













研究表明 GPT-4 模型具備自我糾錯能力,有望推動 AI 代碼進一步商業化
作者:漾仔
研究人員通過研究 GPT-4 表示,當下實際上可以通過“模型的自我糾錯”方式,令模型“反思自身所存在的不足之處”,以提升代碼片段長度、并改善輸出結果的準確度。
7 月 5 日消息,麻省理工學院(MIT)和微軟的研究學者發現,GPT-4 模型具有優秀的代碼自我糾錯能力,而 GPT-3.5 不具有該特性,目前論文已經發布于 ArXiv 中。

▲ 圖源 ArXiv
當下市面上已經涌現出了一批專為代碼而生的 AI 模型,但目前更多只是起到輔助開發者寫代碼的作用,例如IT之家小伙伴們熟悉的微軟 Copilot 助理,這些 AI 模型當下僅能夠生成代碼片段,因此尚不能完全替代人工開發者。
研究人員通過研究 GPT-4 表示,當下實際上可以通過“模型的自我糾錯”方式,令模型“反思自身所存在的不足之處”,以提升代碼片段長度、并改善輸出結果的準確度。
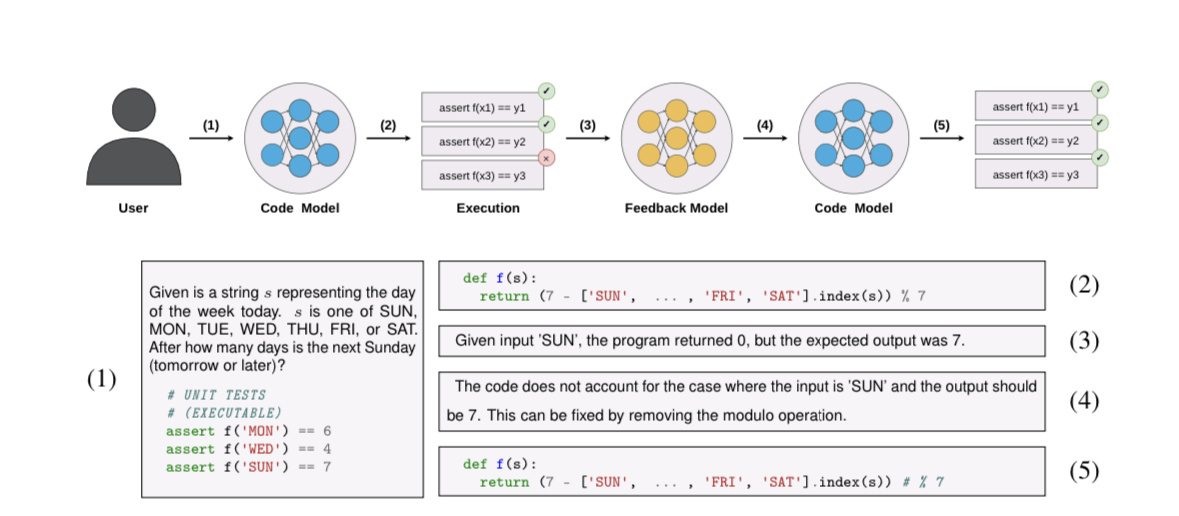
▲ 圖源 ArXiv
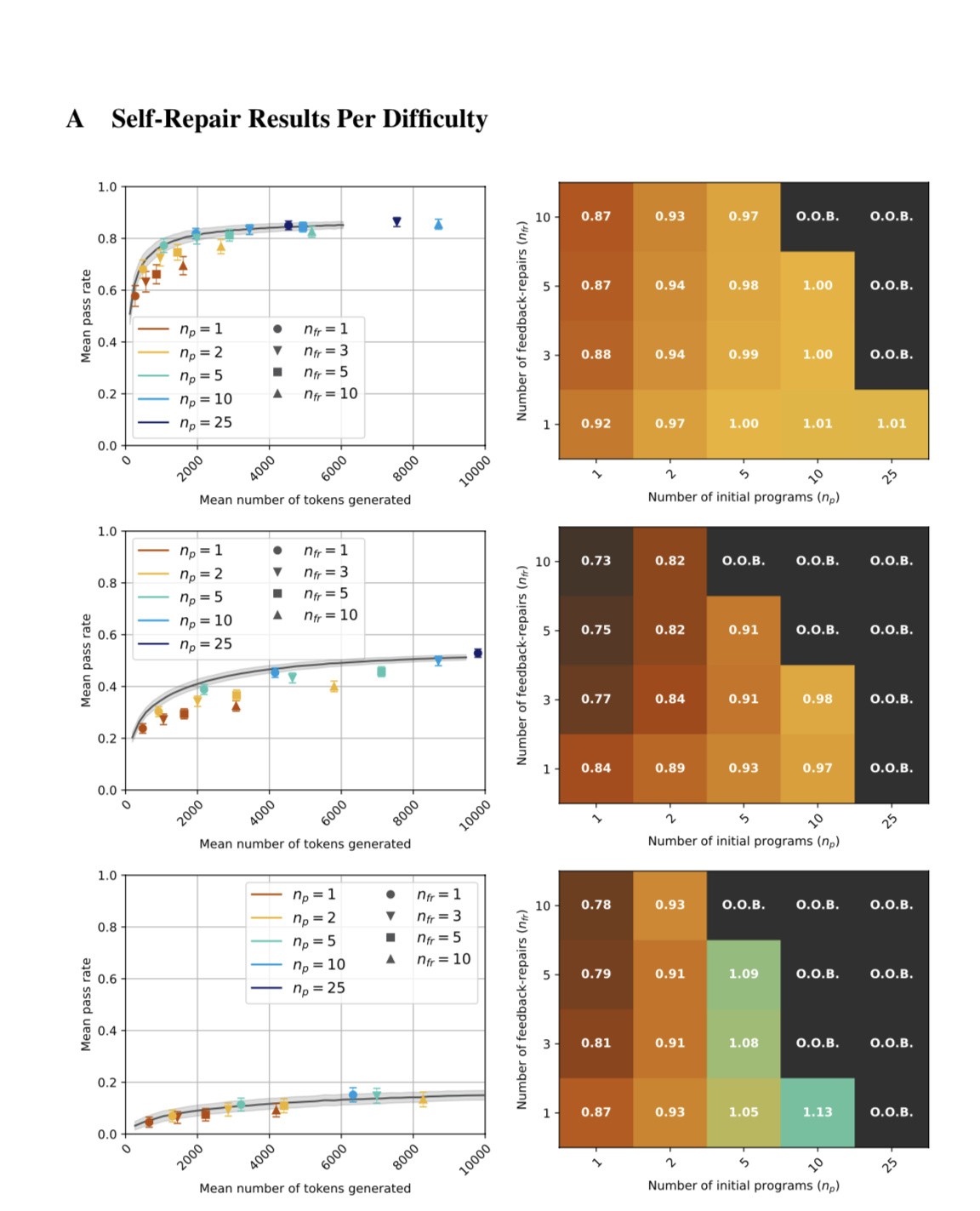
▲ 圖源 ArXiv
來自愛丁堡大學的研究者符堯表示,只有 GPT-4 才具備自我改進的能力,而較弱的 GPT-3.5 則沒有這種特性,這一發現表明大型模型可能具有一種新型能力,即通過一系列用戶反饋令 AI 自我糾錯,最終得到令用戶滿意的結果,這種自我糾錯的能力可能只存在于足夠成熟的 AI 模型中。
在經過自我糾錯后,GPT-4 模型輸出的代碼有 71% 達到研究人員設定的要求,而使用 GPT-4 對 GPT-3.5 所生成的代碼經過糾錯后,這一批代碼的通過率也達到了 54%。
研究人員表示,當下可以將 GPT-4 的自我糾錯方式應用于商業中,在扣除一系列糾錯冗余成本后,依然能夠產生一定的收益。論文總能夠在一定程度上反映行業未來的趨勢,因此有望在今后涌現出一批基于 GPT-4 的代碼生成器。
責任編輯:姜華
來源:
IT之家

















