擊敗ChatGPT?OpenChat霸榜斯坦福AlpacaEval開源榜首,性能高達105.7%
一夜之間,全新開源模型「OpenLLM」擊敗ChatGPT的消息,在網上引起軒然大波。
根據官方的介紹,OpenLLM:
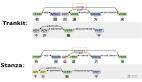
- 在斯坦福AlpacaEval上,以80.9%的勝率位列開源模型第一
- 在Vicuna GPT-4評測中,性能則達到了ChatGPT的105.7%
 圖片
圖片
最重要的是,如此卓越的性能,只需要6K的GPT-4對話數據進行微調訓練。
 圖片
圖片
項目地址:https://github.com/imoneoi/openchat
不過Chatbot Arena的「榜單主」提醒稱,由于舊的Vicu?a eval基準存在一些bias,因此提倡大家遷移到新提出的MT-bench上——從而更好地測評LLM更多方面的能力。
 圖片
圖片
OpenLLM:只需6K GPT-4對話微調
OpenLLM是一個在多樣化且高質量的多輪對話數據集上進行微調的開源語言模型系列。
具體來講,研究人員從約90K的ShareGPT對話中,過濾出來約6K的GPT-4對話。
經過6k數據微調后,令人驚訝的是,OpenLLM已經被證明可以在有限的數據下實現高性能。
OpenLLM有兩個通用模型,它們是OpenChat和OpenChat-8192。
 圖片
圖片
OpenChat:基于LLaMA-13B微調,上下文長度為2048
- 在Vicuna GPT-4評估中達到ChatGPT分數的105.7%
- 在AlpacaEval上取得了驚人的80.9%的勝率
OpenChat-8192:基于LLaMA-13B微調,上下文長度為8192
- 在Vicuna GPT-4評估中達到ChatGPT分數的106.6%
- 在AlpacaEval上取得的79.5%勝率
 圖片
圖片
此外,OpenLLM還有代碼模型,其性能如下:
OpenCoderPlus:基于StarCoderPlus,原始上下文長度為8192
- 在Vicuna GPT-4評估中達到ChatGPT分數的102.5%
- 在AlpacaEval上獲得78.7%的勝率
模型評估
研究人員使用Vicuna GPT-4和AlpacaEval基準評估了最新模型,結果如下圖所示:
 圖片
圖片
Vicuna GPT-4評估(v.s. gpt-3.5-turbo)
 圖片
圖片
Vicuna GPT-3.5-Turbo評估(v.s. gpt-3.5-turbo)
另外,值得注意的是,研究者采用的評估模式與Vicuna的略有不同,還使用了證據校準(EC)+平衡位置校準(BPC)來減少潛在的偏差。
 圖片
圖片
安裝和權重
要使用OpenLLM,需要安裝CUDA和PyTorch。用戶可以克隆這個資源庫,并通過pip安裝這些依賴:
git clone git@github.com:imoneoi/OChat.git
pip install -r requirements.txt目前,研究人員已經提供了所有模型的完整權重作為huggingface存儲庫。
用戶可以使用以下命令在本地啟動一個API服務器,地址為http://localhost:18888。
 圖片
圖片
其中,服務器與openai包,以及ChatCompletions協議兼容(請注意,某些功能可能不完全支持)。
用戶可以通過設置以下方式指定openai包的服務器:
openai.api_base = "http://localhost:18888/v1"當前支持的ChatCompletions參數有:
 圖片
圖片
建議:使用至少40GB(1x A100)顯存的GPU來運行服務器。
數據集
轉換后的數據集可在openchat_sharegpt4_dataset上獲取。
項目中所使用的數據集,是對ShareGPT清洗和篩選后的版本。
其中,原始的ShareGPT數據集包含大約90,000個對話,而僅有6,000個經過清理的GPT-4對話被保留用于微調。
清洗后的GPT-4對話與對話模板和回合結束時的token相結合,然后根據模型的上下文限制進行截斷(超出限制的內容將被丟棄)。
要運行數據處理流程,請執行以下命令:
./ochat/data/run_data_pipeline.sh INPUT_FOLDER OUTPUT_FOLDER輸入文件夾應包含一個ShareGPT文件夾,其中包含每個ShareGPT對話頁面的.html文件。
數據處理流程包括三個步驟:
- 清洗:對HTML進行清理并轉換為Markdown格式,刪除格式錯誤的對話,刪除包含被屏蔽詞匯的對話,并進行基于哈希的精確去重處理
- 篩選:僅保留token為Model: GPT-4的對話
- 轉換:為了模型的微調,針對所有的對話進行轉換和分詞處理
最終轉換后的數據集遵循以下格式:
MODEL_TYPE.train.json / .eval.json
[
[token_id_list, supervise_mask_list],
[token_id_list, supervise_mask_list],
...
]MODEL_TYPE.train.text.json / .eval.text.json從token_id_list解碼的純文本
除此之外,研究人員還提供了一個用于可視化對話嵌入的工具。
只需用瀏覽器打開ochat/visualization/ui/visualizer.html,并將MODEL_TYPE.visualizer.json拖放到網頁中。點擊3D圖中的點,就可以顯示相應的對話。
其中,嵌入是使用openai_embeddings.py創建的,然后使用dim_reduction.ipynb進行UMAP降維和K-Means著色。
 圖片
圖片
模型修改
研究人員為每個基礎模型添加了一個EOT(對話結束)token。
對于LLaMA模型,EOT的嵌入初始化為所有現有token嵌入的平均值。對于StarCoder模型,EOT的嵌入以0.02標準差進行隨機初始化。
對于具有8192上下文的LLaMA-based模型,max_position_embeddings被設置為8192,并且進行了RoPE(相對位置編碼)代碼的外推。
訓練
訓練模型時使用的超參數在所有模型中都是相同的:
 圖片
圖片
使用8xA100 80GB進行訓練:
NUM_GPUS=8
deepspeed --num_gpus=$NUM_GPUS --module ochat.training_deepspeed.train \
--model_type MODEL_TYPE \
--model_path BASE_MODEL_PATH \
--save_path TARGET_FOLDER \
--length_grouping \
--epochs 5 \
--data_path DATASET_PATH \
--deepspeed \
--deepspeed_config ochat/training_deepspeed/deepspeed_config.json評估
要運行Vicuna GPT-4評估,請執行以下步驟:
1. 生成模型答案
python -m ochat.evaluation.get_model_answer --model_type MODEL_TYPE --models_path PATH_CONTAINING_ALL_MODELS_SAME_TYPE --data_path ./ochat/evaluation/vicuna --output_path ./eval_results2. 生成基線(GPT-3.5)答案
OPENAI_API_KEY=sk-XXX python -m ochat.evaluation.get_openai_answer --data_path ./ochat/evaluation/vicuna --output_path ./eval_baselines --model_types gpt-3.5-turbo3. 運行GPT-4評估
OPENAI_API_KEY=sk-XXX python -m ochat.evaluation.openai_eval --data_path ./ochat/evaluation/vicuna --baseline_path ./eval_baselines/vicuna_gpt-3.5-turbo.jsonl --input_path ./eval_results4. 可視化和細節
要獲得可視化和繪制評估結果,請使用瀏覽器打開ochat/visualization/eval_result_ui/eval_result_visualizer.html,并選擇./eval_results/eval_result_YYYYMMDD文件夾中的所有文件以顯示結果。
局限性
基礎模型限制
盡管能夠實現優秀的性能,但OpenLLM仍然受到其基礎模型固有限制的限制。這些限制可能會影響模型在以下領域的性能:
- 復雜推理
- 數學和算術任務
- 編程和編碼挑戰
不存在信息的幻覺
OpenLLM有時可能會產生不存在或不準確的信息,也稱為「幻覺」。用戶應該意識到這種可能性,并驗證從模型中獲得的任何關鍵信息。
參考資料:
https://github.com/imoneoi/openchat
https://tatsu-lab.github.io/alpaca_eval/