攜程火車票短信召回算法優(yōu)化實踐
作者簡介
Ryan,攜程算法專家,專注個性化推薦、智能營銷等領(lǐng)域;
小白,攜程算法工程師,研究智能營銷、用戶增長等領(lǐng)域。
一、背景
互聯(lián)網(wǎng)蓬勃發(fā)展的今天是流量為王的時代,但隨著流量紅利逐漸消失,獲客成本的日益增高,用戶留存成為各大互聯(lián)網(wǎng)公司的重點關(guān)注問題,其中流失用戶的召回在當(dāng)今的流量紅海市場中顯得尤為關(guān)鍵,為此,基于大數(shù)據(jù)和機(jī)器學(xué)習(xí)的智能營銷技術(shù)應(yīng)用而生。
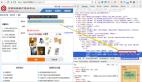
攜程火車票業(yè)務(wù)每周都會有短信營銷活動,旨在通過對近期未下單的老客發(fā)送短信將其召回,促進(jìn)復(fù)購,提升用戶粘性(業(yè)務(wù)流程如圖 1 所示);原有業(yè)務(wù)策略是基于規(guī)則的方式隨機(jī)從滿足條件的用戶池中選擇一部分進(jìn)行短信投放,針對該方法過于粗放、召回效果不佳、短信發(fā)送 ROI 不高的問題,我們分階段提出基于 Response Model 的轉(zhuǎn)化率預(yù)估模型、基于 Uplift Model 的短信敏感度預(yù)估模型,逐一對問題進(jìn)行更科學(xué)的定義、拆解和優(yōu)化。
 圖1 攜程火車票短信召回業(yè)務(wù)流程圖
圖1 攜程火車票短信召回業(yè)務(wù)流程圖
二、問題定義
上述短信召回業(yè)務(wù)需要解決的核心問題可抽象概括如下:
定義:在滿足條件的老客用戶池(假設(shè)用戶規(guī)模為 N )中,通過策略或者模型篩選出 K 個用戶(在短信成本約束下,K 通常小于 N ),對這些用戶發(fā)送短信后,提升整體的轉(zhuǎn)化率和短信發(fā)送 ROI。
三、解決方案
3.1 基于 Response Model 的轉(zhuǎn)化率預(yù)估模型
針對上述問題,在只有基于業(yè)務(wù)策略的短信發(fā)送歷史記錄的情況下,我們首先嘗試通過構(gòu)建一個基于 Response Model 的轉(zhuǎn)化率預(yù)估模型預(yù)測用戶被短信營銷影響后的下單概率,進(jìn)而選擇下單概率高的那部分用戶進(jìn)行短信投放,該方法可形式化描述如下:
V1
目標(biāo):在 N 個用戶中尋找 K 個短信投放后下單概率最高的用戶。
方法:根據(jù)歷史短信發(fā)送記錄構(gòu)建短信觸達(dá)后用戶的轉(zhuǎn)化率預(yù)估模型(考慮到樣本規(guī)模以及連續(xù)特征占比較高,我們采用 XGBoost ),對目標(biāo)用戶群進(jìn)行打分,選出前 K 個下單概率最高的用戶(標(biāo)簽定義:發(fā)送短信后,用戶下單則為正樣本,未下單則為負(fù)樣本)。
實驗方案:如圖 2 所示,先將 N 個用戶隨機(jī)等分為兩組 A 和 B。
a. 對照組: 在 A 組中隨機(jī)選擇 K/2 個用戶進(jìn)行短信投放;
b. 實驗組:在 B 組通過轉(zhuǎn)化率預(yù)估模型預(yù)測打分,按分值由高到低篩出前 K/2 個用戶。
評價指標(biāo):離線:AUC,TopK 的召回率;在線:用戶轉(zhuǎn)化率、短信發(fā)送 ROI。
 圖2 v1 實驗方案流程圖
圖2 v1 實驗方案流程圖
該方案實驗后,實驗組相比對照組在上述評價指標(biāo)上均取得大幅提升,但仔細(xì)分析后發(fā)現(xiàn)存在兩個比較明顯的問題:
a. 評價指標(biāo)不合理:轉(zhuǎn)化率預(yù)估模型選擇的用戶相比隨機(jī)選擇的用戶,在下單概率方面具有天然的偏置;
b. 實驗方案不合理:未能排除用戶自然召回因素的影響(部分人群不管是否有營銷活動都會下單),無法量化評估短信營銷的增量效益。
V2
針對上述兩個問題,我們改進(jìn)了實驗方案和評價指標(biāo):
目標(biāo):驗證通過方案 v1 找到的 K 個用戶在短信投放后下單和收益增量是否更高。
方法:構(gòu)建轉(zhuǎn)化率預(yù)估模型,同 v1。
實驗方案:如圖 3 所示,先將 N 個用戶隨機(jī)等分為兩組 A 和 B。
a. 對照組:將 A 組隨機(jī)等分為 A1 和 A2,分別從 A1、A2 中隨機(jī)篩出 K/2 個用戶,前者投放短信,后者不投放短信;
b. 實驗組:將B組隨機(jī)等分為 B1 和 B2,分別從 B1、B2 中通過轉(zhuǎn)化率預(yù)估模型篩出分?jǐn)?shù)最高的前 K/2 個用戶,前者投放短信,后者不投放短信。
評價指標(biāo):離線:Qini Score,AUUC;在線:短信投放人群相比未投放短信人群的增量轉(zhuǎn)化率、短信發(fā)送增量 ROI。

該方法的實驗方案和評價指標(biāo)雖然更加科學(xué)合理,但由于轉(zhuǎn)化率預(yù)估模型的優(yōu)化目標(biāo)和評價指標(biāo)的優(yōu)化方向不一致,該模型無法預(yù)估短信投放的增量效益(未考慮自然轉(zhuǎn)化因素的影響),為此,我們需要針對優(yōu)化目標(biāo)進(jìn)一步構(gòu)建更加符合業(yè)務(wù)場景需要的模型。
3.2 基于 Uplift Model 的短信敏感度預(yù)估模型
為了解決 Response Model 在上述業(yè)務(wù)場景下存在的問題,提升短信投放帶來的增量效益,我們進(jìn)一步構(gòu)建了基于 Uplift Model 的短信敏感度預(yù)估模型。
Uplift Model 是工業(yè)界因果推斷與機(jī)器學(xué)習(xí)結(jié)合最成熟的算法之一,在智能營銷和用戶增長領(lǐng)域中有著廣泛的應(yīng)用,我們先介紹一下用來解釋 Uplift Model 的較為經(jīng)典的營銷人群劃分圖:
 圖4 營銷人群四象限劃分圖
圖4 營銷人群四象限劃分圖
圖中四類人群解釋如下:
a. 營銷敏感人群:營銷活動觸達(dá)(短信、優(yōu)惠券等)則購買,不觸達(dá)則不買;
b. 自然轉(zhuǎn)化人群:不論營銷活動是否觸達(dá)均會購買;
c. 無動于衷人群:不論營銷活動是否觸達(dá)均不會購買;
d. 反感營銷人群:營銷活動不觸達(dá)會購買,觸達(dá)反而不買。
很顯然,智能營銷的目標(biāo)就是盡可能找到圖 4 中的營銷敏感群體,從而最大化營銷活動的增量效益,Uplift Model 就是為此應(yīng)運(yùn)而生。
Uplift Model 是用于估計某種干預(yù)因素(Treatment,以下簡稱T)對個體處理效應(yīng)(Individual Treatment Effect,簡稱 ITE)的一類模型。在上述的業(yè)務(wù)場景中,假設(shè) T=0 代表不發(fā)短信(對應(yīng)人群簡稱 T 組),T=1 代表發(fā)送短信(對應(yīng)人群簡稱 C 組),X 代表用戶特征,Y 代表輸出預(yù)測值,P 代表轉(zhuǎn)化概率,ITE 即為轉(zhuǎn)化概率的增量變化,其可形式化表述如下:`
ITE=P(Y|X=x,T=1)-P(Y|X=x,T=0) (1)
常用的 Uplift Model 有 Meta-learner(S-learner,T-learner,X-learner等[1])和 Tree-based learner(Uplift Tree[2],Causal Forest[3]等)以及 Dnn-based learner(TARNet[4]、CEVAE[5]等),其中 Causal Forest 主要基于 Uplift Tree 通過隨機(jī)森林(Random Forests)進(jìn)行集成學(xué)習(xí),業(yè)界目前較為流行的做法是使用廣義隨機(jī)森林(Generalized Random Forests,GRF[6])。
上述三類 Uplift Model 的特性總結(jié)如下:
模型名稱 | 優(yōu)點 | 缺點 |
Meta-learner | 可擴(kuò)展性強(qiáng),表現(xiàn)較為穩(wěn)定,基礎(chǔ)模型可以直接套用現(xiàn)有分類模型(LR/GBDT/DNN等) | 非直接建模ITE,基礎(chǔ)模型仍是Response Model,模型擬合能力有待提高 |
Tree-based learner | 直接建模ITE,模型擬合能力較強(qiáng) | 工程實現(xiàn)難度較大,對數(shù)據(jù)分布較為敏感,泛化能力不穩(wěn)定 |
Dnn-based learner | 參數(shù)共享,模型結(jié)構(gòu)和損失函數(shù)定義較為靈活,模型擬合能力強(qiáng) | 對訓(xùn)練數(shù)據(jù)量要求較大,否則比較難以發(fā)揮模型擬合能力的優(yōu)勢 |
表1 Uplift Model特性總結(jié)
通過 Uplift Model 我們可以估計短信營銷對用戶的增量效益,根據(jù)增量效益的量化排序,我們即可以篩選出圖 4 所示的營銷敏感人群,實驗方案依然遵循圖 3 所示流程,需要注意的是 Uplift Model 的建模對訓(xùn)練樣本的要求較高,需要服從 CIA ( Conditional Independence Assumption ) 條件獨(dú)立假設(shè),我們可以通過讓 X 與 T 保持相互獨(dú)立滿足此條件。為此,我們在進(jìn)行實驗的同時,會預(yù)留一小部分流量做隨機(jī)化 A/B 實驗,實驗組會隨機(jī)選擇部分用戶發(fā)送短信,對照組隨機(jī)選擇部分用戶不發(fā)送短信,這個實驗,可以為 Uplift Model 建模提供無偏的樣本。
四、實驗結(jié)果
按照圖 3 所示實驗方案,我們分階段做了兩次實驗,第一次是驗證基于 Response Model 的轉(zhuǎn)化率預(yù)估模型是否帶來了短信營銷的增量效益,其線上效果如表 2 所示,可以看出,在我們的業(yè)務(wù)場景中,相比隨機(jī)篩選的人群,短信營銷對轉(zhuǎn)化率高的人群其實具有較強(qiáng)的正向作用,所以這算是一次較為成功的嘗試。

表2 線上實驗結(jié)果:Response Model vs Random
基于 Response Model 的轉(zhuǎn)化率預(yù)估模型經(jīng)過線上實驗驗證,雖然業(yè)務(wù)指標(biāo)提升較為明顯,但基于本文中對短信營銷增量效益的分析,我們決定繼續(xù)進(jìn)行第二階段的實驗評估,離線建模結(jié)果如表 3 所示:
 圖片
圖片
表3 離線評估結(jié)果:Uplift Model vs Response Model
表 3 中主要評估基于 Meta-learner 構(gòu)建的 Uplift Model 相比 Response Model 的離線指標(biāo)提升,對本次實驗我們將基于 Response Model 的轉(zhuǎn)化率預(yù)估模型作為對照版,將基于 Uplift Model 的短信敏感度預(yù)估模型作為實驗版,其中 Uplift Model 為離線評估效果相對較好的 T-learner,線上效果如表 4 所示:
 圖片
圖片
表4 線上實驗結(jié)果:Uplift Model vs Response Model
從表 4 可以看出,Uplift Model 的線上表現(xiàn)效果和離線一致,相比 Response Model 取得了明顯的業(yè)務(wù)指標(biāo)提升,這也驗證了 Uplift Model 確實適用于提升短信營銷的增量效益,有助于挖掘更多的短信營銷敏感人群。
五、探索分析
在進(jìn)行上述兩階段的實驗之后,我們繼續(xù)探索更多 Uplift Model 在我們業(yè)務(wù)場景的適用性,同時也是為了評估當(dāng)前業(yè)務(wù)繼續(xù)進(jìn)行實驗迭代的必要性。
除了 Meta-Learner,我們也選擇了以 GRF 作為代表的 Tree-based learner 和以 TARNet 作為代表 Dnn-based learner 進(jìn)行評估對比,同時,考慮到 S-learner 中 T 作為特征加入到模型訓(xùn)練過程中有可能被眾多用戶特征稀釋,我們對用戶特征采用 PCA 進(jìn)行降維后再將 T 作為特征用 S-learner 進(jìn)行訓(xùn)練和評估(即表 5 中 PCA+S-learner),表中測試集 v1 我們繼續(xù)使用和表 3 一致的測試集。
各模型的離線評估效果如下:
 圖片
圖片
表5 Uplift Model 離線指標(biāo)評估結(jié)果(測試集 v1)

圖5 Uplift Model 離線評估結(jié)果-Qini Curve(測試集 v1)
為了更加清晰地看出 Uplift Model 的增量效益,我們也繪制了 Qini Curve,如圖 5 所示(圖中橫坐標(biāo)代表按 ITE 估計值排序后的樣本占比,縱坐標(biāo)代表對應(yīng)人群實際的轉(zhuǎn)化增量,曲線下的面積越大,代表模型效果越好):
從表 5 和圖 5 可以看出,TARNet、GRF、PCA+S-learner 的表現(xiàn)均較為突出,但考慮到這些模型容易受整體數(shù)據(jù)分布的影響,為了評估各個模型的泛化能力,我們額外選擇了線上受到疫情影響日期較為靠后的測試數(shù)據(jù)集 v2,其離線評估效果如圖表 6 和圖 6 所示:

表6 Uplift Model 離線指標(biāo)評估結(jié)果(測試集 v2)

圖6 Uplift Model 離線評估結(jié)果-Qini Curve(測試集 v2)
從表 6 和圖 6 可以看出,PCA+S-learner,GRF,TARNet 等模型均容易受到數(shù)據(jù)分布變化的影響,這些模型還需要進(jìn)一步優(yōu)化模型結(jié)構(gòu)提升泛化能力以增強(qiáng)適應(yīng)數(shù)據(jù)分布變化的魯棒性,這也是我們后續(xù)探索的方向之一;其中 T-learner 表現(xiàn)比較穩(wěn)定,適應(yīng)數(shù)據(jù)分布變化的能力也較強(qiáng),更加適用于我們當(dāng)前的業(yè)務(wù)場景。
六、總結(jié)與展望
攜程火車票短信召回業(yè)務(wù)是一個比較典型的智能營銷場景,短信召回算法的優(yōu)化過程和結(jié)論總結(jié)如下:
a. 針對智能營銷類場景,直接估計干預(yù)因子增量效應(yīng)的 Uplift Model 相比傳統(tǒng)的 Response Model 具有更強(qiáng)的適用性;
b. 智能營銷類場景需要設(shè)計科學(xué)合理的實驗方案來驗證干預(yù)因素的增量效應(yīng),最好預(yù)留部分流量進(jìn)行隨機(jī)化實驗從而為 Uplift Model 的訓(xùn)練和評估提供無偏的樣本;
c. Uplift Model 的實現(xiàn)方式有很多種(Meta-learner、 Tree-based learner、 Dnn-based learner等),其中 T-learner 在我們的業(yè)務(wù)場景中效果相對穩(wěn)定,較為適用,但不一定適用于其他場景,需要根據(jù)實際情況進(jìn)行分析和評測;
d. 我們對 Uplift Model 探索還有待進(jìn)一步深化,比如應(yīng)對連續(xù)以及多元干預(yù)因子的處理、優(yōu)化模型結(jié)構(gòu)提升泛化能力和解決多目標(biāo)跨域聯(lián)合建模等。