













基于機器學(xué)習(xí)的web異常檢測
Web防火墻是信息安全的第一道防線。隨著網(wǎng)絡(luò)技術(shù)的快速更新,新的黑客技術(shù)也層出不窮,為傳統(tǒng)規(guī)則防火墻帶來了挑戰(zhàn)。傳統(tǒng)web入侵檢測技術(shù)通過維護規(guī)則集對入侵訪問進行攔截。一方面,硬規(guī)則在靈活的黑客面前,很容易被繞過,且基于以往知識的規(guī)則集難以應(yīng)對0day攻擊;另一方面,攻防對抗水漲船高,防守方規(guī)則的構(gòu)造和維護門檻高、成本大。
基于機器學(xué)習(xí)技術(shù)的新一代web入侵檢測技術(shù)有望彌補傳統(tǒng)規(guī)則集方法的不足,為web對抗的防守端帶來新的發(fā)展和突破。機器學(xué)習(xí)方法能夠基于大量數(shù)據(jù)進行自動化學(xué)習(xí)和訓(xùn)練,已經(jīng)在圖像、語音、自然語言處理等方面廣泛應(yīng)用。然而,機器學(xué)習(xí)應(yīng)用于web入侵檢測也存在挑戰(zhàn),其中最大的困難就是標(biāo)簽數(shù)據(jù)的缺乏。盡管有大量的正常訪問流量數(shù)據(jù),但web入侵樣本稀少,且變化多樣,對模型的學(xué)習(xí)和訓(xùn)練造成困難。因此,目前大多數(shù)web入侵檢測都是基于無監(jiān)督的方法,針對大量正常日志建立模型(Profile),而與正常流量不符的則被識別為異常。這個思路與攔截規(guī)則的構(gòu)造恰恰相反。攔截規(guī)則意在識別入侵行為,因而需要在對抗中“隨機應(yīng)變”;而基于profile的方法旨在建模正常流量,在對抗中“以不變應(yīng)萬變”,且更難被繞過。
習(xí)的web異常檢測")
基于異常檢測的web入侵識別,訓(xùn)練階段通常需要針對每個url,基于大量正常樣本,抽象出能夠描述樣本集的統(tǒng)計學(xué)或機器學(xué)習(xí)模型(Profile)。檢測階段,通過判斷web訪問是否與Profile相符,來識別異常。

一、對于Profile的建立,主要有以下幾種思路:
1. 基于統(tǒng)計學(xué)習(xí)模型
基于統(tǒng)計學(xué)習(xí)的web異常檢測,通常需要對正常流量進行數(shù)值化的特征提取和分析。特征例如,URL參數(shù)個數(shù)、參數(shù)值長度的均值和方差、參數(shù)字符分布、URL的訪問頻率等等。接著,通過對大量樣本進行特征分布統(tǒng)計,建立數(shù)學(xué)模型,進而通過統(tǒng)計學(xué)方法進行異常檢測。
2. 基于文本分析的機器學(xué)習(xí)模型
Web異常檢測歸根結(jié)底還是基于日志文本的分析,因而可以借鑒NLP中的一些方法思路,進行文本分析建模。這其中,比較成功的是基于隱馬爾科夫模型(HMM)的參數(shù)值異常檢測。
3. 基于單分類模型
由于web入侵黑樣本稀少,傳統(tǒng)監(jiān)督學(xué)習(xí)方法難以訓(xùn)練。基于白樣本的異常檢測,可以通過非監(jiān)督或單分類模型進行樣本學(xué)習(xí),構(gòu)造能夠充分表達白樣本的最小模型作為Profile,實現(xiàn)異常檢測。
4. 基于聚類模型
通常正常流量是大量重復(fù)性存在的,而入侵行為則極為稀少。因此,通過web訪問的聚類分析,可以識別大量正常行為之外,小搓的異常行為,進行入侵發(fā)現(xiàn)。

二、基于統(tǒng)計學(xué)習(xí)模型
基于統(tǒng)計學(xué)習(xí)模型的方法,首先要對數(shù)據(jù)建立特征集,然后對每個特征進行統(tǒng)計建模。對于測試樣本,首先計算每個特征的異常程度,再通過模型對異常值進行融合打分,作為最終異常檢測判斷依據(jù)。
這里以斯坦福大學(xué)CS259D: Data Mining for CyberSecurity課程[1]為例,介紹一些行之有效的特征和異常檢測方法。
特征1:參數(shù)值value長度
模型:長度值分布,均值μ,方差σ2,利用切比雪夫不等式計算異常值p
值value長度")
特征2:字符分布
模型:對字符分布建立模型,通過卡方檢驗計算異常值p

特征3:參數(shù)缺失
模型:建立參數(shù)表,通過查表檢測參數(shù)錯誤或缺失
特征4:參數(shù)順序
模型:參數(shù)順序有向圖,判斷是否有違規(guī)順序關(guān)系
順序")
特征5:訪問頻率(單ip的訪問頻率,總訪問頻率)
模型:時段內(nèi)訪問頻率分布,均值μ,方差σ2,利用切比雪夫不等式計算異常值p
特征6:訪問時間間隔
模型:間隔時間分布,通過卡方檢驗計算異常值p
最終,通過異常打分模型將多個特征異常值融合,得到最終異常打分:
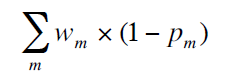
三、基于文本分析的機器學(xué)習(xí)模型
URL參數(shù)輸入的背后,是后臺代碼的解析,通常來說,每個參數(shù)的取值都有一個范圍,其允許的輸入也具有一定模式。比如下面這個例子:
習(xí)模型")
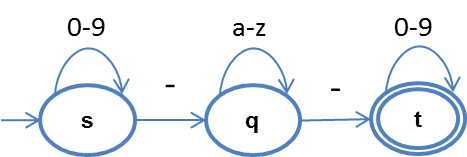
例子中,綠色的代表正常流量,紅色的代表異常流量。由于異常流量和正常流量在參數(shù)、取值長度、字符分布上都很相似,基于上述特征統(tǒng)計的方式難以識別。進一步看,正常流量盡管每個都不相同,但有共同的模式,而異常流量并不符合。在這個例子中,符合取值的樣本模式為:數(shù)字_字母_數(shù)字,我們可以用一個狀態(tài)機來表達合法的取值范圍:
對文本序列模式的建模,相比較數(shù)值特征而言,更加準(zhǔn)確可靠。其中,比較成功的應(yīng)用是基于隱馬爾科夫模型(HMM)的序列建模,這里僅做簡單的介紹,具體請參考推薦文章[2]。
基于HMM的狀態(tài)序列建模,首先將原始數(shù)據(jù)轉(zhuǎn)化為狀態(tài)表示,比如數(shù)字用N表示狀態(tài),字母用a表示狀態(tài),其他字符保持不變。這一步也可以看做是原始數(shù)據(jù)的歸一化(Normalization),其結(jié)果使得原始數(shù)據(jù)的狀態(tài)空間被有效壓縮,正常樣本間的差距也進一步減小。
序列建模")
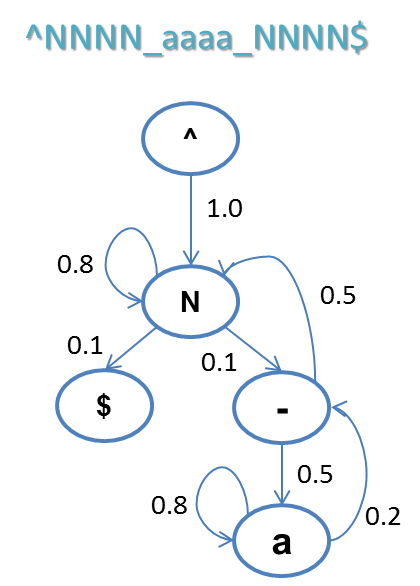
緊接著,對于每個狀態(tài),統(tǒng)計之后一個狀態(tài)的概率分布。例如,下圖就是一個可能得到的結(jié)果。“^”代表開始符號,由于白樣本中都是數(shù)字開頭,起始符號(狀態(tài)^)轉(zhuǎn)移到數(shù)字(狀態(tài)N)的概率是1;接下來,數(shù)字(狀態(tài)N)的下一個狀態(tài),有0.8的概率還是數(shù)字(狀態(tài)N),有0.1的概率轉(zhuǎn)移到下劃線,有0.1的概率轉(zhuǎn)移到結(jié)束符(狀態(tài)$),以此類推。
利用這個狀態(tài)轉(zhuǎn)移模型,我們就可以判斷一個輸入序列是否符合白樣本的模式:

正常樣本的狀態(tài)序列出現(xiàn)概率要高于異常樣本,通過合適的閾值可以進行異常識別。
四、基于單分類模型
在二分類問題中,由于我們只有大量白樣本,可以考慮通過單分類模型,學(xué)習(xí)單類樣本的最小邊界,邊界之外的則識別為異常。

這類方法中,比較成功的應(yīng)用是單類支持向量機(one-class SVM)。這里簡單介紹該類方法的一個成功案例McPAD的思路,具體方法關(guān)注文章[3]。
McPAD系統(tǒng)首先通過N-Gram將文本數(shù)據(jù)向量化,對于下面的例子,
首先通過N-Gram將文本數(shù)據(jù)向量化")
首先通過長度為N的滑動窗口將文本分割為N-Gram序列,例子中,N取2,窗口滑動步長為1,可以得到如下N-Gram序列。

下一步要把N-Gram序列轉(zhuǎn)化成向量。假設(shè)共有256種不同的字符,那么會得到256*256種2-GRAM的組合(如aa, ab, ac … )。我們可以用一個256*256長的向量,每一位one-hot的表示(有則置1,沒有則置0)文本中是否出現(xiàn)了該2-GRAM。由此得到一個256*256長的0/1向量。進一步,對于每個出現(xiàn)的2-Gram,我們用這個2-Gram在文本中出現(xiàn)的頻率來替代單調(diào)的“1”,以表示更多的信息:
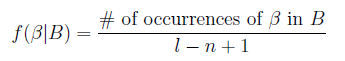
至此,每個文本都可以通過一個256*256長的向量表示。

現(xiàn)在我們得到了訓(xùn)練樣本的256*256向量集,現(xiàn)在需要通過單分類SVM去找到最小邊界。然而問題在于,樣本的維度太高,會對訓(xùn)練造成困難。我們還需要再解決一個問題:如何縮減特征維度。特征維度約減有很多成熟的方法,McPAD系統(tǒng)中對特征進行了聚類達到降維目的。

上左矩陣中黑色表示0,紅色表示非零。矩陣的每一行,代表一個輸入文本(sample)中具有哪些2-Gram。如果換一個角度來看這個矩陣,則每一列代表一個2-Gram有哪些sample中存在,由此,每個2-Gram也能通過sample的向量表達。從這個角度我們可以獲得2-Gram的相關(guān)性。對于2-Gram的向量進行聚類,指定的類別數(shù)K即為約減后的特征維數(shù)。約減后的特征向量,再投入單類SVM進行進一步模型訓(xùn)練。
再進一步,McPAD采用線性特征約減加單分類SVM的方法解決白模型訓(xùn)練的過程,其實也可以被深度學(xué)習(xí)中的深度自編碼模型替代,進行非線性特征約減。同時,自編碼模型的訓(xùn)練過程本身就是學(xué)習(xí)訓(xùn)練樣本的壓縮表達,通過給定輸入的重建誤差,就可以判斷輸入樣本是否與模型相符。
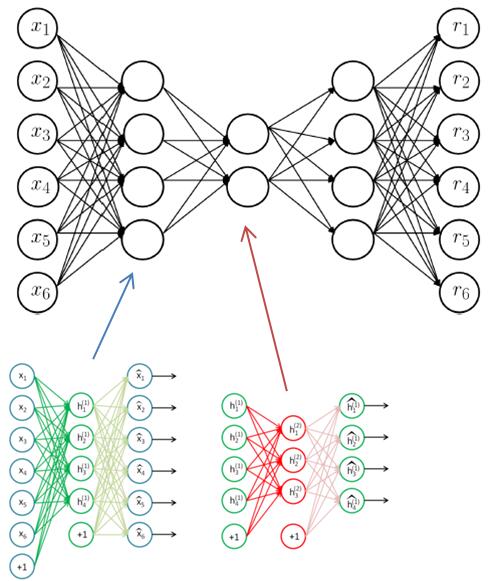
我們還是沿用McPAD通過2-Gram實現(xiàn)文本向量化的方法,直接將向量輸入到深度自編碼模型,進行訓(xùn)練。測試階段,通過計算重建誤差作為異常檢測的標(biāo)準(zhǔn)。
文本向量化的方法")
基于這樣的框架,異常檢測的基本流程如下,一個更加完善的框架可以參見文獻[4]。

本文管中窺豹式的介紹了機器學(xué)習(xí)用于web異常檢測的幾個思路。web流量異常檢測只是web入侵檢測中的一環(huán),用于從海量日志中撈出少量的“可疑”行為,但是這個“少量”還是存在大量誤報,只能用于檢測,還遠遠不能直接用于WAF直接攔截。一個完備的web入侵檢測系統(tǒng),還需要在此基礎(chǔ)上進行入侵行為識別,以及告警降誤報等環(huán)節(jié)。






















