輕量級(jí)NLP工具開(kāi)源,中文處理更精準(zhǔn),超越斯坦福Stanza
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
最新輕量級(jí)多語(yǔ)言NLP工具集Trankit發(fā)布1.0版本,來(lái)自俄勒岡大學(xué)。
基于Transformer,性能已超越之前的熱門(mén)同類(lèi)項(xiàng)目斯坦福Stanza。
Trankit支持多達(dá)56種語(yǔ)言,除了簡(jiǎn)體和繁體中文以外,還支持文言文。
先來(lái)看一組Trankit與Stanza對(duì)文言文進(jìn)行依存句法分析的結(jié)果。
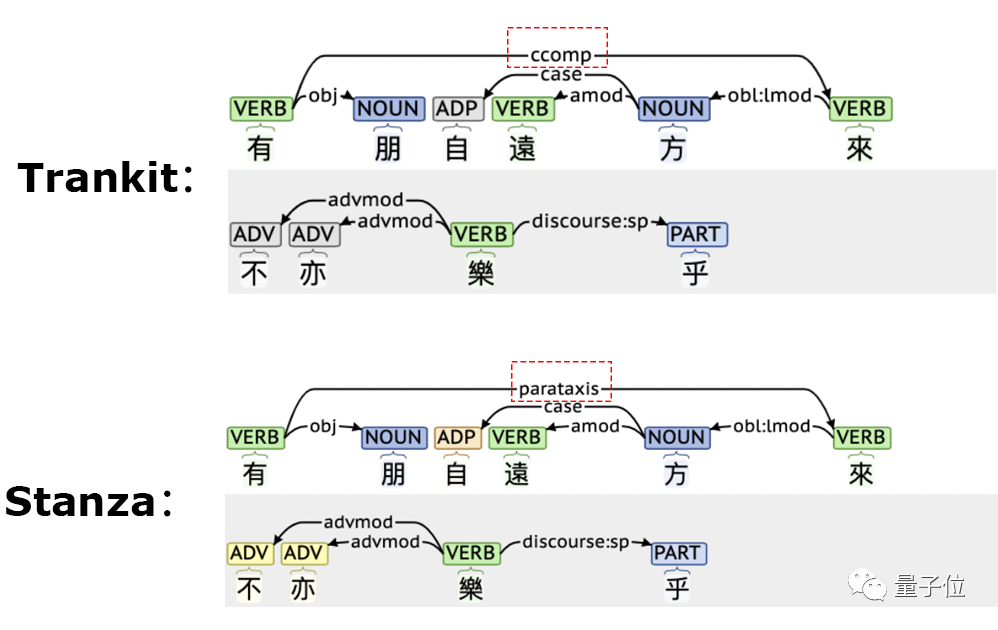
可以看到,Stanza錯(cuò)誤的將“有朋自遠(yuǎn)方來(lái)”中的“有”和“來(lái)”兩個(gè)動(dòng)詞判斷成并列關(guān)系。
在簡(jiǎn)體中文的詞性標(biāo)注任務(wù)上,Trankit對(duì)“自從”一詞處理也更好。

與Stanza一樣,Trankit也是基于Pytorch用原生Python實(shí)現(xiàn),對(duì)廣大Python用戶非常友好。
Trankit在多語(yǔ)言NLP多項(xiàng)任務(wù)上的性能超越Stanza。
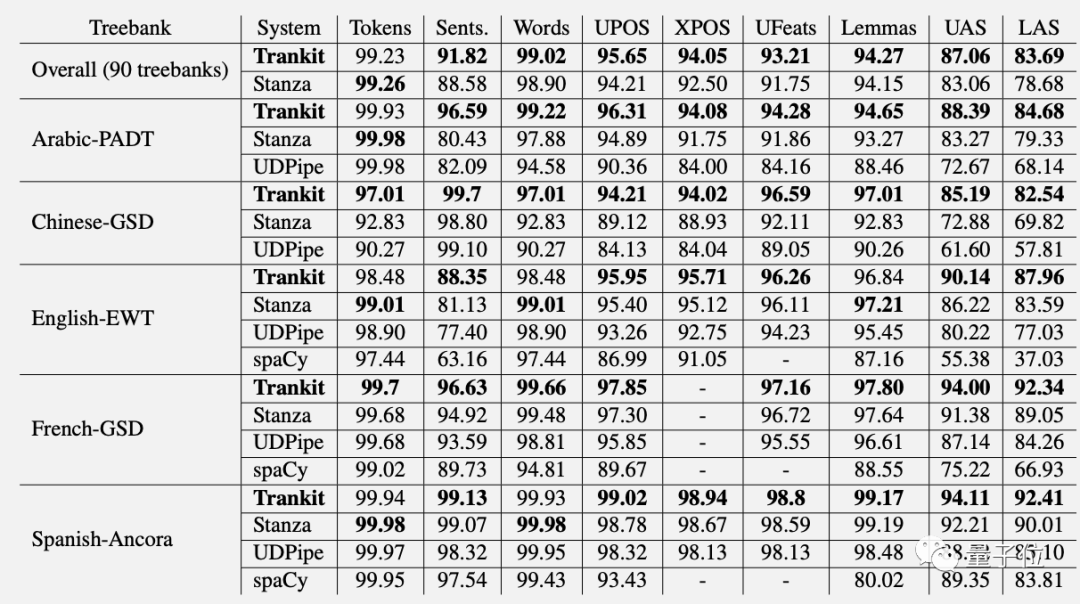
在英語(yǔ)分詞上的得分比Stanza高9.36%。在中文依存句法分析的UAS和LAS指標(biāo)上分別高出14.50%和15.0%。
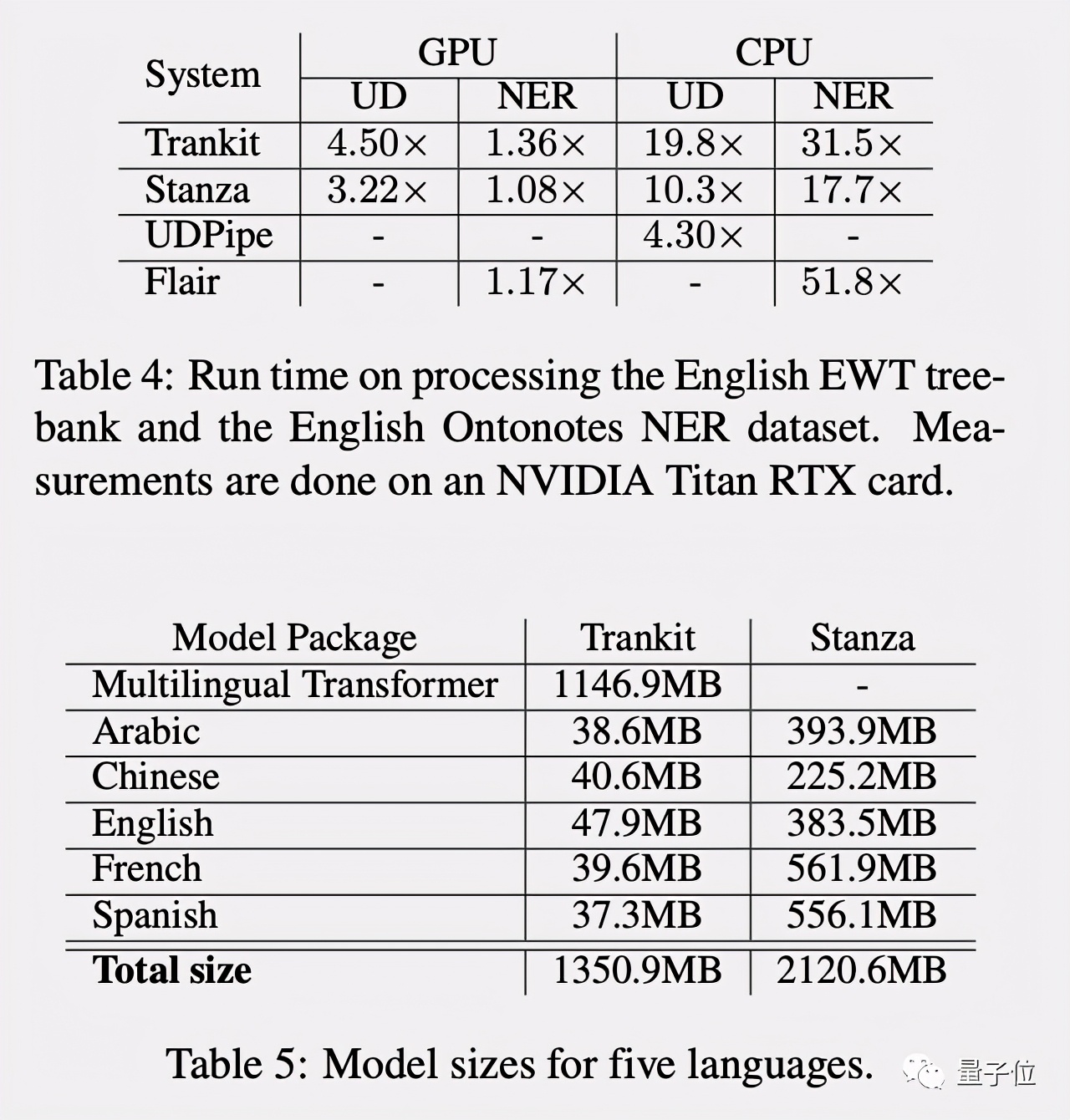
Trankit在GPU加持下加速更多,且占用內(nèi)存更小,作為一個(gè)輕量級(jí)NLP工具集更適合普通人使用。
簡(jiǎn)單易用
Trankit的使用也非常簡(jiǎn)單,安裝只要pip install就完事了。
- pip install trankit
不過(guò)需要注意的是,Trankit使用了Tokenizer庫(kù),需要先安裝Rust。
初始化一個(gè)預(yù)訓(xùn)練Pipeline:
- from trankit import Pipeline
- # initialize a multilingual pipeline
- p = Pipeline(lang='english', gpu=True, cache_dir='./cache')
開(kāi)啟auto模式,可以自動(dòng)檢測(cè)語(yǔ)言:
- from trankit import Pipeline
- p = Pipeline('auto')
- # Tokenizing an English input
- en_output = p.tokenize('''I figured I would put it out there anyways.''')
- # POS, Morphological tagging and Dependency parsing a French input
- fr_output = p.posdep('''On pourra toujours parler à propos d'Averroès de "décentrement du Sujet".''')
使用自定義標(biāo)注數(shù)據(jù)自己訓(xùn)練Pipeline也很方便:
- from trankit import TPipeline
- tp = TPipeline(training_config={
- 'task': 'tokenize',
- 'save_dir': './saved_model',
- 'train_txt_fpath': './train.txt',
- 'train_conllu_fpath': './train.conllu',
- 'dev_txt_fpath': './dev.txt',
- 'dev_conllu_fpath': './dev.conllu'
- }
- )
- trainer.train()
統(tǒng)一的多語(yǔ)言Transformer
Trankit將各種語(yǔ)言分別訓(xùn)練的Pipelines整合到一起共享一個(gè)多語(yǔ)言預(yù)訓(xùn)練Transformer。
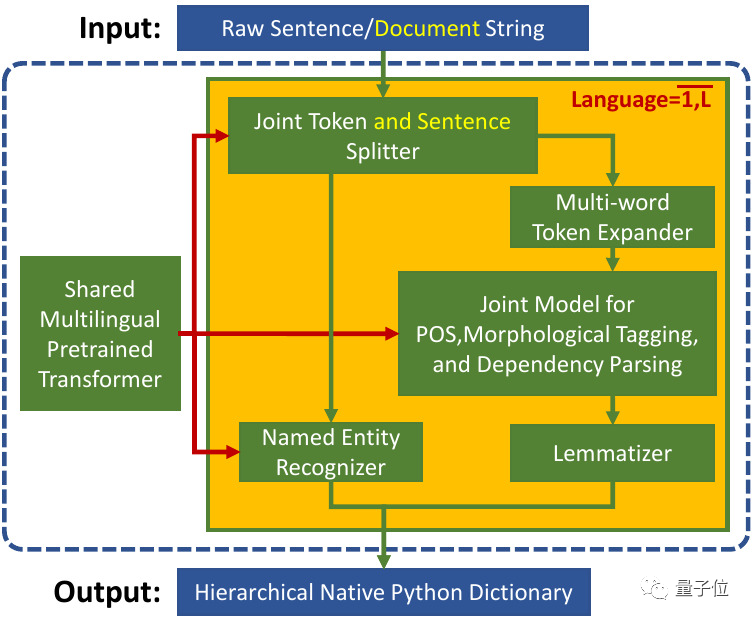
然后為每種語(yǔ)言創(chuàng)建了一組適配器(Adapters)作為傳統(tǒng)的預(yù)訓(xùn)練模型“微調(diào)(Fine-tuning)”方法的替代,并對(duì)不同的NLP任務(wù)設(shè)置權(quán)重。
在訓(xùn)練中,共享的預(yù)訓(xùn)練Transformer是固定的,只有適配器和任務(wù)特定權(quán)重被更新。
在推理時(shí),根據(jù)輸入文本的語(yǔ)言和當(dāng)前的活動(dòng)組件,尋找相應(yīng)的適配器和特定任務(wù)權(quán)重。
這種機(jī)制不僅解決了內(nèi)存問(wèn)題,還大大縮短了訓(xùn)練時(shí)間。
Trankit團(tuán)隊(duì)在實(shí)驗(yàn)中對(duì)比了另外兩種實(shí)現(xiàn)方法。
一種是把所有語(yǔ)言的數(shù)據(jù)集中到一起訓(xùn)練一個(gè)巨大的Pipeline。另一種是使用Trankit的方法但把適配器去掉。

在各項(xiàng)NLP任務(wù)中,Trankit這種“即插即用”的適配器方法表現(xiàn)最好。
團(tuán)隊(duì)表示,未來(lái)計(jì)劃通過(guò)研究不同的預(yù)訓(xùn)練Transformer(如mBERT和XLM-Robertalarge)來(lái)改進(jìn)Trankit。
還考慮為更多語(yǔ)言提供實(shí)體識(shí)別,以及支持更多的NLP任務(wù)。
Github倉(cāng)庫(kù):
https://github.com/nlp-uoregon/trankit
在線Demo:
http://nlp.uoregon.edu/trankit
相關(guān)論文:
https://arxiv.org/pdf/2101.03289.pdf