













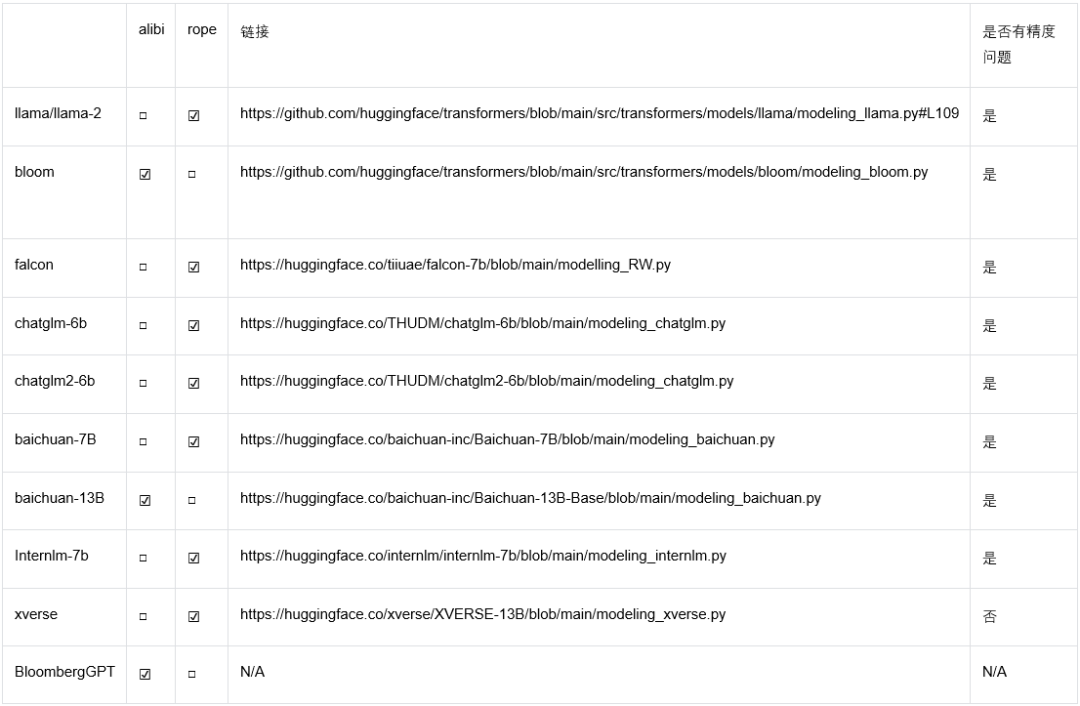
Llama也中招,混合精度下位置編碼竟有大坑,百川智能給出修復(fù)方案
位置編碼技術(shù)是一種能夠讓神經(jīng)網(wǎng)絡(luò)建模句子中 Token 位置信息的技術(shù)。在 Transformer 大行其道的時代,由于 Attention 結(jié)構(gòu)無法建模每個 token 的位置信息,位置編碼(Position embedding) 成為 Transformer 非常重要的一個組件。研究人員也提出了各種各樣的位置編碼方案來讓網(wǎng)絡(luò)建模位置信息,Rope 和 Alibi 是目前最被廣泛采納的兩種位置編碼方案。
然而最近來自百川智能的研究發(fā)現(xiàn),Rope 和 alibi 位置編碼的主流實現(xiàn)在低精度(尤其是 bfloat16) 下存在位置編碼碰撞的 bug, 這可能會影響模型的訓(xùn)練和推理。而且目前大部分主流開源模型的實現(xiàn)都存在該問題,連 llama 官方代碼也中招了。
還得從位置編碼算法說起
為了弄清楚這個問題,得先從位置編碼的算法原理說起,在 Transformer 結(jié)構(gòu)中,所有 Attention Block 的輸入都會先經(jīng)過位置編碼,再輸入網(wǎng)絡(luò)進(jìn)行后續(xù)處理。純粹的 Attention 結(jié)構(gòu)是無法精確感知到每個 token 的位置信息的,而對于語言的很多任務(wù)來說,語句的順序?qū)φZ義信息的影響是非常大的,為了建模 token 之間的位置關(guān)系,Transfomer 原始論文中引入位置編碼來建模位置信息。

圖 1 - 施加 Positon Embedding 示意圖。
為了讓模型更好地建模句子的位置信息,研究人員提出了多種位置編碼方案,meta 開源的 llama [4] 模型采用了 Rope [5] 方案,使得 Rope 成為在開源社區(qū)被廣泛采納的一種位置編碼方案。而 Alibi 編碼因其良好的外推性也被廣泛應(yīng)用。
了解低精度下的位置編碼碰撞之前,先來回顧一下相關(guān)算法原理。
Sinusoidal 位置編碼
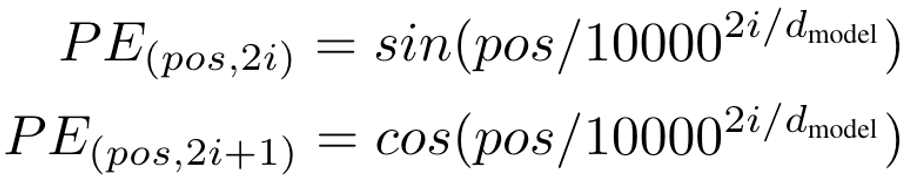
這是 Transformer 原始論文中提出的位置編碼方法。它通過使用不同頻率的正弦和余弦函數(shù)來為每個位置產(chǎn)生一個獨特的編碼。選擇三角函數(shù)來生成位置編碼有兩個良好的性質(zhì):
1)編碼相對位置信息,數(shù)學(xué)上可以證明 PE (pos+k) 可以被 PE (pos) 線性表示, 這意味著位置編碼中蘊(yùn)含了相對位置信息。
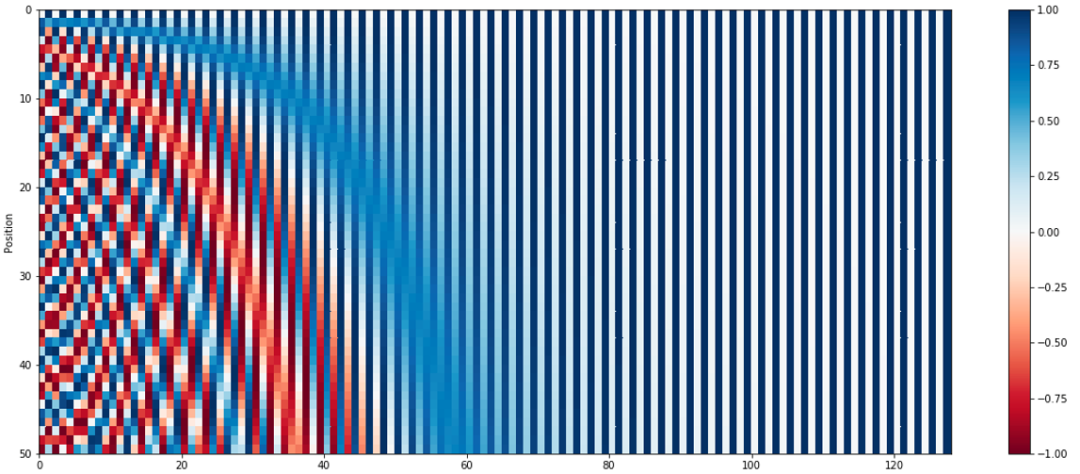
圖 2- 句子長度為 50 的位置編碼,編碼維度 128,每行代表一個 Position Embedding。
2)遠(yuǎn)程衰減:不同位置的 position encoding 點乘結(jié)果會隨著相對位置的增加而遞減 [1]。

圖 3 - 不同位置的位置編碼點積可視化。
Rope
Rope 是目前開源社區(qū)應(yīng)用最廣泛的一種位置編碼方案, 通過絕對位置編碼的方式實現(xiàn)相對位置編碼,在引入相對位置信息的同時保持了絕對位置編碼的優(yōu)勢(不需要像相對位置編碼一樣去操作 attention matrix)。令 f_q, f_k 為 位置編碼的函數(shù),m 表示位置,x_m 表示該位置 token 對應(yīng)的 embedding,我們希望經(jīng)過位置編碼后的 embedding 點積僅和相對位置有關(guān),則可以有公式:

上面公式中 g 是某個函數(shù),表示內(nèi)積的結(jié)果只和 x_m 和 x_n 的值,以及二者位置的相對關(guān)系 (m-n) 有關(guān)在 2 維的情況下可以推導(dǎo)出(詳細(xì)推導(dǎo)過程可參考原論文):

因為矩陣乘法線性累加的性質(zhì),可以拓展到多維的情況可得:
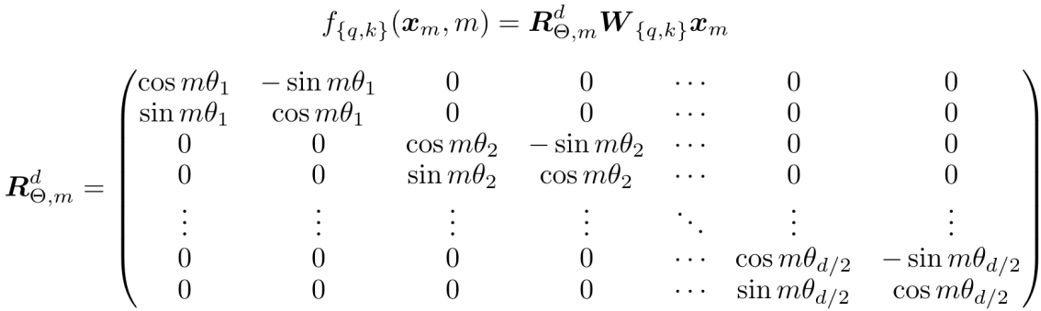
為了引入遠(yuǎn)程衰減的特性,Rope 中 \theta 的選取選擇了 Transformer 原始論文中 sinusoidal 公式。
Alibi
Alibi 是谷歌發(fā)表在 ICLR2022 的一篇工作,Alibi 主要解決了位置編碼外推效果差的痛點,算法思想非常的簡單,而且非常直觀。與直接加在 embedding 上的絕對位置編碼不同,Alibi 的思想是在 attention matrix 上施加一個與距離成正比的懲罰偏置,懲罰偏置隨著相對距離的增加而增加。在具體實現(xiàn)時,對于每個 head 會有一個超參 m 來控制懲罰偏置隨著相對距離增加的幅度(斜率)。
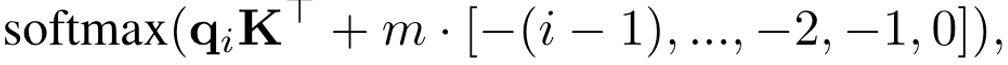
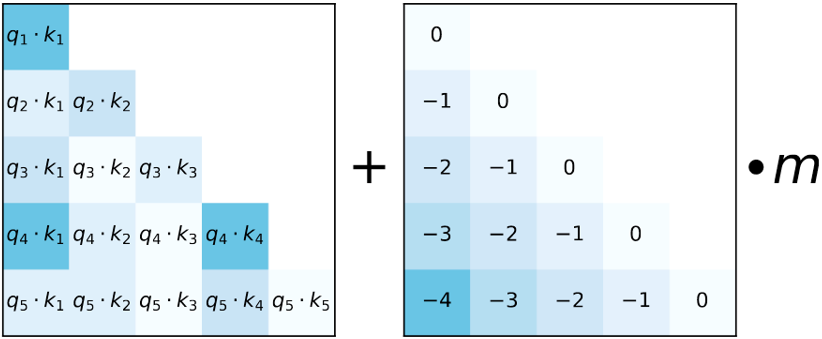
圖 4 - Alibi attention bias 示意圖
論文結(jié)果顯示 Alibi 極大的提升了模型的外推性能,16k token 的輸入依然可以很好的支持。
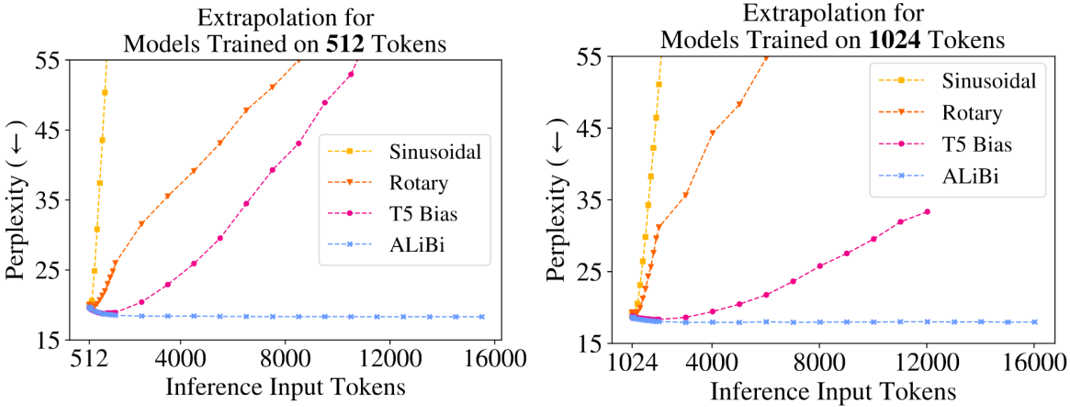
圖 5 - Alibi 外推效果對比。
混合精度下位置編碼的 bug
從上面的算法原理中,不管是 rope 的 cos (m\theta) 還是 alibi 的 i-1(m, i 代表 postion id), 需要為每個位置生成一個整型的 position_id, 在上下文窗口比較大的時候,百川智能發(fā)現(xiàn)目前主流的位置編碼實現(xiàn)在混合精度下都存在因為低精度(float16/bfloat16) 浮點數(shù)表示精度不足導(dǎo)致位置編碼碰撞的問題。尤其當(dāng)模型訓(xùn)練(推理)時上下文長度越來越長,低精度表示帶來的位置編碼碰撞問題越來越嚴(yán)重,進(jìn)而影響模型的效果,下面以 bfloat16 為例來說明這個 bug。
浮點數(shù)表示精度
浮點數(shù)在計算機(jī)中表示由符號位(sign),指數(shù)位 (exponent),尾數(shù)位 (fraction) 三部分組成,對于一個常規(guī)的數(shù)值表示,可以由如下公式來計算其代表的數(shù)值(其中 offset 是指數(shù)位的偏置):

由公式可知,尾數(shù)位的長度決定了浮點數(shù)的表示精度。深度學(xué)習(xí)中常用的 float32/float16/bfloat16 內(nèi)存中的表示分別如下圖所示:

圖 6- bfloat16 的表示格式

圖 7- float16 的表示格式

圖 8- float32 的表示格式
可以看到 float16 和 bfloat16 相比于 float32 都犧牲了表示的精度,后續(xù)以 bfloat16 為例說明位置編碼中存在的問題(float16 同理)。下表展示了 bfloat16 在不同數(shù)值范圍(只截取整數(shù)部分)內(nèi)的表示精度。

可以看到當(dāng)整數(shù)范圍超過 256, bfloat16 就無法精確表示每一個整數(shù),可以用代碼驗證一下表示精度帶來的問題。
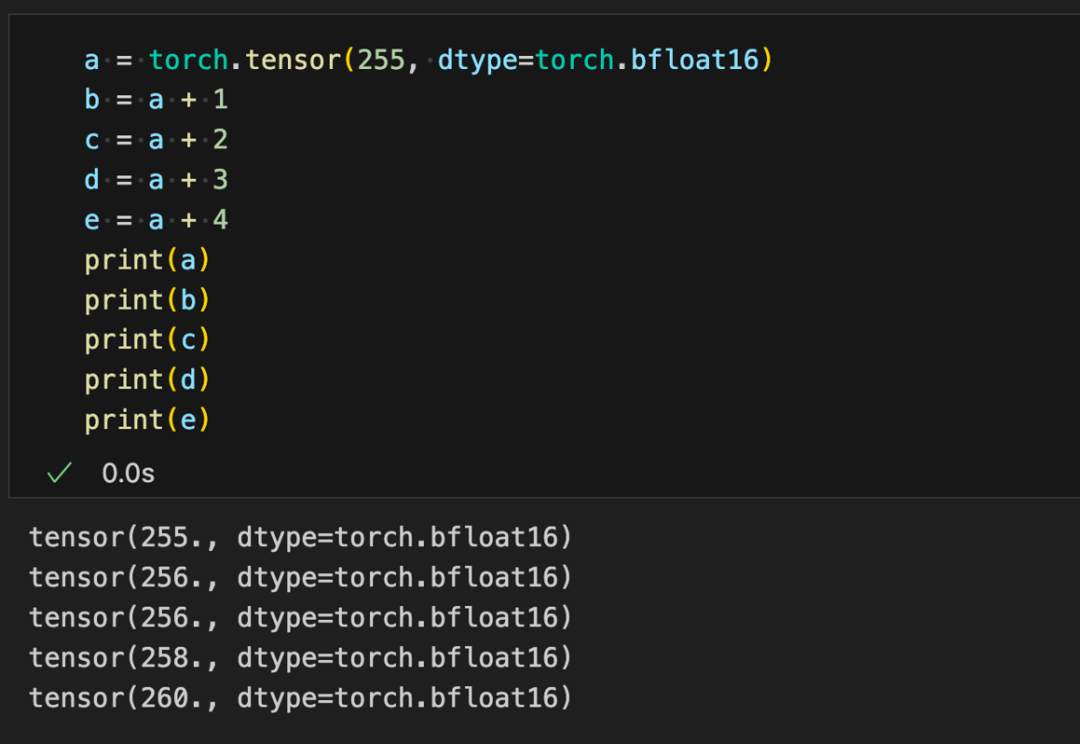
Rope& Alibi 編碼的問題
Meta 開源的 llama 模型采用了 Rope 的位置編碼方式, 官方的實現(xiàn)(以及大部分的第三方 llama 系列模型)在 bfloat16 下存在精度問題帶來的位置編碼碰撞(不同位置的 token 在 bfloat16 下變成同一個數(shù))。Llama 官方代碼如下:
Python
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
)上面第 18 行核心一句根據(jù)輸入序列長度生成每個位置的 positon idx 在 bfloat16 下產(chǎn)生位置碰撞。
Python
# self.inv_freq.dtype == torch.bfloat16 when bfloat16 is enabled during training
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)在實際訓(xùn)練時如果開了 bfloat16, self.inv_freq 的 dtype 會被轉(zhuǎn)為 bfloat16, 可以通過簡單的代碼來看一下位置碰撞的問題。
Python
t = torch.arange(4096, dtype=torch.float32)
plt.scatter(t[-100:], t[-100:].to(torch.bfloat16).float(),s=0.8)
plt.xlabel('position in float32')
plt.ylabel('position in bfloat16'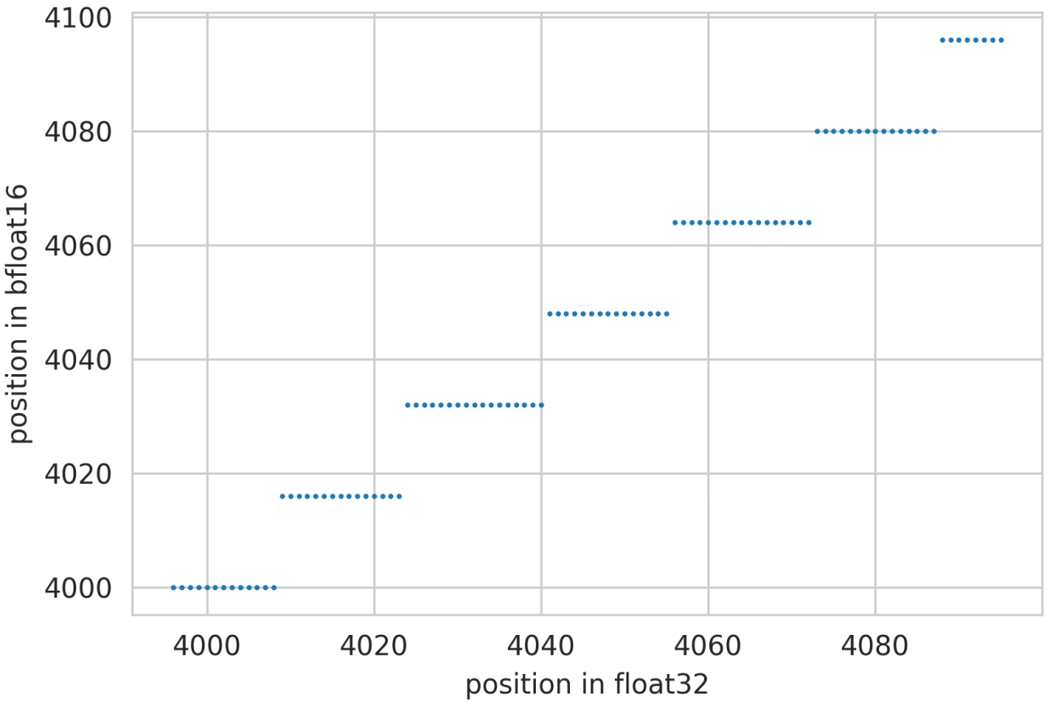
根據(jù) bfloa16 的表示精度可知,訓(xùn)練(推理)時上下文長度越長,位置編碼碰撞的情況越嚴(yán)重,長度為 8192 的上下文推理中,僅有大約 10% 的 token 位置編碼是精確的,好在位置編碼碰撞有局域性的特質(zhì),只有若干個相鄰的 token 才會共享同一個 position Embedding, 在更大的尺度上,不同位置的 token 還是有一定的區(qū)分性。

圖 10- 不同上下文窗口下位置編碼精確 token 所占比例。
除了 llama 模型,百川智能發(fā)現(xiàn) alibi 位置編碼也存在上述問題,原因依然在于生成整數(shù)的位置索引時會在低精度下產(chǎn)生碰撞問題。
修復(fù)方案
Rope 修復(fù)
Rope 的修復(fù)相對簡單,只需要保證在生成 position_id 的時候一定在 float32 的精度上即可。注意:
float32 的 tensor register_buffer 后在訓(xùn)練時如果開啟了 bfloat16, 也會被轉(zhuǎn)為 bfloat16。
Python
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
self.inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
)
def _set_cos_sin_cache(self, seq_len):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=torch.float32)
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
)Alibi 修復(fù)
- alibi 位置編碼修復(fù)思路和 Rope 的修復(fù)思路一致,但因為 alibi 的 attention bias 直接加在 attention matrix 上面,如果按照上面的修復(fù)思路,attention matrix 的類型必須和 attention bias 一致,導(dǎo)致整個 attention 的計算都在 float32 類型上計算,這會極大的拖慢訓(xùn)練速度
- 目前主流的 attention 加速方法 flashattention 不支持 attention bias 參數(shù), 而 xformers 要求 attention bias 類型必須與 query.dtype 相同,因此像 rope 那樣簡單的將 attention bias 類型提升到 float32 將會極大的拖慢訓(xùn)練速度
- 針對該問題百川智能提出了一種新的 alibi attention 方案, 整個 attention bias 依然在 bfloat16 類型上,類似于 sinusiodal 的遠(yuǎn)程衰減特質(zhì), 可以盡量保證臨近 token 位置編碼的精確性,對于相對距離過遠(yuǎn)的的 token 則可以容忍其產(chǎn)生一定的位置碰撞。原本的 alibi 實現(xiàn)則相反,相對距離越遠(yuǎn)的 token 表示越精確,相對距離越近的 token 則會碰撞
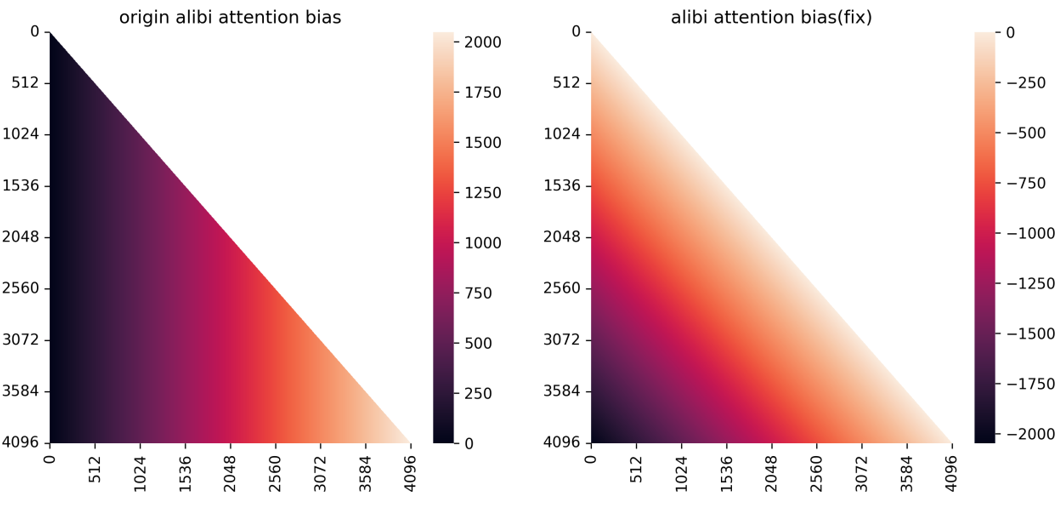
圖 11- 修復(fù)前后 alibi attention_bias 對照。
修復(fù)效果
百川智能僅在推理階段對位置編碼的精度問題進(jìn)行修復(fù)【注:訓(xùn)練階段可能也存在問題,取決于訓(xùn)練的具體配置和方法】,可以看到:
a. 在長上下文的推理中,模型的 ppl 要顯著優(yōu)于修復(fù)前的 ppl
b.Benchmark 上測試結(jié)果顯示修復(fù)前后區(qū)別不大,可能是因為 benchmark 上測試文本長度有限,很少觸發(fā) Position embedding 的碰撞
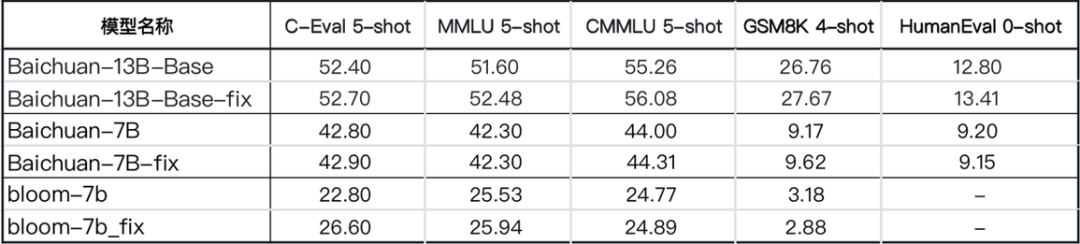
Benchmark 對比
Perplexity
我們在通用的文本數(shù)據(jù)上對修改前后模型在中英文文本上的困惑度進(jìn)行測試,效果如下:






















