













機器人ChatGPT來了:大模型進現實世界,DeepMind重量級突破
我們知道,在掌握了網絡中的語言和圖像之后,大模型終究要走進現實世界,「具身智能」應該是下一步發展的方向。
把大模型接入機器人,用簡單的自然語言代替復雜指令形成具體行動規劃,且無需額外數據和訓練,這個愿景看起來很美好,但似乎也有些遙遠。畢竟機器人領域,難是出了名的。
然而 AI 的進化速度比我們想象得還要快。
本周五,谷歌 DeepMind 宣布推出 RT-2:全球第一個控制機器人的視覺 - 語言 - 動作(VLA)模型。
現在不再用復雜指令,機器人也能直接像 ChatGPT 一樣操縱了。
 圖片
圖片

RT-2 到達了怎樣的智能化程度?DeepMind 研究人員用機械臂展示了一下,跟 AI 說選擇「已滅絕的動物」,手臂伸出,爪子張開落下,它抓住了恐龍玩偶。
 圖片
圖片

在此之前,機器人無法可靠地理解它們從未見過的物體,更無法做把「滅絕動物」到「塑料恐龍玩偶」聯系起來這種有關推理的事。
跟機器人說,把可樂罐給泰勒?斯威夫特:

看得出來這個機器人是真粉絲,對人類來說是個好消息。
ChatGPT 等大語言模型的發展,正在為機器人領域掀起一場革命,谷歌把最先進的語言模型安在機器人身上,讓它們終于擁有了一顆人工大腦。
在 DeepMind 在最新提交的一篇論文中研究人員表示,RT-2 模型基于網絡和機器人數據進行訓練,利用了 Bard 等大型語言模型的研究進展,并將其與機器人數據相結合,新模型還可以理解英語以外的指令。

谷歌高管稱,RT-2 是機器人制造和編程方式的重大飛躍。「由于這一變化,我們不得不重新考慮我們的整個研究規劃了,」谷歌 DeepMind 機器人技術主管 Vincent Vanhoucke 表示。「之前所做的很多事情都完全變成無用功了。」
RT-2 是如何實現的?
DeepMind 這個 RT-2 拆開了讀就是 Robotic Transformer —— 機器人的 transformer 模型。
想要讓機器人能像科幻電影里一樣聽懂人話,展現生存能力,并不是件容易的事。相對于虛擬環境,真實的物理世界復雜而無序,機器人通常需要復雜的指令才能為人類做一些簡單的事情。相反,人類本能地知道該怎么做。
此前,訓練機器人需要很長時間,研究人員必須為不同任務單獨建立解決方案,而借助 RT-2 的強大功能,機器人可以自己分析更多信息,自行推斷下一步該做什么。
RT-2 建立在視覺 - 語言模型(VLM)的基礎上,又創造了一種新的概念:視覺 - 語言 - 動作(VLA)模型,它可以從網絡和機器人數據中進行學習,并將這些知識轉化為機器人可以控制的通用指令。該模型甚至能夠使用思維鏈提示,比如哪種飲料最適合疲憊的人 (能量飲料)。
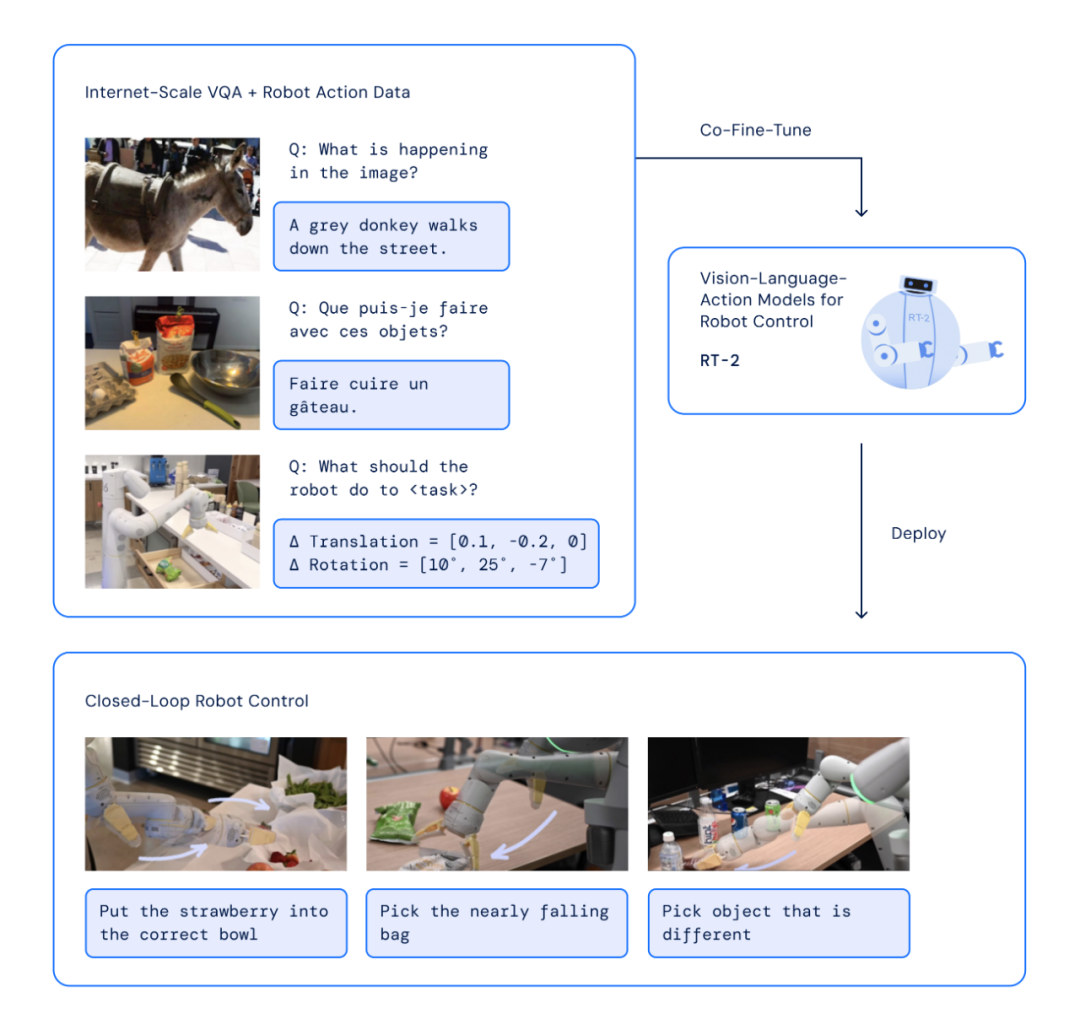
RT-2 架構及訓練過程
其實早在去年,谷歌就曾推出過 RT-1 版本的機器人,只需要一個單一的預訓練模型,RT-1 就能從不同的感官輸入(如視覺、文本等)中生成指令,從而執行多種任務。
作為預訓練模型,要想構建得好自然需要大量用于自監督學習的數據。RT-2 建立在 RT-1 的基礎上,并且使用了 RT-1 的演示數據,這些數據是由 13 個機器人在辦公室、廚房環境中收集的,歷時 17 個月。
DeepMind 造出了 VLA 模型
前面我們已經提到 RT-2 建立在 VLM 基礎之上,其中 VLMs 模型已經在 Web 規模的數據上訓練完成,可用來執行諸如視覺問答、圖像字幕生成或物體識別等任務。此外,研究人員還對先前提出的兩個 VLM 模型 PaLI-X(Pathways Language and Image model)和 PaLM-E(Pathways Language model Embodied)進行了適應性調整,當做 RT-2 的主干,并將這些模型的視覺 - 語言 - 動作版本稱為 RT-2-PaLI-X 以及 RT-2-PaLM-E 。
為了使視覺 - 語言模型能夠控制機器人,還差對動作控制這一步。該研究采用了非常簡單的方法:他們將機器人動作表示為另一種語言,即文本 token,并與 Web 規模的視覺 - 語言數據集一起進行訓練。
對機器人的動作編碼基于 Brohan 等人為 RT-1 模型提出的離散化方法。
如下圖所示,該研究將機器人動作表示為文本字符串,這種字符串可以是機器人動作 token 編號的序列,例如「1 128 91 241 5 101 127 217」。

該字符串以一個標志開始,該標志指示機器人是繼續還是終止當前情節,然后機器人根據指示改變末端執行器的位置和旋轉以及機器人抓手等命令。
由于動作被表示為文本字符串,因此機器人執行動作命令就像執行字符串命令一樣簡單。有了這種表示,我們可以直接對現有的視覺 - 語言模型進行微調,并將其轉換為視覺 - 語言 - 動作模型。
在推理過程中,文本 token 被分解為機器人動作,從而實現閉環控制。

實驗
研究人員對 RT-2 模型進行了一系列定性和定量實驗。
下圖展示了 RT-2 在語義理解和基本推理方面的性能。例如,對于「把草莓放進正確的碗里」這一項任務,RT-2 不僅需要對草莓和碗進行表征理解,還需要在場景上下文中進行推理,以知道草莓應該與相似的水果放在一起。而對于「拾起即將從桌子上掉下來的袋子」這一任務,RT-2 需要理解袋子的物理屬性,以消除兩個袋子之間的歧義并識別處于不穩定位置的物體。
需要說明的是,所有這些場景中測試的交互過程在機器人數據中從未見過。

下圖表明在四個基準測試上,RT-2 模型優于之前的 RT-1 和視覺預訓練 (VC-1) 基線。

RT-2 保留了機器人在原始任務上的性能,并提高了機器人在以前未見過場景中的性能,從 RT-1 的 32% 提高到 62%。

一系列結果表明,視覺 - 語言模型(VLM)是可以轉化為強大的視覺 - 語言 - 動作(VLA)模型的,通過將 VLM 預訓練與機器人數據相結合,可以直接控制機器人。
和 ChatGPT 類似,這樣的能力如果大規模應用起來,世界估計會發生不小的變化。不過谷歌沒有立即應用 RT-2 機器人的計劃,只表示研究人員相信這些能理解人話的機器人絕不只會停留在展示能力的層面上。
簡單想象一下,具有內置語言模型的機器人可以放入倉庫、幫你抓藥,甚至可以用作家庭助理 —— 折疊衣物、從洗碗機中取出物品、在房子周圍收拾東西。
它可能真正開啟了在有人環境下使用機器人的大門,所有需要體力勞動的方向都可以接手 —— 就是之前 OpenAI 有關預測 ChatGPT 影響工作崗位的報告中,大模型影響不到的那部分,現在也能被覆蓋。
具身智能,離我們不遠了?
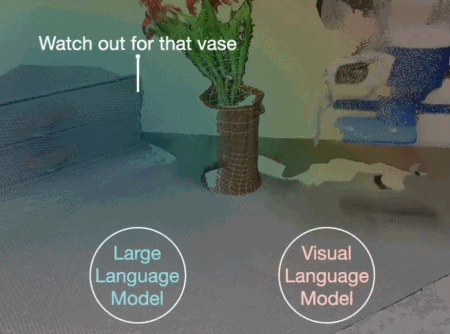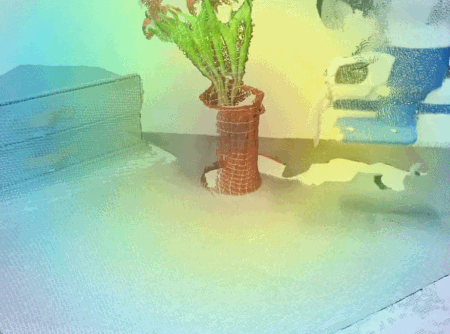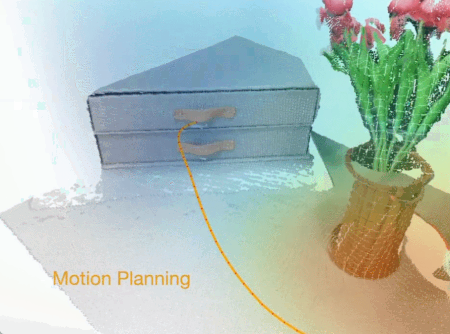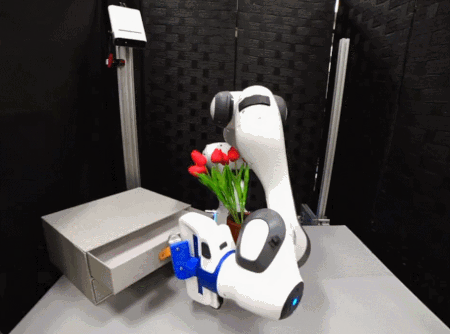
最近一段時間,具身智能是大量研究者正在探索的方向。本月斯坦福大學李飛飛團隊就展示了一些新成果,通過大語言模型加視覺語言模型,AI 能在 3D 空間分析規劃,指導機器人行動。
 圖片
圖片
稚暉君的通用人形機器人創業公司「智元機器人(Agibot)」昨天晚上放出的視頻,也展示了基于大語言模型的機器人行為自動編排和任務執行能力。
 圖片
圖片
預計在 8 月,稚暉君的公司即將對外展示最近取得的一些成果。
可見在大模型領域里,還有大事即將發生。





















