(dǎo)致的服務(wù)拆分,屬于外因,其內(nèi)容范圍和時(shí)間點(diǎn)相對(duì)容易確定。而基于對(duì)穩(wěn)定性的考慮進(jìn)行的拆分,屬于內(nèi)因,則需要在恰當(dāng)?shù)臅r(shí)機(jī)進(jìn)行,以避免對(duì)業(yè)務(wù)正常版本迭代造成影響。在實(shí)踐過(guò)程中,拆分策略上我們更多是基于核心流程的拆分。
(1)核心行為拆分
一個(gè)業(yè)務(wù)系統(tǒng)中,都會(huì)存在核心流程。核心流程承擔(dān)了系統(tǒng)中核心的工作。以帳號(hào)為例:注冊(cè)、登錄、憑證校驗(yàn),毫無(wú)疑問(wèn)就是系統(tǒng)中核心的流程,我們將核心流程獨(dú)立拆分,主要為了下面兩個(gè)目標(biāo)達(dá)成:
服務(wù)隔離
避免不同流程之間的相互影響。以帳號(hào)憑證校驗(yàn)流程為例,驗(yàn)證邏輯固定,架構(gòu)上只依賴(lài)分布式緩存。一旦和其它流程耦合,除了帶來(lái)更多外部依賴(lài)風(fēng)險(xiǎn)外,其它流程修改、發(fā)版同樣會(huì)影響到憑證校驗(yàn)流程的穩(wěn)定性。
資源隔離
服務(wù)拆分使得服務(wù)器資源得以隔離,這種隔離為橫向資源擴(kuò)容提供了更加靈活的可能性。例如,對(duì)于核心流程服務(wù),資源可以做適當(dāng)冗余,動(dòng)態(tài)擴(kuò)縮容的策略可以定制等。
如何識(shí)別核心行為?
有些核心流程是顯而易見(jiàn)的,比如帳號(hào)中的注冊(cè)和登錄,但有些流程需要進(jìn)行識(shí)別和判斷。我們的實(shí)踐是根據(jù)“業(yè)務(wù)價(jià)值”和“調(diào)用頻度”這兩個(gè)維度進(jìn)行判斷,其中“業(yè)務(wù)價(jià)值”可以選擇與核心業(yè)務(wù)指標(biāo)相關(guān)聯(lián)的流程,而“調(diào)用頻度”則對(duì)應(yīng)流程的執(zhí)行次數(shù)。將這兩個(gè)維度疊加,我們可以得到一個(gè)四象限矩陣圖。下圖是帳號(hào)業(yè)務(wù)的矩陣示意圖(圖3)。最核心的流程位于圖中右上角(價(jià)值高、調(diào)用高),這里有個(gè)原則,位于對(duì)角線的流程要盡可能的相互隔離;

圖3(矩陣圖)
(2)最少要素聚合
服務(wù)并非拆分得越細(xì)越好,過(guò)于細(xì)致的拆分會(huì)導(dǎo)致服務(wù)數(shù)量過(guò)多,反而增加了系統(tǒng)的復(fù)雜度和維護(hù)成本。為了避免過(guò)度拆分,我們可以對(duì)流程中依賴(lài)的業(yè)務(wù)要素進(jìn)行分析,并適當(dāng)進(jìn)行流程間的聚合。以注冊(cè)為例,流程最簡(jiǎn)化的情況下,只需圍繞帳號(hào)四要素(用戶(hù)名、密碼、郵箱、手機(jī)號(hào))完成即可。而對(duì)于換綁手機(jī)號(hào)流程,它依賴(lài)于密碼或原手機(jī)號(hào)的驗(yàn)證(四要素中的其中兩項(xiàng))。因此,我們可以將注冊(cè)和手機(jī)號(hào)換綁這兩個(gè)流程合并到同一個(gè)服務(wù)中,以降低維護(hù)成本。

圖4(最小要素閉環(huán))
(3)整體拆分示意
早期的帳號(hào)主服務(wù)包含了帳號(hào)登錄、注冊(cè)、憑證校驗(yàn)、用戶(hù)資料查詢(xún)/修改等流程。如果需要對(duì)服務(wù)進(jìn)行拆分,我們應(yīng)該首先梳理核心流程。按照上面圖4的示意,我們應(yīng)該先完成登錄、注冊(cè)、憑證校驗(yàn)與用戶(hù)資料的拆分。用戶(hù)資料主要包含昵稱(chēng)、頭像等擴(kuò)展信息,不包括帳號(hào)主體的四個(gè)要素(用戶(hù)名、密碼、郵箱、手機(jī)號(hào))。
對(duì)于登錄、注冊(cè)、憑證校驗(yàn)這三個(gè)行為,隨著已注冊(cè)用戶(hù)數(shù)量的增加,登錄和憑證校驗(yàn)的頻度遠(yuǎn)遠(yuǎn)超過(guò)注冊(cè)。因此,我們進(jìn)行了二次拆分,將登錄和憑證校驗(yàn)拆分為一個(gè)服務(wù),將注冊(cè)拆分為另一個(gè)服務(wù)。拆分后的結(jié)構(gòu)如下圖所示(圖5)。

圖5
(4)業(yè)務(wù)價(jià)值變化
業(yè)務(wù)價(jià)值是動(dòng)態(tài)變化的,因此我們需要根據(jù)業(yè)務(wù)的變化來(lái)適時(shí)地調(diào)整服務(wù)拆分的結(jié)構(gòu)。實(shí)踐案例有帳號(hào)信息服務(wù)中實(shí)名模塊的拆分。早期實(shí)名信息只是用在評(píng)論場(chǎng)景中,因此其價(jià)值和昵稱(chēng)、頭像等信息區(qū)別不大。但隨著游戲業(yè)務(wù)深度開(kāi)展以及國(guó)家防沉迷的要求,如果用戶(hù)未實(shí)名認(rèn)證,則無(wú)法提供相關(guān)服務(wù)。實(shí)名信息對(duì)于游戲業(yè)務(wù)的重要性等同于憑證校驗(yàn)。因此,我們將實(shí)名模塊拆分為獨(dú)立的服務(wù),以便更好地支持業(yè)務(wù)的發(fā)展和變化。
2.1.3 拆分實(shí)施方案
在對(duì)成熟業(yè)務(wù)進(jìn)行服務(wù)拆分時(shí),穩(wěn)定性是關(guān)鍵。必須確保對(duì)業(yè)務(wù)沒(méi)有任何影響,并且用戶(hù)無(wú)感知。為了降低拆分實(shí)施的難度,我們會(huì)采取先拆服務(wù)(圖6),再拆數(shù)據(jù)的方案。在服務(wù)拆分時(shí),為了進(jìn)一步降低風(fēng)險(xiǎn),可以考慮下面兩點(diǎn)做法:
- 服務(wù)拆分階段,只做代碼遷移,不做代碼重構(gòu)
- 引入灰度能力,通過(guò)可控的流量進(jìn)行梯度驗(yàn)證

圖6
需要再次強(qiáng)調(diào)灰度的重要性,用可控的流量去驗(yàn)證拆分后的服務(wù)。這邊介紹兩種灰度實(shí)現(xiàn)思路:
- 在應(yīng)用層中做轉(zhuǎn)發(fā),具體處理細(xì)節(jié):為新服務(wù)申請(qǐng)一個(gè)內(nèi)網(wǎng)域名,在原有服務(wù)內(nèi)進(jìn)行攔截實(shí)現(xiàn)請(qǐng)求轉(zhuǎn)發(fā)的邏輯。
- 在架構(gòu)的更加前置的環(huán)節(jié),完成流量分配。例如:在入口網(wǎng)關(guān)層或反向代理層(如Nginx)進(jìn)行流量轉(zhuǎn)發(fā)配置。
2.2 關(guān)系治理
服務(wù)之間的依賴(lài)關(guān)系對(duì)于服務(wù)架構(gòu)來(lái)說(shuō)是至關(guān)重要的。為了使服務(wù)間的依賴(lài)關(guān)系清晰、明確,我們可以采用以下幾個(gè)優(yōu)化措施:首先服務(wù)之間的依賴(lài)關(guān)系應(yīng)該是層次化的。每個(gè)服務(wù)應(yīng)該處于一個(gè)特定的層次,依賴(lài)關(guān)系應(yīng)該是層次化的,避免跨層級(jí)的依賴(lài)關(guān)系。其次依賴(lài)應(yīng)該是單向的,要符合ADP(Acyclic Dependencies Principle)無(wú)依賴(lài)環(huán)原則。
2.2.1 ADP原則
ADP(Acyclic Dependencies Principle)無(wú)依賴(lài)環(huán)原則,下圖(圖7)中紅色線標(biāo)識(shí)出來(lái)的依賴(lài)關(guān)系都是違背了ADP原則的存在。這種關(guān)系會(huì)影響“部署獨(dú)立”的目標(biāo)達(dá)成。試想下A、B服務(wù)互相依賴(lài)的場(chǎng)景,一次需求需同時(shí)對(duì)A、B相互依賴(lài)的接口改造,發(fā)版順序應(yīng)該是被依賴(lài)的先部署,相互依賴(lài)就進(jìn)入了死循環(huán)。

圖7
2.2.2 關(guān)系處理
在服務(wù)架構(gòu)中,服務(wù)之間的關(guān)系可以根據(jù)依賴(lài)的強(qiáng)度分為弱依賴(lài)和強(qiáng)依賴(lài)。當(dāng)A服務(wù)依賴(lài)于B服務(wù)時(shí),如果B服務(wù)異常故障時(shí),不會(huì)影響A服務(wù)的業(yè)務(wù)流程,那么這種依賴(lài)關(guān)系被稱(chēng)為弱依賴(lài);反之,如果B服務(wù)出現(xiàn)故障會(huì)導(dǎo)致A服務(wù)無(wú)法正常工作,那么這種依賴(lài)關(guān)系被稱(chēng)為強(qiáng)依賴(lài)。
(1)強(qiáng)依賴(lài)冗余
針對(duì)強(qiáng)依賴(lài)的關(guān)系,我們會(huì)采用冗余的策略,去保障核心服務(wù)流程的穩(wěn)定性。在帳號(hào)系統(tǒng)中,“一鍵登錄”、“實(shí)名認(rèn)證”都采用了同樣的方案。這種方案的實(shí)施前提是要能找到提供相同能力的多個(gè)服務(wù),其次服務(wù)本身需要做一些適配工作,如下圖(圖8)增加流量分配處理模塊,作用是監(jiān)控依賴(lài)服務(wù)的質(zhì)量,動(dòng)態(tài)調(diào)整流量分配比例等。

圖8
除了采用動(dòng)態(tài)流量分配的實(shí)現(xiàn),還可以選擇相對(duì)簡(jiǎn)單的主次方案,即固定依賴(lài)其中一個(gè)服務(wù),當(dāng)該服務(wù)出現(xiàn)異常或熔斷時(shí),再依賴(lài)另一個(gè)服務(wù)。這種主次方案可以在一定程度上提高服務(wù)的可用性,同時(shí)也相對(duì)簡(jiǎn)單易行。
(2)弱依賴(lài)異步
異步常用方案是依賴(lài)獨(dú)立的消息組件(圖9),把原本同步調(diào)用的處理改為消息發(fā)送。這樣做除了能實(shí)現(xiàn)依賴(lài)關(guān)系的解耦,同時(shí)能增加系統(tǒng)吞吐量。回顧ADP原則中我們提到的循環(huán)依賴(lài),是可以通過(guò)消息組件進(jìn)行解耦規(guī)避的。

圖9
需要提醒的是使用消息組件會(huì)增加系統(tǒng)的復(fù)雜性,異步天生要比同步更復(fù)雜,需要額外考慮消息亂序、延遲、丟失等問(wèn)題。針對(duì)這些問(wèn)題可以嘗試下面方案:不在服務(wù)流程中直接發(fā)送消息,而是依賴(lài)服務(wù)流程產(chǎn)生的數(shù)據(jù),進(jìn)行消息生產(chǎn),如下圖(圖10)。帳號(hào)系統(tǒng)中使用場(chǎng)景有帳號(hào)注冊(cè)、注銷(xiāo)后的業(yè)務(wù)通知。

圖10
選擇kafka組件是可以提供消息的有序性的特征。方案中從binlog采集、到推送消息,可以理解成是一個(gè)數(shù)據(jù)傳輸服務(wù)(Data Transmission Service,簡(jiǎn)稱(chēng)DTS),在vivo內(nèi)部有自研的“魯班平臺(tái)”實(shí)現(xiàn)了DTS能力,對(duì)于讀者朋友可以借助類(lèi)似開(kāi)源的Canal項(xiàng)目達(dá)成同樣的效果。
三、數(shù)據(jù)架構(gòu)治理
3.1 緩存
在高并發(fā)的系統(tǒng)架構(gòu)中,緩存是提升系統(tǒng)性能最有效的方式之一。緩存可以分為本地緩存和分布式緩存兩種。在帳號(hào)系統(tǒng)中,為了應(yīng)對(duì)不同的場(chǎng)景,我們采用了本地緩存和分布式緩存結(jié)合的方式。
3.1.1 本地緩存
本地緩存就是將數(shù)據(jù)緩存到服務(wù)本地內(nèi)存中,好處是響應(yīng)時(shí)間快、不受跨進(jìn)程通信等外部因素影響。但弊端也非常多,受服務(wù)內(nèi)存大小的限制,以及多節(jié)點(diǎn)的一致性問(wèn)題等,在帳號(hào)中使用的場(chǎng)景是緩存相對(duì)固定不變的數(shù)據(jù)。
3.1.2 分布式緩存
分布式緩存能有效規(guī)避服務(wù)內(nèi)存大小限制等問(wèn)題,同時(shí)提供了相對(duì)數(shù)據(jù)庫(kù)更好的讀寫(xiě)性能。但是引入分布式緩存同樣會(huì)帶來(lái)額外問(wèn)題,其中最突出的就是數(shù)據(jù)一致性問(wèn)題。
(1)數(shù)據(jù)一致性
處理數(shù)據(jù)一致性的方案有很多選擇,根據(jù)帳號(hào)使用的業(yè)務(wù)場(chǎng)景,我們選擇的方案是:Cache Aside Pattern。Cache Aside Pattern 具體邏輯如下:
- 數(shù)據(jù)查詢(xún):從緩存取,命中直接返回,未命中則從數(shù)據(jù)庫(kù)取并設(shè)置到緩存。
- 數(shù)據(jù)更新:先更新數(shù)據(jù)到數(shù)據(jù)庫(kù),后直接刪除緩存。

圖11 (Cache Aside Pattern示意圖)
處理的核心要點(diǎn)是數(shù)據(jù)更新時(shí)直接刪除緩存,而不是刷新緩存。這是為了規(guī)避,并發(fā)修改可能導(dǎo)致的數(shù)據(jù)不一致。當(dāng)然Cache Aside Pattern是不能杜絕一致性問(wèn)題。
主要是下面兩種場(chǎng)景:
第一種情況刪除緩存異常。這種要么可以嘗試重試,或直接依賴(lài)設(shè)定合理的過(guò)期時(shí)間來(lái)降低影響。
第二種情況是理論上的可能性,概率非常低。
一個(gè)讀操作,沒(méi)有命中緩存,到數(shù)據(jù)庫(kù)中取數(shù)據(jù),此時(shí)來(lái)了一個(gè)寫(xiě)操作,寫(xiě)完數(shù)據(jù)庫(kù)后刪除了緩存,然后之前的讀再把老的數(shù)據(jù)寫(xiě)入緩存。說(shuō)它理論上存在是因?yàn)闂l件過(guò)于苛刻,首先需要發(fā)生在讀緩存時(shí)緩存失效,而且并發(fā)一個(gè)寫(xiě)操作。然后我們知道數(shù)據(jù)庫(kù)的寫(xiě)操作通常會(huì)比讀操作慢得多,而發(fā)生問(wèn)題是要求讀操作必需在寫(xiě)操作前進(jìn)入數(shù)據(jù)庫(kù)操作,而又要晚于寫(xiě)操作更新緩存,所以說(shuō)它只是理論上的可能性。
基于上述情況綜合考慮,我們選擇的是Cache Aside Pattern方案,盡可能去降低并發(fā)臟數(shù)據(jù)發(fā)生的概率,而非通過(guò)復(fù)雜度更高的2PC或是Paxos協(xié)議保證強(qiáng)一致性。
(2)批量讀操作優(yōu)化
盡管使用緩存可以顯著提升系統(tǒng)的性能,但并不能解決所有的性能問(wèn)題。在帳號(hào)服務(wù)中,我們提供了用戶(hù)資料查詢(xún)能力,根據(jù)用戶(hù)標(biāo)識(shí)獲取用戶(hù)的昵稱(chēng)、頭像、簽名等信息。為了提高接口的性能,我們將相關(guān)信息緩存在Redis中。然而,隨著用戶(hù)量和調(diào)用量的快速增長(zhǎng),以及批量查詢(xún)的新增需求,Redis的容量和服務(wù)接口的性能都面臨著壓力。
為了解決這些問(wèn)題,我們采取了一系列有針對(duì)性的優(yōu)化措施:
首先,我們?cè)趯⒕彺鏀?shù)據(jù)寫(xiě)入Redis前,先對(duì)其進(jìn)行壓縮。這樣可以減小緩存數(shù)據(jù)的大小,從而降低了數(shù)據(jù)在網(wǎng)絡(luò)傳輸和存儲(chǔ)過(guò)程中的開(kāi)銷(xiāo)。
接著,我們更換默認(rèn)的序列化方式,選擇了protostuff作為替代方案。protostuff是一種高效的序列化框架,相比其他序列化框架具有以下優(yōu)勢(shì):
- 高性能:protostuff采用了零拷貝技術(shù),直接將對(duì)象序列化為字節(jié)數(shù)組,避免了中間對(duì)象的創(chuàng)建和拷貝,從而大幅度提高了序列化和反序列化的性能。
- 空間效率:由于采用了緊湊的二進(jìn)制格式,protostuff可以將對(duì)象序列化為更小的字節(jié)數(shù)組,從而節(jié)省了存儲(chǔ)空間。
- 易用性:protostuff是基于protobuf開(kāi)發(fā),但對(duì)Java語(yǔ)言的支持更加完善,只需要定義好Java對(duì)象的結(jié)構(gòu)和注解,就可以進(jìn)行序列化和反序列化操作。
序列化的方案還有很多,例如thrift等,關(guān)于它們的性能對(duì)比,可以參考下圖(圖12),讀者可以自己項(xiàng)目實(shí)際情況進(jìn)行選擇。

圖12(圖片來(lái)源:Google Code)
最后,是Redis Pipeline命令的應(yīng)用。Pipeline可以將多個(gè)Redis命令打包成一個(gè)請(qǐng)求,一次性發(fā)送給Redis服務(wù)器,從而減少了網(wǎng)絡(luò)延遲和服務(wù)器負(fù)載。Redis Pipeline的主要作用是提高Redis的吞吐量和降低延遲,尤其是在需要執(zhí)行大量相同Redis命令的情況下,效果更加明顯。
以上優(yōu)化最終給我們帶來(lái)了一半的Redis容量的節(jié)省和5倍左右的性能提升,但同時(shí)也增加了大概10%的額外CPU消耗。
3.2 數(shù)據(jù)庫(kù)
數(shù)據(jù)庫(kù)相對(duì)于應(yīng)用服務(wù),在高并發(fā)系統(tǒng)更容易成為系統(tǒng)的瓶頸。它無(wú)法做到和應(yīng)用一樣便利的橫向擴(kuò)容,所以數(shù)據(jù)庫(kù)的規(guī)劃工作一定要打提前量。
3.2.1 讀寫(xiě)分離
帳號(hào)業(yè)務(wù)特點(diǎn)是讀多寫(xiě)少,所以最早遇到的壓力是數(shù)據(jù)庫(kù)讀的壓力,而讀寫(xiě)分離架構(gòu)(圖13)可以有效降低主庫(kù)的負(fù)載。讀寫(xiě)分離方案中由主庫(kù)承擔(dān)全部寫(xiě)流量,從庫(kù)和主庫(kù)共同承擔(dān)讀流量。從庫(kù)同時(shí)可以配置多個(gè),通過(guò)多個(gè)從庫(kù)來(lái)分擔(dān)高并發(fā)的查詢(xún)流量

圖13
保留主庫(kù)的讀能力,是因?yàn)? “主從同步延遲” 問(wèn)題存在,對(duì)不能接受數(shù)據(jù)延遲的場(chǎng)景繼續(xù)查詢(xún)主庫(kù)。 讀寫(xiě)分離方案的好處是簡(jiǎn)單,幾乎沒(méi)有代碼改造成本,只需要新增數(shù)據(jù)庫(kù)的主從關(guān)系。缺點(diǎn)也比較多,比如無(wú)法解決TPS(寫(xiě)) 高的問(wèn)題,從庫(kù)也不能無(wú)節(jié)制添加,從庫(kù)數(shù)量過(guò)多會(huì)加重延遲問(wèn)題。
3.2.2 分表分庫(kù)
讀寫(xiě)分離肯定是解決不了所有的問(wèn)題,一些場(chǎng)景需要結(jié)合分表分庫(kù)的方案。分表分庫(kù)的方案分為垂直拆分和水平拆分兩種,vivo互聯(lián)網(wǎng)技術(shù)公眾號(hào)有過(guò)分庫(kù)分表方案的詳解,這邊不在贅述,有興趣的可以前往閱讀 詳談水平分庫(kù)分表 。在這邊和大家聊聊分表分庫(kù)動(dòng)機(jī)及一些輔助決策的經(jīng)驗(yàn)總結(jié)。
(1)分表解決什么問(wèn)題
籠統(tǒng)的回答就是解決大表帶來(lái)的性能問(wèn)題。具體影響在哪里?怎么判斷是不是要分表?
① 查詢(xún)效率
大表最直接給人的感受是會(huì)影響查詢(xún)效率,我們以 mysql-InnoDB為例分析下具體影響。InnoDB存儲(chǔ)引擎是以B+Tree結(jié)構(gòu)組織索引,以主鍵索引(聚簇索引)為例,它的特性是葉子節(jié)點(diǎn)存放完整數(shù)據(jù),非葉子節(jié)點(diǎn)存放鍵值+頁(yè)地址指針。這邊的節(jié)點(diǎn),對(duì)應(yīng)到存儲(chǔ)就是數(shù)據(jù)頁(yè)的概念。數(shù)據(jù)頁(yè)是InnoDB最小存儲(chǔ)單元,默認(rèn)大小為16k。一個(gè)聚簇索引的示意圖(圖14)如下:

圖14
聚簇索引樹(shù)上做數(shù)據(jù)的查詢(xún)操作,是從根節(jié)點(diǎn)出發(fā),節(jié)點(diǎn)內(nèi)做二分查找來(lái)確定樹(shù)下一層的數(shù)據(jù)頁(yè)位子,到達(dá)葉子節(jié)點(diǎn)后同樣通過(guò)二分查找來(lái)定位數(shù)據(jù)。從這個(gè)查找過(guò)程,我們可以看出對(duì)查詢(xún)的影響,主要取決于索引樹(shù)的高度。多一個(gè)層高,會(huì)多出一次數(shù)據(jù)頁(yè)的load(內(nèi)存不存在發(fā)生)和一次數(shù)據(jù)頁(yè)內(nèi)的二分查找。
想評(píng)估數(shù)據(jù)量對(duì)查詢(xún)的影響,可以通過(guò)估算索引樹(shù)的高度和數(shù)據(jù)量的關(guān)系來(lái)達(dá)成。前面提到非葉子節(jié)點(diǎn)存放鍵值+頁(yè)地址指針,頁(yè)地址指針大小固定是6個(gè)字節(jié),那么一個(gè)非葉子節(jié)點(diǎn)存儲(chǔ)量計(jì)算公式大概是 pagesize/(index size+6)。葉子節(jié)點(diǎn)存儲(chǔ)的是具體數(shù)據(jù),存儲(chǔ)的數(shù)量公示可以簡(jiǎn)化為pagesize/(data size),這樣樹(shù)的高度和數(shù)據(jù)量的關(guān)系如下:

根據(jù)公式,我們以自增BIGINT字段做主鍵,單行數(shù)據(jù)大小1k,數(shù)據(jù)頁(yè)大小為默認(rèn)16K為例,3層的樹(shù)結(jié)構(gòu)容納的數(shù)據(jù)量大概在兩千萬(wàn)樣子。這個(gè)方式只是輔助你做估算,如果要確定真實(shí)值,是可以借助一些工具直接在數(shù)據(jù)頁(yè)中獲取。
了解了這些后再看分表方案背后的邏輯。水平拆分是主動(dòng)控制表中的數(shù)據(jù)量,來(lái)達(dá)到控制樹(shù)高度的目的。而表的垂直拆分是增加葉子節(jié)點(diǎn)的容量,這樣相同高度的樹(shù),可以容下更多數(shù)據(jù)。
② 表結(jié)構(gòu)調(diào)整效率
業(yè)務(wù)變更偶爾會(huì)牽扯到表結(jié)構(gòu)調(diào)整,例如:新增字段、調(diào)整字段大小、增加索引等等。你會(huì)發(fā)現(xiàn)表的數(shù)據(jù)量越大,一些DDL 的執(zhí)行時(shí)間會(huì)越來(lái)越長(zhǎng),有些線上大表增加字段的執(zhí)行時(shí)間可能會(huì)花費(fèi)數(shù)天。具體哪些DDL會(huì)比較耗時(shí)呢?可以參考mysql官網(wǎng)關(guān)于online-ddl的操作說(shuō)明(詳情),關(guān)注操作是否涉及Rebuilds Table,如果涉及,數(shù)據(jù)量越大越大越費(fèi)時(shí)。
除了表結(jié)構(gòu)調(diào)整、數(shù)據(jù)查詢(xún)這些影響外,數(shù)據(jù)量越大對(duì)于失誤的容錯(cuò)性越差,這對(duì)于穩(wěn)定性保障工作是個(gè)隱患。
基于上面的原因描述,業(yè)務(wù)中勁量把索引樹(shù)的高度控制在3層,這時(shí)候表數(shù)據(jù)量級(jí)大概在千萬(wàn)級(jí)別。如果數(shù)據(jù)量增長(zhǎng)超過(guò)這個(gè)預(yù)期后,就要評(píng)估數(shù)據(jù)表對(duì)業(yè)務(wù)的重要程度、使用場(chǎng)景等,然后適時(shí)進(jìn)行表的拆分。
(2)分庫(kù)解決什么問(wèn)題
分庫(kù)通常理解解決的是資源瓶頸的問(wèn)題。單個(gè)數(shù)據(jù)庫(kù),即使硬件再?gòu)?qiáng)大,它也是有連接數(shù)、磁盤(pán)空間等上限問(wèn)題。分庫(kù)后就可以將不同的實(shí)例部署在不同的物理機(jī)上,突破磁盤(pán)、連接數(shù)等資源瓶頸,同時(shí)能提供更好的性能表現(xiàn)。
分庫(kù)的處理除了基于資源限制的考慮外,帳號(hào)中還會(huì)結(jié)合可靠性等述求,進(jìn)行數(shù)據(jù)庫(kù)的拆分。這樣可以把核心模塊和非核心模塊隔離,減少之間的相互影響。目前帳號(hào)系統(tǒng)的拆后情況示意如下(圖15)。

圖15
拆分后的帳號(hào)主體庫(kù),是最核心業(yè)務(wù)庫(kù)。庫(kù)里圍繞帳號(hào)四要素(用戶(hù)名、密碼、郵箱、手機(jī)號(hào))組織數(shù)據(jù),這樣帳號(hào)的核心流程登錄、注冊(cè)的數(shù)據(jù)依賴(lài)就不再受其他數(shù)據(jù)的干擾。這種拆分方式屬于垂直拆分,將表根據(jù)一定的規(guī)則劃入不同的庫(kù)。
(3)數(shù)據(jù)遷移實(shí)踐
分庫(kù)分表方案實(shí)施中代價(jià)最大的是數(shù)據(jù)遷移,帳號(hào)系統(tǒng)在垂直分庫(kù)實(shí)踐中主要利用mysql的主從復(fù)制機(jī)制來(lái)降低數(shù)據(jù)遷移的成本。先讓DBA在原有主庫(kù)上掛新的從庫(kù),將表數(shù)據(jù)復(fù)制到新庫(kù)中。為保證數(shù)據(jù)一致性,線上切庫(kù)時(shí)分三步處理(圖16)。
- step1:禁寫(xiě)主庫(kù),確保主從數(shù)據(jù)同步一致 ;
- step2:斷開(kāi)主從,新庫(kù)成為獨(dú)立主庫(kù);
- step3:應(yīng)用完成新庫(kù)路由切換(開(kāi)關(guān)實(shí)現(xiàn))。

圖16
這些操作在DBA的配合下,可以把對(duì)業(yè)務(wù)的影響控制在分鐘級(jí),影響相對(duì)可控。而且整個(gè)方案代碼層面改造成本也非常小。唯一要注意的是一定要做上線前的演練。
除了上面垂直分庫(kù)的場(chǎng)景外,帳號(hào)還經(jīng)歷過(guò)單個(gè)核心業(yè)務(wù)表數(shù)據(jù)量過(guò)億后的水平拆分,這個(gè)場(chǎng)景復(fù)制遷移的方案就不適用。拆分是在18年底實(shí)施的,方案借助開(kāi)源的Canal實(shí)現(xiàn)數(shù)據(jù)遷移。整體方案如下(圖17)。

圖17
四、監(jiān)控治理
監(jiān)控治理的目的,是讓我們實(shí)時(shí)了解系統(tǒng)狀況,及時(shí)進(jìn)行故障的預(yù)警,并能輔助快速的問(wèn)題定位。早期帳號(hào)就經(jīng)歷過(guò),告警內(nèi)容不全面,研發(fā)不能及時(shí)收到告警。有時(shí)收到了告警,但因?yàn)樵蛑赶虿幻鳎婢瘑?wèn)題排查困難,處理時(shí)間過(guò)長(zhǎng)等。隨著持續(xù)治理,經(jīng)過(guò)多次線上的驗(yàn)證,我們能做到問(wèn)題感知靈敏,處理迅速。
4.1 監(jiān)控內(nèi)容
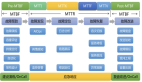
我們把監(jiān)控的內(nèi)容歸納為三個(gè)維度(圖18),從上到下分別是:
- 上層的應(yīng)用服務(wù)監(jiān)控:監(jiān)控應(yīng)用層的狀況,例如:服務(wù)訪問(wèn)的吞吐量、返回碼(失敗量)、響應(yīng)時(shí)間、業(yè)務(wù)異常等;
- 中層獨(dú)立組件監(jiān)控:獨(dú)立組件涵蓋服務(wù)運(yùn)行的中間件,例如:Redis(緩存)、MQ(消息)、MySQL(存儲(chǔ))、Tomcat(容器)、JVM 等;
- 底層系統(tǒng)資源監(jiān)控:監(jiān)控主機(jī)和底層資源,例如:CPU、內(nèi)存、硬盤(pán) I/O、網(wǎng)絡(luò)吞吐等;
監(jiān)控內(nèi)容涵蓋三層的原因,如果你只關(guān)注應(yīng)用服務(wù),如果問(wèn)題發(fā)生,你只是知道了一個(gè)結(jié)果,無(wú)法進(jìn)行快速定位分析,只能根據(jù)經(jīng)驗(yàn)排查各項(xiàng)的可能性,這樣的故障處理速度是沒(méi)辦法忍受的。而往往上層的應(yīng)用的告警,可能就是一些組件或則底層系統(tǒng)資源的異常引起的。假設(shè)我們遇到服務(wù)響應(yīng)時(shí)長(zhǎng)告警時(shí),如果這時(shí)候有對(duì)應(yīng)JVM FGC 時(shí)長(zhǎng)告警、或myql的慢查sql告警,這就很方便我們快速的明確優(yōu)先排查的方向,確定后續(xù)的處理措施。

圖18
組件監(jiān)控、底層資源監(jiān)控除了有支撐定位問(wèn)題的作用外,另一個(gè)目的是可以提前排除隱患。很多隱患一開(kāi)始對(duì)應(yīng)用服務(wù)影響比較有限,但這種影響會(huì)隨著調(diào)用量等外部因數(shù)變化慢慢放大。
監(jiān)控內(nèi)容的維護(hù),三個(gè)維度的監(jiān)控內(nèi)容中,底層系統(tǒng)資源和中層獨(dú)立組件,內(nèi)容相對(duì)固定,不需要經(jīng)常維護(hù)。而上層的應(yīng)用服務(wù)監(jiān)控中涉及業(yè)務(wù)異常的,就需要隨著功能版本迭代,不停的做加減法。
4.2 關(guān)聯(lián)指標(biāo)聚合
三個(gè)維度監(jiān)控的內(nèi)容,因?yàn)楣緝?nèi)分工的存在,研發(fā)、應(yīng)用運(yùn)維、系統(tǒng)運(yùn)維,容易出現(xiàn)各管各的,監(jiān)控指標(biāo)也可能會(huì)分散在不同系統(tǒng),這樣是非常不利于問(wèn)題定位分析。最好的監(jiān)控系統(tǒng)是能將這三個(gè)維度的指標(biāo)進(jìn)行打通,這樣問(wèn)題分析處理會(huì)更加高效。下面是我們?cè)诟櫋芭及l(fā)性dubbo服務(wù)線程滿(mǎn)”問(wèn)題時(shí)的經(jīng)歷。偶發(fā)性問(wèn)題排查的難點(diǎn),不能拿一次的分析結(jié)果定論。借助公司業(yè)務(wù)監(jiān)控系統(tǒng)的幫助,我們排除了redis等中間組件的影響后,我們就開(kāi)始將關(guān)注點(diǎn)放在了主機(jī)指標(biāo)上,為了方便問(wèn)題定位,我們自己做了 虛擬機(jī)反推 宿主物理 再到宿主機(jī)上所有虛擬機(jī)的關(guān)鍵指標(biāo)(CPU、IO、NET)聚合,效果如下(圖19)。經(jīng)過(guò)多次驗(yàn)證后確定了宿主機(jī)上個(gè)別應(yīng)用磁盤(pán)IO異常過(guò)高導(dǎo)致。

圖19
4.3 調(diào)用方區(qū)分
應(yīng)用服務(wù)監(jiān)控中,都會(huì)將服務(wù)接口調(diào)用量TOP N作為重點(diǎn)監(jiān)控對(duì)象。但在中臺(tái)服務(wù)中,只到接口的顆粒度還不夠,需要細(xì)化到能區(qū)分調(diào)用方的維度,去監(jiān)控具體某個(gè)接口上TOP N的調(diào)用方增長(zhǎng)趨勢(shì)。這樣做的好處,一是監(jiān)控的粒度越細(xì),越能提前感知到風(fēng)險(xiǎn)。二是一旦確認(rèn)是不合理流量時(shí),也可以有針對(duì)性地做流控等處理。
五、總結(jié)
本文從服務(wù)拆分、關(guān)系治理、緩存、數(shù)據(jù)庫(kù)、監(jiān)控治理幾個(gè)維度,介紹了帳號(hào)系統(tǒng)在穩(wěn)定性建設(shè)方面做的一些經(jīng)驗(yàn)總結(jié)。然而,僅僅做到這些是遠(yuǎn)遠(yuǎn)不夠的。穩(wěn)定性建設(shè)需要一套嚴(yán)謹(jǐn)科學(xué)的工程管理體系,涉及內(nèi)容不僅包括研發(fā)的設(shè)計(jì)、開(kāi)發(fā)和維護(hù),還應(yīng)該包含項(xiàng)目團(tuán)隊(duì)中各個(gè)角色的工作內(nèi)容。總而言之,穩(wěn)定性建設(shè)需要在整個(gè)項(xiàng)目生命周期中不斷進(jìn)行細(xì)致的規(guī)劃和實(shí)踐。我們也希望本文所述的經(jīng)驗(yàn)和思路,能夠?qū)ψx者在實(shí)踐中起到一定的指導(dǎo)作用。