













作者 | 崔皓
審校 | 重樓
摘要
文章介紹了如何使用ControlNets來控制Latent Diffusion Models生成醫學圖像的過程。首先,討論了擴散模型的發展和其在生成過程中的控制挑戰,然后介紹了ControlNets的概念和優勢。接著,文章詳細解釋了如何訓練Latent Diffusion Model和ControlNet,以及如何使用ControlNet進行采樣和評估。最后,文章展示了使用ControlNets生成的醫學圖像,并提供了性能評估結果。文章的目標是展示這些模型在將腦圖像轉換為各種對比度的能力,并鼓勵讀者在自己的項目中使用這些工具。
開篇
本文將介紹如何訓練一個ControlNet,使用戶能夠精確地控制Latent Diffusion Model(如Stable Diffusion!)的生成過程。我們的目標是展示模型將腦圖像轉換為各種對比度的能力。為了實現這一目標,我們將利用最近推出的MONAI開源擴展,即MONAI Generative Models!
項目代碼可以在這個公共倉庫中找到:https://github.com/Warvito/generative_brain_controlnet
引言
近年來,文本到圖像的擴散模型取得了顯著的進步,人們可以根據開放領域的文本描述生成高逼真的圖像。這些生成的圖像具有豐富的細節,清晰的輪廓,連貫的結構和有意義的場景。然而,盡管擴散模型取得了重大的成就,但在生成過程的精確控制方面仍存在挑戰。即使是內容豐富的文本描述,也可能無法準確地捕捉到用戶的想法。
正如Lvmin Zhang和Maneesh Agrawala在他們的開創性論文“Adding Conditional Control to Text-to-Image Diffusion Models”(2023)中所提出的那樣,ControlNets的引入顯著提高了擴散模型的可控性和定制性。這些神經網絡充當輕量級的適配器,可以精確地控制和定制,同時保留擴散模型的原始生成能力。通過對這些適配器進行微調,同時保持原始擴散模型不被修改,可以有效地增強文本到圖像模型的多樣性。
【編者:擴展模型允許我們在保持原始模型不變的同時,對模型的行為進行微調。這意味著我們可以利用原始模型的生成能力,同時通過ControlNets來調整生成過程,以滿足特定的需求或改進性能。】
ControlNet的獨特之處在于它解決了空間一致性的問題。與以往的方法不同,ControlNet允許對結構空間、結構和幾何方面進行明確的控制,同時保留從文本標題中獲得的語義控制。原始研究引入了各種模型,使得可以基于邊緣、姿態、語義掩碼和深度圖進行條件生成,為計算機視覺領域激動人心的進步鋪平了道路。
【編者:空間一致性是指在圖像生成或處理過程中,生成的圖像應該在空間上保持一致性,即相鄰的像素或區域之間應該有合理的關系和連續性。例如,在生成一個人臉的圖像時,眼睛、鼻子和嘴巴的相對位置應該是一致的,不能隨機分布。在傳統的生成模型中,保持空間一致性可能是一個挑戰,因為模型可能會在嘗試生成復雜的圖像時產生不一致的結果。
例如,你正在使用一個文本到圖像的模型來生成一張貓的圖像,來看看如何使用邊緣、姿態、語義掩碼和深度圖這四個條件。
1. 邊緣:創建一個邊緣圖來表示貓的輪廓。包括貓的頭部、身體、尾巴等主要部分的邊緣信息。
2.姿態:創建姿態圖來表示貓的姿勢。例如,一只正在跳躍的貓,可以在姿態圖中表示出這個跳躍的動作。
3.語義掩碼:創建一個語義掩碼來表示貓的各個部分。例如,在語義掩碼中標出貓的眼睛、耳朵、鼻子等部分。
4.深度圖:創建深度圖來表示貓的三維形狀。例如,表示出貓的頭部比尾巴更接近觀察者。
通過這四個步驟,就可以指導模型生成一只符合我們需求的貓的圖像。】
在醫學成像領域,經常會遇到圖像轉換的應用場景,因此ControlNet的使用就非常有價值。在這些應用場景中,有一個場景需要將圖像在不同的領域之間進行轉換,例如將計算機斷層掃描(CT)轉換為磁共振成像(MRI),或者將圖像在不同的對比度之間進行轉換,例如從T1加權到T2加權的MRI圖像。在這篇文章中,我們將關注一個特定的案例:使用從FLAIR圖像獲取的腦圖像的2D切片來生成相應的T1加權圖像。我們的目標是展示MONAI擴展(MONAI Generative Models)以及ControlNets如何進行醫學數據訓練,并生成評估模型。通過深入研究這個例子,我們能提供關于這些技術在醫學成像領域的最佳實踐。
 FLAIR到T1w轉換
FLAIR到T1w轉換
Latent Diffusion Model訓練
 Latent Diffusion Model架構
Latent Diffusion Model架構
為了從FLAIR圖像生成T1加權(T1w)圖像,首先需要訓練一個能夠生成T1w圖像的擴散模型。在我們的例子中,我們使用從英國生物銀行數據集(根據這個數據協議可用)中提取的腦MRI圖像的2D切片。然后,使用你最喜歡的方法(例如,ANTs或UniRes)將原始的3D腦部圖像注冊到MNI空間后,我們從腦部的中心部分提取五個2D切片。之所以選擇這個區域,因為它包含各種組織,使得我們更容易評估圖像轉換。使用這個腳本,我們最終得到了大約190,000個切片,空間尺寸為224 × 160像素。接下來,使用這個腳本將我們的圖像劃分為訓練集(約180,000個切片)、驗證集(約5,000個切片)和測試集(約5,000個切片)。準備好數據集后,我們可以開始訓練我們的Latent Diffusion Model了!
為了優化計算資源,潛在擴散模型使用一個編碼器將輸入圖像x轉換為一個低維的潛在空間z,然后可以通過一個解碼器進行重構。這種方法使得即使在計算能力有限的情況下也能訓練擴散模型,同時保持了它們的原始質量和靈活性。與我們在之前的文章中所做的類似(使用MONAI生成醫學圖像),我們使用MONAI Generative models中的KL-regularization模型來創建壓縮模型。通過使用這個配置加上L1損失、KL-regularisation,感知損失以及對抗性損失,我們創建了一個能夠以高保真度編碼和解碼腦圖像的自編碼器(使用這個腳本)。自編碼器的重構質量對于Latent Diffusion Model的性能至關重要,因為它定義了生成圖像的質量上限。如果自編碼器的解碼器產生模糊或低質量的圖像,我們的生成模型將無法生成更高質量的圖像。
【編者:KL-regularization,或稱為Kullback-Leibler正則化,是一種在機器學習和統計中常用的技術,用于在模型復雜性和模型擬合數據的好壞之間找到一個平衡。這種正則化方法的名字來源于它使用的Kullback-Leibler散度,這是一種衡量兩個概率分布之間差異的度量。
上面這段話用一個例子來解釋一下,或許會更加清楚一些。
例如,假設你是一個藝術家,你的任務是畫出一系列的貓的畫像。你可以自由地畫任何貓,但是你的老板希望你畫的貓看起來都是"普通的"貓,而不是太奇特的貓。
這就是你的任務:你需要創造新的貓的畫像,同時還要確保這些畫像都符合"普通的"貓的特征。這就像是變分自編碼器(VAE)的任務:它需要生成新的數據,同時還要確保這些數據符合某種預設的分布(也就是"普通的"貓的分布)。
現在,假設你開始畫貓。你可能會發現,有些時候你畫的貓看起來太奇特了,比如它可能有六只眼睛,或者它的尾巴比普通的貓長很多。這時,你的老板可能會提醒你,讓你畫的貓更接近"普通的"貓。
這就像是KL-regularization的作用:它是一種"懲罰",當你生成的數據偏離預設的分布時,它就會提醒你。如果你畫的貓太奇特,你的老板就會提醒你。在VAE中,如果生成的數據偏離預設的分布,KL-regularization就會通過增加損失函數的值來提醒模型。
通過這種方式,你可以在創造新的貓的畫像的同時,還能確保這些畫像都符合"普通的"貓的特征。同樣,VAE也可以在生成新的數據的同時,確保這些數據符合預設的分布。這就是KL-regularization的主要作用。】
【編者:對三種損失函數進行簡要說明:
1. L1損失:L1損失,也稱為絕對值損失,是預測值和真實值之間差異的絕對值的平均。它的公式為 L1 = 1/n Σ|yi - xi|,其中yi是真實值,xi是預測值,n是樣本數量。L1損失對異常值不敏感,因為它不會過度懲罰預測錯誤的樣本。例如,如果我們預測一個房價為100萬,但實際價格為110萬,L1損失就是10萬。
2. 感知損失:感知損失是一種在圖像生成任務中常用的損失函數,它衡量的是生成圖像和真實圖像在感知層面的差異。感知損失通常通過比較圖像在某個預訓練模型(如VGG網絡)的某一層的特征表示來計算。這種方法可以捕捉到圖像的高級特性,如紋理和形狀,而不僅僅是像素級的差異。例如,如果我們生成的貓的圖像和真實的貓的圖像在顏色上有細微的差異,但在形狀和紋理上是一致的,那么感知損失可能就會很小。
3. 對抗性損失:對抗性損失是在生成對抗網絡(GAN)中使用的一種損失函數。在GAN中,生成器的任務是生成看起來像真實數據的假數據,而判別器的任務是區分真實數據和假數據。對抗性損失就是用來衡量生成器生成的假數據能否欺騙判別器。例如,如果我們的生成器生成了一張貓的圖像,而判別器幾乎無法區分這張圖像和真實的貓的圖像,那么對抗性損失就會很小。】
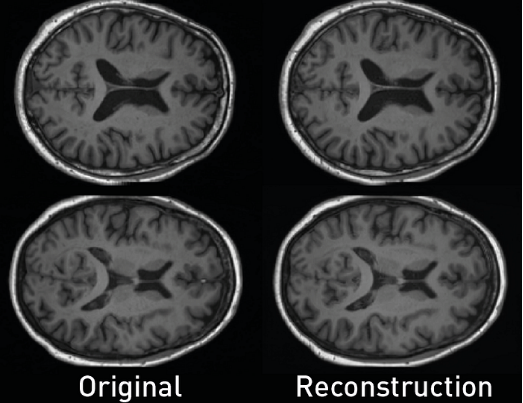
使用這個腳本,我們可以通過使用原始圖像和它們的重構之間的多尺度結構相似性指數測量(MS-SSIM)來量化自編碼器的保真度。在這個例子中,我們得到了一個高性能的MS-SSIM指標,等于0.9876。
【編者:多尺度結構相似性指數測量(Multi-Scale Structural Similarity Index, MS-SSIM)是一種用于衡量兩幅圖像相似度的指標。它是結構相似性指數(Structural Similarity Index, SSIM)的擴展,考慮了圖像的多尺度信息。
SSIM是一種比傳統的均方誤差(Mean Squared Error, MSE)或峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)更符合人眼視覺感知的圖像質量評價指標。它考慮了圖像的亮度、對比度和結構三個方面的信息,而不僅僅是像素級的差異。
MS-SSIM則進一步考慮了圖像的多尺度信息。它通過在不同的尺度(例如,不同的分辨率)上計算SSIM,然后將這些SSIM值進行加權平均,得到最終的MS-SSIM值。這樣可以更好地捕捉到圖像的細節和結構信息。
例如,假設我們有兩幅貓的圖像,一幅是原始圖像,另一幅是我們的模型生成的圖像。我們可以在不同的尺度(例如,原始尺度、一半尺度、四分之一尺度等)上計算這兩幅圖像的SSIM值,然后將這些SSIM值進行加權平均,得到MS-SSIM值。如果MS-SSIM值接近1,那么說明生成的圖像與原始圖像非常相似;如果MS-SSIM值遠離1,那么說明生成的圖像與原始圖像有較大的差異。
MS-SSIM常用于圖像處理和計算機視覺的任務中,例如圖像壓縮、圖像增強、圖像生成等,用于評價處理或生成的圖像的質量。文中MS-SSIM被用來量化自編碼器的保真度,即自編碼器重構的圖像與原始圖像的相似度。得到的MS-SSIM指標為0.9876,接近1,說明自編碼器的重構質量非常高,重構的圖像與原始圖像非常相似。】
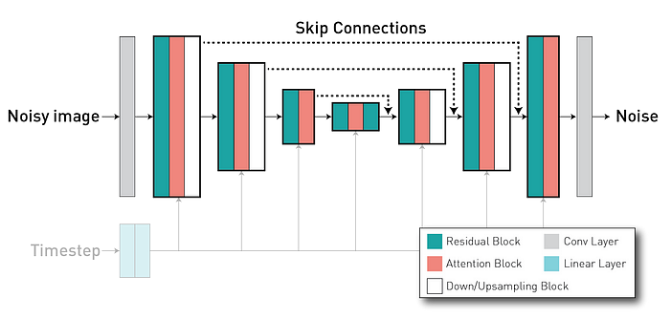
在我們訓練了自編碼器之后,我們將在潛在空間z上訓練diffusion model(擴散模型)。擴散模型是一個能夠通過在一系列時間步上迭代地去噪來從純噪聲圖像生成圖像的模型。它通常使用一個U-Net架構(具有編碼器-解碼器格式),其中我們有編碼器的層跳過連接到解碼器部分的層(通過長跳躍連接),使得特征可重用并穩定訓練和收斂。
【編者:這段話描述的是訓練擴散模型的過程,以及擴散模型的基本工作原理。
首先,作者提到在訓練了自編碼器之后,他們將在潛在空間z上訓練擴散模型。這意味著他們首先使用自編碼器將輸入圖像編碼為一個低維的潛在空間z,然后在這個潛在空間上訓練擴散模型。
擴散模型是一種生成模型,它的工作原理是從純噪聲圖像開始,然后通過在一系列時間步上迭代地去噪,最終生成目標圖像。這個過程就像是將一個模糊的圖像逐漸清晰起來,直到生成一個清晰的、與目標圖像相似的圖像。
擴散模型通常使用一個U-Net架構。U-Net是一種特殊的卷積神經網絡,它有一個編碼器部分和一個解碼器部分,編碼器部分用于將輸入圖像編碼為一個潛在空間,解碼器部分用于將潛在空間解碼為一個輸出圖像。U-Net的特點是它有一些跳躍連接,這些連接將編碼器部分的某些層直接連接到解碼器部分的對應層。這些跳躍連接可以使得編碼器部分的特征被重用在解碼器部分,這有助于穩定訓練過程并加速模型的收斂。】
在訓練過程中,Latent Diffusion Model學習了給定這些提示的條件噪聲預測。再次,我們使用MONAI來創建和訓練這個網絡。在這個腳本中,我們使用這個配置來實例化模型,其中訓練和評估在代碼的這個部分進行。由于我們在這個教程中對文本提示不太感興趣,所以我們對所有的圖像使用了相同的提示( “腦部的T1加權圖像”)。
 我們的Latent Diffusion Model生成的合成腦圖像
我們的Latent Diffusion Model生成的合成腦圖像
再次,我們可以量化生成模型從而提升其性能,這次我們評估樣本的質量(使用Fréchet inception distance (FID))和模型的多樣性(計算一組1,000個樣本的所有樣本對之間的MS-SSIM)。使用這對腳本(1和2),我們得到了FID = 2.1986和MS-SSIM Diversity = 0.5368。
如你在前面的圖像和結果中所看到的,我們現在有一個高分辨率圖像的模型,質量非常好。然而,我們對圖像的外觀沒有任何空間控制。為此,我們將使用一個ControlNet來引導我們的Latent Diffusion Model的生成。
ControlNet訓練
 ControlNet架構
ControlNet架構
ControlNet架構包括兩個主要組成部分:一個是U-Net模型的編碼器(可訓練版本),包括中間塊,以及一個預訓練的“鎖定”版本的擴散模型。在這里,鎖定的副本保留了生成能力,而可訓練的副本在特定的圖像到圖像數據集上進行訓練,以學習條件控制。這兩個組件通過一個“零卷積”層相互連接——一個1×1的卷積層,其初始化的權重和偏置設為零。卷積權重逐漸從零過渡到優化的參數,確保在初始訓練步驟中,可訓練和鎖定副本的輸出與在沒有ControlNet的情況下保持一致。換句話說,當ControlNet在任何優化之前應用到某些神經網絡塊時,它不會對深度神經特征引入任何額外的影響或噪聲。
【編者:描述ControlNet架構的設計和工作原理。ControlNet架構包括兩個主要部分:一個可訓練的U-Net模型的編碼器,以及一個預訓練的、被"鎖定"的擴散模型。
用一個例子來幫助理解。假設你正在學習畫畫,你有一個老師(預訓練的"鎖定"的擴散模型)和一個可以修改的畫布(可訓練的U-Net模型的編碼器)。你的老師已經是一個經驗豐富的藝術家,他的技能(生成能力)是固定的,不會改變。而你的畫布是可以修改的,你可以在上面嘗試不同的畫法,學習如何畫畫(學習條件控制)。
這兩個部分通過一個"零卷積"層相互連接。這個"零卷積"層就像是一個透明的過濾器,它最初不會改變任何東西(因為它的權重和偏置都初始化為零),所以你可以看到你的老師的原始畫作。然后,隨著你的學習進步,這個過濾器會逐漸改變(卷積權重從零過渡到優化的參數),開始對你的老師的畫作進行修改,使其更符合你的風格。
這個設計確保了在初始訓練步驟中,可訓練部分和"鎖定"部分的輸出是一致的,即你的畫作最初會和你的老師的畫作一樣。然后,隨著訓練的進行,你的畫作會逐漸展現出你自己的風格,但仍然保持著你老師的基本技巧。】
通過整合這兩個組件,ControlNet使我們能夠控制Diffusion Model(擴散模型)的U-Net中每個級別的行為。
在我們的例子中,我們在這個腳本中實例化了ControlNet,使用了以下等效的代碼片段。
import torch
from generative.networks.nets import ControlNet, DiffusionModelUNet
# Load pre-trained diffusion model
diffusion_model = DiffusionModelUNet(
spatial_dims=2,
in_channels=3,
out_channels=3,
num_res_blocks=2,
num_channels=[256, 512, 768],
attention_levels=[False, True, True],
with_conditioning=True,
cross_attention_dim=1024,
num_head_channels=[0, 512, 768],
)
diffusion_model.load_state_dict(torch.load("diffusion_model.pt"))
# Create ControlNet
controlnet = ControlNet(
spatial_dims=2,
in_channels=3,
num_res_blocks=2,
num_channels=[256, 512, 768],
attention_levels=[False, True, True],
with_conditioning=True,
cross_attention_dim=1024,
num_head_channels=[0, 512, 768],
conditioning_embedding_in_channels=1,
conditioning_embedding_num_channels=[64, 128, 128, 256],
)
# Create trainable copy of the diffusion model
controlnet.load_state_dict(diffusion_model.state_dict(), strict=False)
# Lock the weighht of the diffusion model
for p in diffusion_model.parameters():
p.requires_grad = False由于我們使用的是Latent Diffusion Model,這需要ControlNets將基于圖像的條件轉換為相同的潛在空間,以匹配卷積的大小。為此,我們使用一個與完整模型一起訓練的卷積網絡。在我們的案例中,我們有三個下采樣級別(類似于自動編碼器KL),定義在“conditioning_embedding_num_channels=[64, 128, 128, 256]”。由于我們的條件圖像是一個FLAIR圖像,只有一個通道,我們也需要在“conditioning_embedding_in_channels=1”中指定其輸入通道的數量。
初始化我們的網絡后,我們像訓練擴散模型一樣訓練它。在以下的代碼片段(以及代碼的這部分)中,可以看到首先將條件FLAIR圖像傳遞給可訓練的網絡,并從其跳過連接中獲取輸出。然后,當計算預測的噪聲時,這些值被輸入到擴散模型中。在內部,擴散模型將ControlNets的跳過連接與自己的連接相加,然后在饋送解碼器部分之前(代碼)。以下是訓練循環的一部分:
# Training Loop...
images = batch["t1w"].to(device)
cond = batch["flair"].to(device)
...
noise = torch.randn_like(latent_representation).to(device)
noisy_z = scheduler.add_noise(
original_samples=latent_representation, noise=noise, timesteps=timesteps)
# Compute trainable part
down_block_res_samples, mid_block_res_sample = controlnet(
x=noisy_z, timesteps=timesteps, context=prompt_embeds, controlnet_cond=cond)
# Using controlnet outputs to control diffusion model behaviour
noise_pred = diffusion_model(
x=noisy_z,
timesteps=timesteps,
context=prompt_embeds,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,)
# Then compute diffusion model loss as usual...ControlNet采樣和評估
在訓練模型之后,我們可以對它們進行采樣和評估。在這里,使用測試集中的FLAIR圖像來生成條件化的T1w圖像。與我們的訓練類似,采樣過程非常接近于擴散模型使用的過程,唯一的區別是將條件圖像傳遞給訓練過的ControlNet,并在每個采樣時間步中使用其輸出來饋送擴散模型。如下圖所示,我們生成的圖像具有高空間保真度的原始條件,皮層回旋遵循類似的形狀,圖像保留了不同組織之間的邊界。
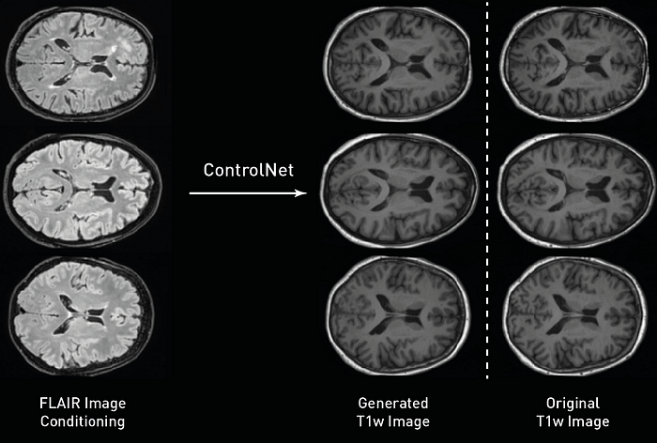
測試集中的原始FLAIR圖像作為輸入到ControlNet(左),生成的T1加權圖像(中),和原始的T1加權圖像,也就是預期的輸出(右)
在我們對模型的圖像進行采樣之后,可以量化ControlNet在將圖像在不同對比度之間轉換時的性能。由于我們從測試集中得到了預期的T1w圖像,我們也可以檢查它們的差異,并使用平均絕對誤差(MAE)、峰值信噪比(PSNR)和MS-SSIM計算真實和合成圖像之間的距離。在我們的測試集中,當執行這個腳本時,我們得到了PSNR= 26.2458+-1.0092,MAE=0.02632+-0.0036和MSSIM=0.9526+-0.0111。
ControlNet為我們的擴散模型提供了令人難以置信的控制,最近的方法已經擴展了其方法,結合了不同的訓練ControlNets(Multi-ControlNet),在同一模型中處理不同類型的條件(T2I適配器),甚至在模型上設置條件(使用像ControlNet 1.1這樣的方法)。如果這些方法聽起來很有趣,不要猶豫,嘗試一下!
總結
在這篇文章中,我們展示了如何使用ControlNets來控制Latent Diffusion Models生成醫學圖像的過程。我們的目標是展示這些模型在將腦圖像轉換為各種對比度的能力。為了實現這一目標,我們利用了最近推出的MONAI的開源擴展,即MONAI Generative Models!我們希望這篇文章能幫助你理解如何使用這些工具,并鼓勵你在你自己的項目中使用它們。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。
原文標題:Controllable Medical Image Generation with ControlNets,作者:Walter Hugo Lopez Pinaya




















