隨著ChatGPT的發布,人們越來越難以回避利用機器學習的相關技術。從消息應用程序上的文本預測到智能門鈴上的面部識別,機器學習(ML)幾乎可以在我們今天使用的每一項技術中找到。
如何將機器學習技術交付給消費者是企業在開發過程中必須解決的眾多挑戰之一。機器學習產品的部署策略對產品的最終用戶有重大影響。這可能意味著,iPhone上的Siri和網絡瀏覽器中的ChatGPT之間將存在重大差異。
除了ChatGPT流暢的用戶界面和過于自信的聊天對話之外,還隱藏了部署大型語言機器學習模型所需的復雜機制。ChatGPT建立在一個高度可擴展的框架上,該框架旨在當模型呈指數級被應用期間提供和支持該模型。事實上,實際的機器學習模型只占整個項目的一小部分。此類項目往往是跨學科的,需要數據工程、數據科學和軟件開發方面的專業知識。因此,簡化模型部署過程的框架在向生產交付模型方面變得越來越重要,因為這將有助于企業節省時間和金錢。
如果沒有適當的運營框架來支持和管理ML模型,企業在試圖擴大生產中機器學習模型的數量時往往會遇到瓶頸。
雖然在高度飽和的MLOps工具包市場上,沒有一個工具能成為明顯的贏家,但KServe正成為一個越來越受歡迎的工具,幫助企業滿足機器學習模型的可擴展性要求。
一、什么是KServe?
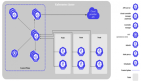
KServe是一個用于Kubernetes的高度可擴展的機器學習部署工具包。它是一個構建在Kubernetes之上的編排工具,并利用了另外兩個開源項目,Knative-Serving和Istio;稍后將對此進行詳細介紹。
 圖片
圖片
圖片來源于KServe(https://kserve.github.io/website/0.10/)
KServe通過將部署統一到一個資源定義中,大大簡化了機器學習模型在Kubernetes集群中的部署過程。它使機器學習部署成為任何機器學習項目的一部分,易于學習,并最終降低了進入壁壘。因此,使用KServe部署的模型比使用需要Flask或FastAPI服務的傳統Kubernetes部署的模型更容易維護。
借助于KServe,在使用HTTPs協議通過因特網公開模型之前,不需要將模型封裝在FastAPI或Flask應用程序中。KServe內置的功能基本上復制了這個過程,但不需要維護API端點、配置pod副本或配置Kubernetes上的內部路由網絡。我們所要做的就是將KServe指向您的模型,然后由它來處理其余的部分。
除了簡化部署過程之外,KServe還提供了許多功能,包括金絲雀部署(譯者注:這是一種流行的持續部署策略,其中將一小部分機隊更新為應用程序的新版本)、推理自動縮放和請求批處理。這些功能將不會被討論,因為它超出了本文的范圍;然而,本文有望為進一步探索相關知識的理解奠定基礎。
首先,我們來談談KServe附帶的兩個關鍵技術,Istio和Knative。
1、Istio
如果沒有Istio,KServe帶來的許多功能將很難實現。Istio是一個服務網格,用于擴展部署在Kubernetes中的應用程序。它是一個專用的基礎設施層,增加了可觀察性、流量管理和安全性等功能。對于那些熟悉Kubernetes的人來說,Istio將取代通常在Kubernete集群中找到的標準入口定義。
管理流量和維護可觀察性的復雜性只會隨著基于Kubernetes的系統的擴展而增加。Istio最好的功能之一是集中控制服務級別的通信。這使開發人員能夠對服務之間的通信進行更大的控制和透明度。
有了Istio,開發人員不需要專門開發那些需要能夠處理流量身份驗證或授權的應用程序。最終,Istio有助于降低已部署應用程序的復雜性,并使開發人員能夠專注于應用程序的重要組件。
通過利用Istio的網絡功能,KServe能夠帶來包括金絲雀部署、推理圖和自定義轉換器在內的功能。
2、KNative
另一方面,KNative是一個開源的企業級解決方案,用于構建無服務器和事件驅動的應用程序。Knative構建在Istio之上,帶來了類似于AWS Lambdas和Azure Functions提供的無服務器代碼執行功能。Knative是一個與平臺無關的解決方案,用于在Kubernetes中運行無服務器部署。
KNative最好的功能之一是可擴展到零的功能,當沒有需求時,該功能會自動縮減部署。這是KServe擴大或縮小ML模型部署能力的一個關鍵組成部分,也是最大限度地提高資源利用率和節省成本的一個組成部分。
3、我應該使用KServe嗎?
與許多其他工具一樣,KServe不是一個適合您的企業所要求的一刀切式的解決方案。它的入門成本很高,因為需要用戶具備一些使用Kubernetes的經驗。如果你剛開始使用Kubernetes,網上有很多資源,我強烈建議你在Youtube上查看DevOps(https://www.youtube.com/channel/UCFe9-V_rN9nLqVNiI8Yof3w)之類的資源。盡管如此,即使不深入了解Kubernetes,也可以學習使用KServe。
在已經利用Kubernetes的企業中,KServe將是理想的選擇,因為這些企業在使用Kubernete方面已經擁有現有的知識。它還可能適合那些希望放棄或補充SageMaker或Azure機器學習等托管服務的組織,以便對您的模型部署過程有更大的控制權。所有權的增加可以顯著降低成本,并提高可配置性,以滿足項目的特定要求。
盡管如此,正確的云基礎設施決策將取決于具體情況,因為不同公司的基礎設施要求不同。
二、預備知識
本文接下來將帶您了解設置KServe所需的步驟。您將了解安裝KServe并為您的第一個模型提供服務的步驟。
在繼續之前,需要滿足幾個先決條件。您將需要準備以下內容:
- lKuectl(https://kubernetes.io/docs/tasks/tools/)安裝
- lHelm(https://helm.sh/docs/intro/install/)安裝
- lKuectx(https://github.com/ahmetb/kubectx)安裝(可選)
1、Kubernetes集群
在本教程中,我建議使用Kind工具(https://kind.sigs.k8s.io/)對Kubernetes集群進行實驗。它是一個運行本地Kubernetes集群的工具,無需啟動云資源。此外,如果您在多個集群中工作,我強烈推薦把Kuectx作為一種工具,它能夠幫助您在Kubernetes上下文之間輕松切換。
但是,在運行生產工作負載時,您需要訪問功能齊全的Kubernetes集群來配置DNS和HTTPS。
使用Kind工具部署Kubernetes集群的命令如下:
kind create cluster --name kserve-demo然后,您可以使用以下命令切換到正確的Kubernetes上下文:
kubectx kind-kserve-demo2、安裝
以下步驟將安裝Istio v1.16、Knative Serving v1.7.2和KServe v0.10.0。這些版本最適合本教程,因為Knative v1.8以后的版本將需要對入口進行DNS配置,這增加了一層超出目前范圍的復雜性。
1)安裝Istio:
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.16.0 TARGET_ARCH=x86_64 sh -istioctl install --set profile=default -y2)安裝KNative Serving:
#安裝Knative Serving組件
export KNATIVE_VERSION="v1.7.2"
kubectl apply -f https://github.com/knative/serving/releases/download/knative-$KNATIVE_VERSION/serving-crds.yaml
kubectl apply -f https://github.com/knative/serving/releases/download/knative-$KNATIVE_VERSION/serving-core.yaml
#安裝istio-controller for knative
kubectl apply -f https://github.com/knative/net-istio/releases/download/knative-v1.7.0/net-istio.yaml3)安裝證書管理器。需要證書管理器來管理HTTPs流量的有效證書。
helm repo add jetstack https://charts.jetstack.io
helm repo update
helm install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --version v1.11.0 --set installCRDs=true4)為模型創建一個命名空間。
kubectl create namespace kserve5)克隆KServe存儲庫。
git clone git@github.com:kserve/kserve.git6)將KServe定制資源定義和KServe運行時安裝到集群中的模型命名空間中。
cd kserve
helm install kserve-crd charts/kserve-crd -n kserve
helm install kserve-resources charts/kserve-resources -n kserve我們現在已經在集群上安裝了KServe。接下來,讓我們開始部署吧!
三、第一個推理服務
為了確保部署順利進行,讓我們部署一個演示推理服務。您可以在鏈接https://kserve.github.io/website/0.10/get_started/first_isvc/#1-create-a-namespace處找到部署的完整源代碼。
kubectl apply -n kserve -f - <<EOF
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
spec:
predictor:
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model"
EOF上面的yaml資源定義部署了一個測試推理服務,該服務來源于使用SciKit學習庫訓練的公開可用模型。KServe支持許多不同風格的機器學習庫(https://kserve.github.io/website/0.10/modelserving/v1beta1/serving_runtime/)。
其中包括MLFlow、PyTorch或XGBoost模型;每次發布時都會添加更多的類似支持。如果這些現成的庫都不能滿足您的要求,KServe還支持自定義預測器(https://kserve.github.io/website/0.10/modelserving/v1beta1/custom/custom_model/)。
注意,您可以通過獲取命名空間中的可用pod數量來監控當前部署的狀態。
kubectl get pods -n kserve 圖片
圖片
如果在部署中遇到問題,請使用以下方法進行調試:
kubectl describe pod-n kserve我們還可以通過以下方式檢查推理服務部署的狀態:
kubectl get isvc -A 圖片
圖片
如果推理服務被標記為true,我們就可以執行我們的第一個預測了。
四、執行預測
為了進行預測,我們需要確定我們的Kubernetes集群是否在支持外部負載均衡器的環境中運行。
kubectl get svc istio-ingressgateway -n istio-system1、Kind群集
值得注意的是,使用Kind部署的集群不支持外部負載均衡器;因此,您將擁有一個與下面類似的入口網關。
 圖片
圖片
Kind外部負載均衡器(圖片由作者提供)
在這種情況下,我們必須轉發istio-ingressgateway,這將允許我們通過localhost訪問它。
端口將istio-ingress網關服務轉發到本地主機上的端口8080,使用如下命令:
kubectl port-forward -n istio-system service/istio-ingressgateway 8080:80然后設置入口主機和端口:
export INGRESS_HOST=localhost
export INGRESS_PORT=80802、Kubernetes集群
如果外部IP有效且未顯示<pending>,那么我們可以通過IP地址的互聯網發送推理請求。
 圖片
圖片
入口網關IP地址(圖片由作者提供)
將入口主機和端口設置為:
export INGRESS_HOST=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].port}')3、進行推理
為推理請求準備一個輸入請求json文件。
cat <"./iris-input.json"
{
"instances": [
[6.8, 2.8, 4.8, 1.4],
[6.0, 3.4, 4.5, 1.6]
]
}
EOF然后用curl命令進行推理:
SERVICE_HOSTNAME=$(kubectl get inferenceservice sklearn-iris -n kserve -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v -H "Host: ${SERVICE_HOSTNAME}" "http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/sklearn-iris:predict" -d @./iris-input.json該請求將通過istio-ingress網關發送到KServe部署。如果一切正常,我們將從推理服務中獲得一個json回復,其中每個實例的預測值為[1,1]。
 圖片
圖片
五、零擴展
通過利用KNative的功能,KServe支持零擴展功能。該功能通過將未使用的pod擴展為零,從而有效地管理集群中有限的資源。將功能擴展到零允許創建一個響應請求的反應式系統,而不是一個始終處于運行狀態的系統。這將有助于在集群中部署比傳統部署配置更多的模型。
然而,請注意,對于已經縮小擴展的pod副本,存在一個冷啟動“處罰”。“處罰”程度將根據圖像/模型的大小和可用的集群資源而變化。如果集群需要擴展額外的節點,冷啟動可能需要5分鐘,如果模型已經緩存在節點上,則需要10秒。
讓我們修改現有的scikit-learn推理服務,并通過定義minReplicas:0來啟用零擴展(scale to zero)功能。
kubectl apply -n kserve -f - < <EOF< span> </EOF<>
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "sklearn-iris"
spec:
predictor:
minReplicas: 0
model:
modelFormat:
name: sklearn
storageUri: "gs://kfserving-examples/models/sklearn/1.0/model"
EOF通過將minReplicas設置為0,這將命令Knative在沒有HTTP流量時將推理服務縮減為零。你會注意到,30秒后,Sklearn鳶尾花模型的pod副本將縮小。
kubectl get pods -n kserve Sklearn鳶尾花預測因子降到零
Sklearn鳶尾花預測因子降到零
若要重新初始化推理服務,請向同一個端點發送預測請求。
SERVICE_HOSTNAME=$(kubectl get inferenceservice sklearn-iris -n kserve -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v -H "Host: ${SERVICE_HOSTNAME}" "http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/sklearn-iris:predict" -d @./iris-input.json 圖片
圖片
這將從冷啟動觸發pod副本初始化并返回預測。
六、結論
總體來看,KServe能夠簡化機器學習部署過程,縮短生產路徑。當與Knative和Istio相結合時,KServe還有一個額外的好處,那就是高度可定制,并帶來了許多可以輕松與托管云解決方案相媲美的功能。
當然,在內部遷移模型部署過程存在其固有的復雜性。然而,平臺所有權的增加將在滿足項目特定要求方面提供更大的靈活性。憑借正確的Kubernetes專業知識,KServe可以成為一個強大的工具,使企業能夠輕松地在任何云提供商中擴展其機器學習部署,以滿足日益增長的需求。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。