













阿里大模型又開源!能讀圖會識物,基于通義千問7B打造,可商用
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯(lián)系出處。
阿里開源大模型,又上新了~
繼通義千問-7B(Qwen-7B)之后,阿里云又推出了大規(guī)模視覺語言模型Qwen-VL,并且一上線就直接開源。

具體來說,Qwen-VL是基于通義千問-7B打造的多模態(tài)大模型,支持圖像、文本、檢測框等多種輸入,并且在文本之外,也支持檢測框的輸出。
舉個??,我們輸入一張阿尼亞的圖片,通過問答的形式,Qwen-VL-Chat既能概括圖片內容,也能定位到圖片中的阿尼亞。

測試任務中,Qwen-VL展現(xiàn)出了“六邊形戰(zhàn)士”的實力,在四大類多模態(tài)任務的標準英文測評中(Zero-shot Caption/VQA/DocVQA/Grounding)上,都取得了SOTA。

開源消息一出,就引發(fā)了不少關注。


具體表現(xiàn)如何,咱們一起來看看~
首個支持中文開放域定位的通用模型
先來整體看一下Qwen-VL系列模型的特點:
- 多語言對話:支持多語言對話,端到端支持圖片里中英雙語的長文本識別;
- 多圖交錯對話:支持多圖輸入和比較,指定圖片問答,多圖文學創(chuàng)作等;
- 首個支持中文開放域定位的通用模型:通過中文開放域語言表達進行檢測框標注,也就是能在畫面中精準地找到目標物體;
- 細粒度識別和理解:相比于目前其它開源LVLM(大規(guī)模視覺語言模型)使用的224分辨率,Qwen-VL是首個開源的448分辨率LVLM模型。更高分辨率可以提升細粒度的文字識別、文檔問答和檢測框標注。
按場景來說,Qwen-VL可以用于知識問答、圖像問答、文檔問答、細粒度視覺定位等場景。
比如,有一位看不懂中文的外國友人去醫(yī)院看病,對著導覽圖一個頭兩個大,不知道怎么去往對應科室,就可以直接把圖和問題丟給Qwen-VL,讓它根據(jù)圖片信息擔當翻譯。

再來測試一下多圖輸入和比較:
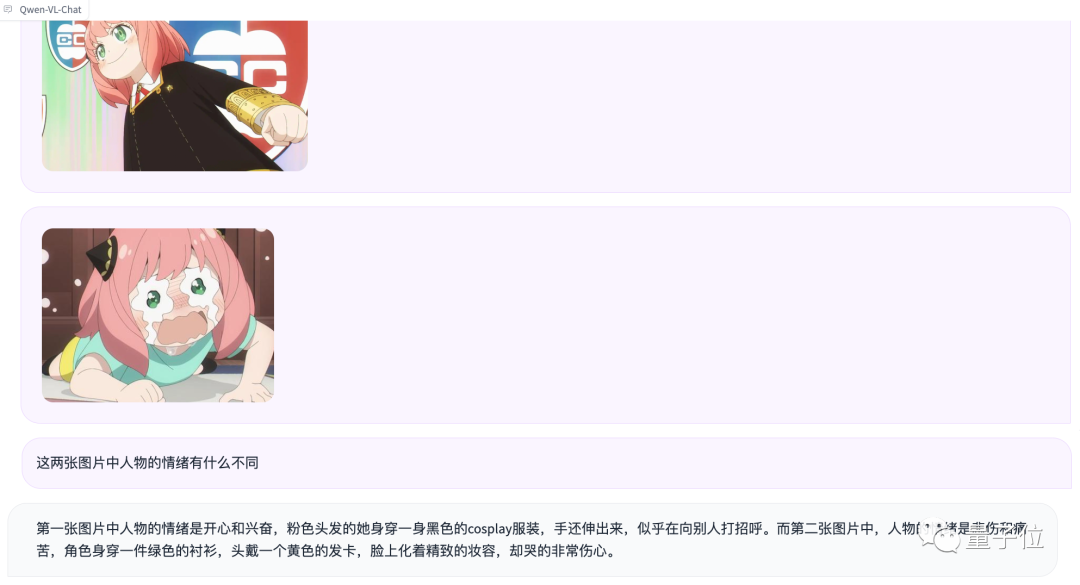
雖然沒認出來阿尼亞,不過情緒判斷確實挺準確的(手動狗頭)。
視覺定位能力方面,即使圖片非常復雜人物繁多,Qwen-VL也能精準地根據(jù)要求找出綠巨人和蜘蛛俠。

技術細節(jié)上,Qwen-VL是以Qwen-7B為基座語言模型,在模型架構上引入了視覺編碼器ViT,并通過位置感知的視覺語言適配器連接二者,使得模型支持視覺信號輸入。

具體的訓練過程分為三步:
- 預訓練:只優(yōu)化視覺編碼器和視覺語言適配器,凍結語言模型。使用大規(guī)模圖像-文本配對數(shù)據(jù),輸入圖像分辨率為224x224。
- 多任務預訓練:引入更高分辨率(448x448)的多任務視覺語言數(shù)據(jù),如VQA、文本VQA、指稱理解等,進行多任務聯(lián)合預訓練。
- 監(jiān)督微調:凍結視覺編碼器,優(yōu)化語言模型和適配器。使用對話交互數(shù)據(jù)進行提示調優(yōu),得到最終的帶交互能力的Qwen-VL-Chat模型。
研究人員在四大類多模態(tài)任務(Zero-shot Caption/VQA/DocVQA/Grounding)的標準英文測評中測試了Qwen-VL。

結果顯示,Qwen-VL取得了同等尺寸開源LVLM的最好效果。
另外,研究人員構建了一套基于GPT-4打分機制的測試集TouchStone。


在這一對比測試中,Qwen-VL-Chat取得了SOTA。
如果你對Qwen-VL感興趣,現(xiàn)在在魔搭社區(qū)和huggingface上都有demo可以直接試玩,鏈接文末奉上~
Qwen-VL支持研究人員和開發(fā)者進行二次開發(fā),也允許商用,不過需要注意的是,商用的話需要先填寫問卷申請。
項目鏈接:https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/QwenLM/Qwen-VL
論文地址:https://arxiv.org/abs/2308.12966






























