













Prompt、RAG、微調還是重新訓練?如何選擇正確的生成式AI的使用方法
生成式人工智能正在快速發展,許多人正在嘗試使用這項技術來解決他們的業務問題。一般情況下有4種常見的使用方法:
- Prompt Engineering
- Retrieval Augmented Generation (RAG 檢索增強生成)
- 微調
- 從頭開始訓練基礎模型(FM)
本文將試圖根據一些常見的可量化指標,為選擇正確的生成式人工智能方法提供建議。
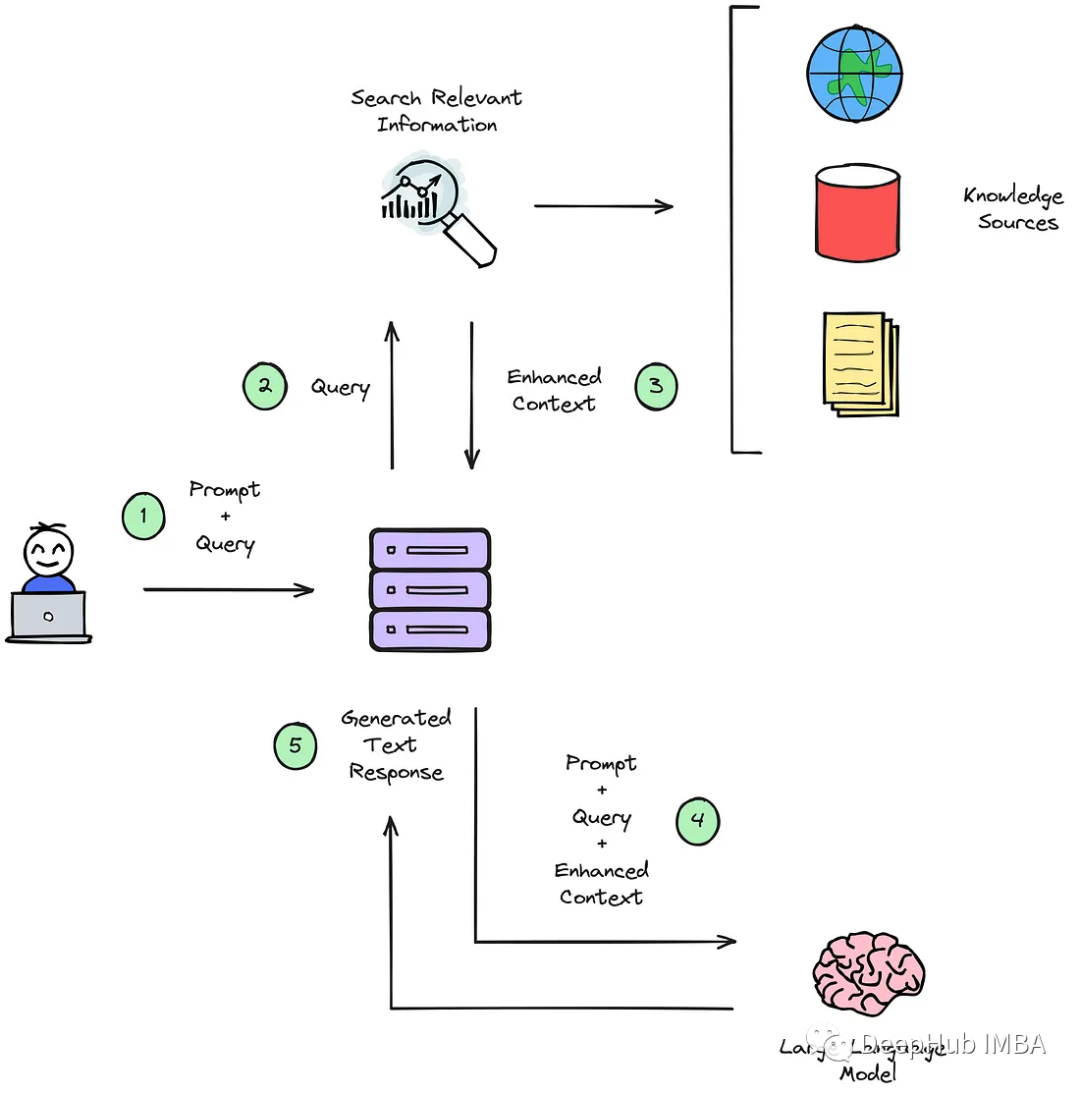
本文不包括“使用原模型”的選項,因為幾乎沒有任何業務用例可以有效地使用基礎模型。按原樣使用基礎模型可以很好地用于一般搜索,但對于任何特定的用力,則需要使用上面提到的選項之一。
如何執行比較?
基于以下指標:
- 準確性(回答有多準確?)
- 實現復雜性(實現可以有多復雜?)
- 投入工作量(需要多少工作的投入來實現?)
- 總成本(擁有解決方案的總成本是多少?)
- 靈活性(架構的耦合有多松?更換/升級組件有多容易?)
我們將對這些度量標準上的每個解決方案方法進行評級,進行一個簡單的對比。
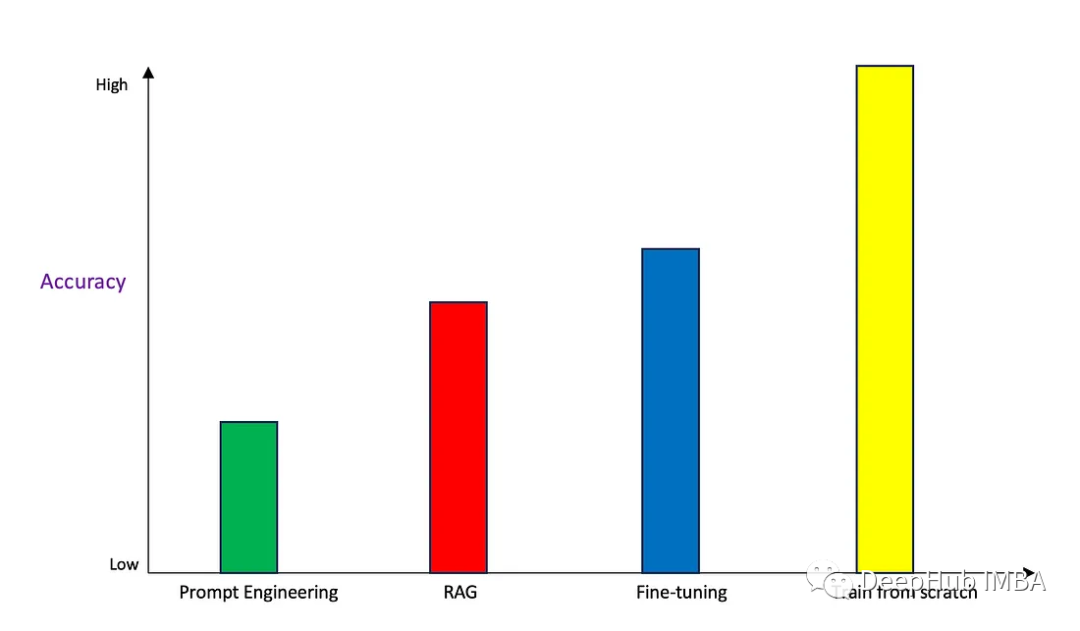
準確性
讓我們首先得到討論最總要的一點:哪種方法提供最準確的響應?
Prompt Engineering就是通過提供少量示例提供盡可能多的上下文,以使基礎模型更好地了解用例。雖然單獨來看,結果可能令人印象深刻,但與其他方法相比,它產生的結果最不準確。
RAG產生了高質量的結果,因為它增加了直接來自向量化信息存儲的特定于用例的上下文。與Prompt Engineering相比,它產生的結果大大改善,而且產生幻覺的可能性非常低。
微調也提供了相當精確的結果,輸出的質量與RAG相當。因為我們是在特定領域的數據上更新模型權重,模型產生更多的上下文響應。與RAG相比,質量可能稍微好一些,但這取決于具體實例。所以評估是否值得花時間在兩者之間進行權衡分析是很重要的。一般來說,選擇微調可能有不同的原因,而不僅僅是精度。還包括數據更改的頻率、在自己的環境中控制模型實現法規、遵從性和可再現性等目的等等。
從頭開始的訓練產生了最高質量的結果(這是肯定的)。由于模型是在用例特定數據上從零開始訓練的,所以產生幻覺的幾率幾乎為零,輸出的準確率也是比較中最高的。
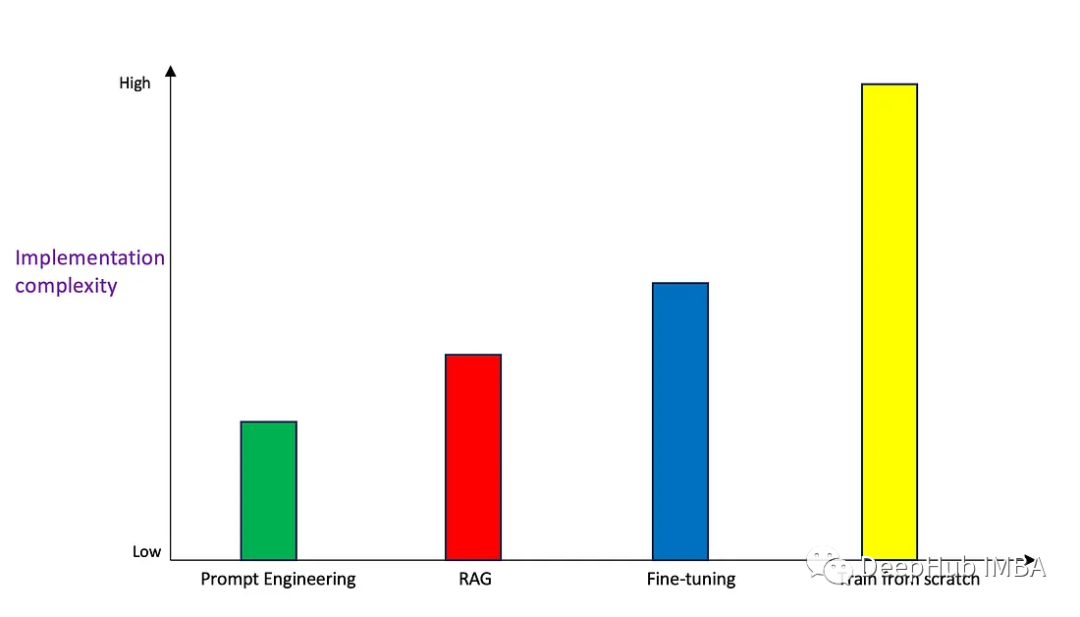
實現的復雜性
除了準確性以外,另外一個需要關注的就是實現這些方法的難易程度。
Prompt Engineering具有相當低的實現復雜性,因為它幾乎不需要編程。需要具備良好的英語(或其他)語言技能和領域專業知識,可以使用上下文學習方法和少樣本學習方法來創建一個好的提示。
RAG比Prompt Engineering具有更高的復雜性,因為需要編碼和架構技能來實現此解決方案。根據在RAG體系結構中選擇的工具,復雜性可能更高。
微調比上面提到的兩個更復雜,因為模型的權重/參數是通過調優腳本更改的,這需要數據科學和ML專業知識。
從頭開始訓練肯定具有最高的實現復雜性,因為它需要大量的數據管理和處理,并且訓練一個相當大的模型,這需要深入的數據科學和ML專業知識。
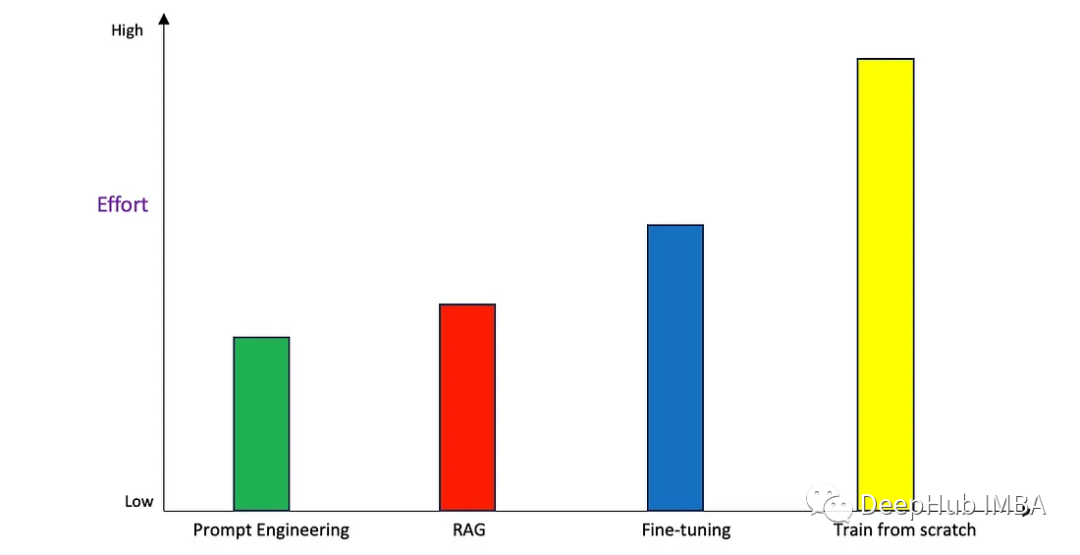
工作量投入
實現的復雜性和工作量并不總是成正比的。
Prompt Engineering需要大量的迭代努力才能做到正確。基礎模型對提示的措辭非常敏感,改變一個詞甚至一個動詞有時會產生完全不同的反應。所以需要相當多的迭代才能使其適用于相應的需求。
由于涉及到創建嵌入和設置矢量存儲的任務,RAG也需要很多的工作量,比Prompt Engineering要高一些。
微調則比前兩個要更加費力。雖然微調可以用很少的數據完成(在某些情況下甚至大約或少于30個示例),但是設置微調并獲得正確的可調參數值需要時間。
從頭開始訓練是所有方法中最費力的方法。它需要大量的迭代開發來獲得具有正確技術和業務結果的最佳模型。這個過程從收集和管理數據開始,設計模型體系結構,并使用不同的建模方法進行實驗,以獲得特定用例的最佳模型。這個過程可能會很長(幾周到幾個月)。
總成本
我們討論的不僅僅是服務/組件花費,而是完全實現解決方案的成本,其中包括熟練工程師(人員),用于構建和維護解決方案的時間,其他任務的成本,如自己維護基礎設施,執行升級和更新的停機時間,建立支持渠道,招聘,提高技能和其他雜項成本。
Prompt Engineering的成本是相當低的,因為需要維護的只是提示模板,并在基礎模型版本更新或新模型發布時時保持它們的最新狀態即可。除此之外,托管模型或通過API直接使用還會有一些而額外的成本。
由于架構中涉及多個組件,RAG 的成本要比Prompt Engineering略高。這取決于所使用的嵌入模型、向量存儲和模型。因為在這里需要為3個不同的組件付費。
微調的成本肯定要高于前兩個,因為調整的是一個需要強大計算能力的模型,并且需要深入的ML技能和對模型體系結構的理解。并且維護這種解決方案的成本也會更高,因為每次有基本模型版本更新或新數據批次進入時都需要調優。
從頭開始訓練無疑是成本最高的,因為團隊必須擁有端到端數據處理和ML訓練、調優和部署能力。這需要一群高技能的機器學習從業者來完成。維護這種解決方案的成本非常高,因為需要頻繁的重新訓練周期來保持模型與用例周圍的新信息保持同步。

靈活性
我們來看看在簡化更新和更改方面的是什么情況
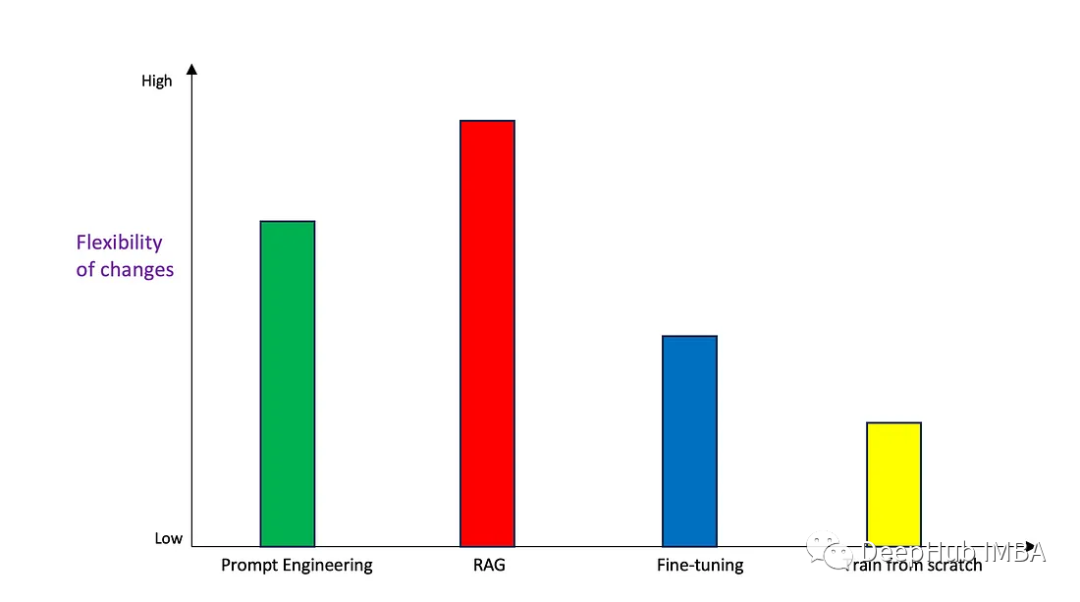
Prompt Engineering具有非常高的靈活性,因為只需要根據基礎模型和用例的變化更改提示模板。
當涉及到架構中的更改時,RAG也具很最高程度的靈活性。可以獨立地更改嵌入模型、向量存儲和LLM,而對其他組件的影響最小。它還可以在不影響其他組件的情況下在復雜授權等流程中添加更多組件。
微調對更改的靈活性非常低,因為數據和輸入的任何更改都需要另一個微調周期,這可能非常復雜且耗時。同樣,將相同的微調模型調整到不同的用例也需要很多的工作,因為相同的模型權重/參數在其他領域的表現可能比它所調整的領域差。
從頭開始訓練的靈活性最低的。因為模型是從頭構建的,對模型執行更新會觸發另一個完整的重新訓練周期。我們也可以微調模型,而不是從頭開始重新訓練,但準確性會有所不同。
總結
從以上所有的比較中可以明顯看出,沒有明顯的輸贏。因為最終的選擇取決于設計解決方案時最重要的指標是什么,我們的建議如下:
當希望在更改模型和提示模板方面具有更高的靈活性,并且用例不包含大量域上下文時,可以使用Prompt Engineering。
當想要在更改不同組件(數據源,嵌入,FM,矢量引擎)方面具有最高程度的靈活性時,使用RAG,這樣簡單并且可以保持輸出的高質量(前提是你要有數據)。
當希望更好地控制模型工件及其版本管理時,可以使用微調。尤其是領域特定術語與數據非常特定時(如法律、生物學等),它也很有用。
當以上都不適合的時候,可以從頭開始訓練。既然覺得上面的方案準確性都不夠高,所以就需要有足夠的預算和時間來做的更好。
總而言之,選擇正確的生成AI方法需要深入思考并評估可接受和不可接受的指標。甚至是根據不同的時期選擇不同的方案。















