













720億參數大模型都拿來開源了!通義千問開源全家桶,最小18億模型端側都能跑
「Qwen-72B 模型將于 11 月 30 日發布。」前幾天,X 平臺上的一位網友發布了這樣一則消息,消息來源是一段對話。他還說,「如果(新模型)像他們的 14B 模型一樣,那將是驚人的。」
有位網友轉發了帖子并配文「千問模型最近表現不錯」。
這句話里的 14B 模型指的是阿里云在 9 月份開源的通義千問 140 億參數模型 Qwen-14B。當時,這個模型在多個權威評測中超越同等規模模型,部分指標甚至接近 Llama2-70B,在國內外開發者社區中非常受歡迎。在之后的兩個月里,用過 Qwen-14B 的開發者自然也會對更大的模型產生好奇和期盼。
看來,日本的開發者也在期待。
正如消息中所說的,11 月 30 日,Qwen-72B 開源了。它以一己之力讓追開源動態的國外開發者也過上了杭州時間。

阿里云還在今天的發布會上公布了很多細節。
從性能數據來看,Qwen-72B 沒有辜負大家的期盼。在 MMLU、AGIEval 等 10 個權威基準測評中,Qwen-72B 都拿到了開源模型的最優成績,成為性能最強的開源模型,甚至超越了開源標桿 Llama 2-70B 和大部分商用閉源模型(部分成績超越 GPT-3.5 和 GPT-4)。
要知道,在此之前,中國大模型市場還沒有出現足以對抗 Llama 2-70B 的優質開源大模型,Qwen-72B 填補了這一空白。之后,國內大中型企業可基于它的強大推理能力開發商業應用,高校、科研院所可基于它開展 AI for Science 等科研工作。


此外,一起發布的還有一個小模型 ——Qwen-1.8B,以及一個音頻模型 Qwen-Audio。Qwen-1.8B 和 Qwen-72B 一小一大,加上之前已經開源的 7B、14B 模型,組成了一個完整的開源光譜,適配各種應用場景。Qwen-Audio 和之前開源的視覺理解模型 Qwen-VL 以及基礎文本模型則組成了一個多模態光譜,可以幫助開發者把大模型的能力擴展到更多真實環境。

通義千問最小開源模型Qwen-1.8B,推理2K長度文本內容僅需3G顯存。看來,希望在手機等端側部署語言模型的開發者可以上手一試。
這種「全尺寸、全模態」的開源力度,業界無出其右。Qwen-72B 更是抬升了開源模型尺寸和性能的天花板。為了驗證這一開源模型的能力,機器之心在阿里云魔搭社區上手體驗了一番,并討論了通義千問開源模型對于開發者的吸引力所在。
第一手體驗:
推理更強,還能自定義角色
下圖是 Qwen-72B 的用戶界面。你可以在下方「Input」框輸入想要問的問題或其他交互內容,中間框會輸出答案。目前,Qwen-72B 支持中文和英文輸入,這也是通義千問和 Llama2 差別比較大的一點。此前,Llama2 中文支持不佳讓很多國內開發者很頭疼。

體驗地址:https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
我們了解到,在中文任務上,Qwen-72B 霸榜了 CEVAL、CMMLU、Gaokao 等測評,尤其在復雜語義理解、邏輯推理方面頗為拿手。先來一個包含中國武俠小說人物元素的易混淆句子分析,Qwen-72B 顯然 get 到了幾個「過」的不同意思。

類似容易繞暈人的另一個句子也解釋得很清楚。

再來一個經典的「農夫、狐貍、兔子和蘿卜」安全過河游戲,Qwen-72B 也能應答如流。

既然 Qwen-72B 支持英文輸入,我們也要來考一考它的雙語交互能力怎么樣?簡單詩歌的翻譯當然不在話下。

Qwen-72B 還很懂地道的美式俚語。

數學小能手上線
數學一直是考驗大模型的重要一關。數據顯示,Qwen-72B 在 MATH 等測試中相較于其他開源模型取得了斷層式的領先優勢,那實測效果怎么樣呢?首先考它一道經典的擲骰子概率題,顯然,它沒有被難倒。

雞兔同籠問題也來一道,回答無誤,只是解題過程有點特別。

兩個瓶子裝水問題也能迎刃而解。

化身林黛玉、孔老夫子
賦予大模型個性化角色是此次 Qwen-72B 的一大特色。得益于其強大的系統指令能力,你只需要設置提示詞就可以定制自己的 AI 助手,讓它擁有獨特的角色、性格、腔調等。
我們先讓它以林黛玉的語氣回復。

再讓它化身孔老夫子,諄諄教誨撲面而來。

東北、天津等各地方言腔調也能脫口而出。


這么好的效果是怎么實現的呢?根據阿里云公布的技術資料,Qwen-72B 的推理性能提升其實離不開數據、訓練等幾個層面的優化。
在數據層面,目前通義利用了高達 3T tokens 的數據,詞表高達十五萬。據通義千問團隊的人透露,模型還在持續訓練,未來還會吃更多高質量數據。
在模型訓練上,他們綜合利用了 dp、tp、pp、sp 等方法進行大規模分布式并行訓練,引入 Flash Attention v2 等高效算子提升訓練速度。借助阿里云人工智能平臺 PAI 的拓撲感知調度機制,有效降低了大規模訓練時的通信成本,將訓練速度提高 30%。
累計超150萬的下載量是怎么來的?
從上面的測評結果來看,以 Qwen-72B 為代表的通義千問系列開源模型的確給了開發者很多選擇它們的理由,比如比 Llama 2 更強的中文能力。
有鹿機器人創始人、CEO 陳俊波就提到,他們在做產品時把市面上能找到的大模型都做過實驗,最后選擇了通義千問,因為「它是目前至少在中文領域能找到的智能性表現最好的開源大模型之一」。
那為什么不用閉源模型呢?中國能源建設集團浙江省電力設計院有限公司系統室專工陶佳提到,國外的模型(比如 GPT-4)能力很強,但是 API 調用不便,而且 B 端用戶更喜歡自己上手定制,API 能做的事還是太少。

模型的可定制性也是陳俊波比較在意的一個點。他說,他們需要的不是一個智能性水平一成不變的大語言模型,而是隨著企業數據的積累能變得越來越聰明的大語言模型,「閉源大模型顯然做不到這一點,所以在我們的業態里面,終局一定是開源模型。」
在談到利用通義千問開源模型搭建應用的感受時,陶佳描述說,「在我試過的幾款開源模型中,通義千問是最好的,不僅回答準確,而且『手感』很好。『手感』這個東西比較主觀,總的來說就是用起來最符合我的需求,沒有那些稀奇古怪的 bug。」
其實說到「需求」,幾乎每一個 B 端用戶的需求都離不開「降本增效」,這是開源模型的另一個優勢。一份 9 月份的統計顯示,Llama2 -70B 大約比 GPT-4 便宜 30 倍,即使在 OpenAI 宣布降價后,Llama2 -70B 依然保留了數倍的成本優勢,體量小于 70B 的衍生開源模型就更不用說了。這對企業來說是非常有吸引力的。
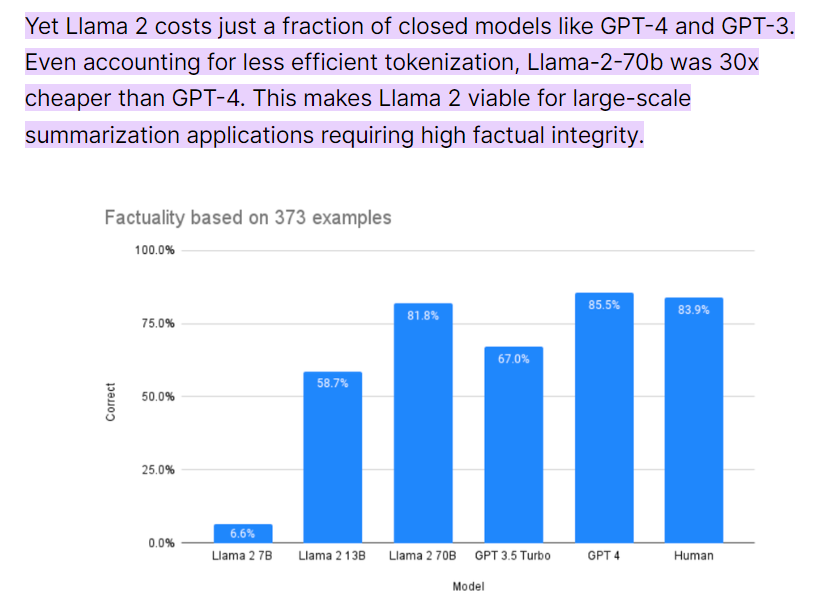
圖源:https://promptengineering.org/how-does-llama-2-compare-to-gpt-and-other-ai-language-models/
例如數據企服品牌瓴羊 Quick BI 產品負責人王兆天就提到,千問的一大優勢是輕量,「在較低成本硬件環境即可部署使用」,這讓 Quick BI 依托通義千問大模型開發的智能數據助手「智能小Q」可以搶占先機,比競爭對手更早推出,搶占用戶心智。
未來速度聯合創始人、CEO 秦續業的一句話可能能讓很多企業找到共鳴。他說,企業級用戶更在意的是能不能解決問題,而非要求模型能力面面面俱到。企業「問題」有難有易,可調用的資金、算力和面臨的部署要求也存在很大差異,因此對模型的靈活度、性價比要求都非常高。比如有的企業可能希望讓大模型跑在手機等端側設備上,而有的企業算力相對充裕,但需要推理能力更強的模型。通義千問剛好為開發者提供了這些選擇 —— 從 1.8B 到 72B,從文字到語音再到圖像,這是一個豐富的開源套餐,總有一款更符合需求。

在多個權威測試集上,通義千問 18 億參數開源模型 Qwen-1.8B 的性能遠超此前的 SOTA 模型。
不過,這還不是全部。對于選擇開源用戶的開發者、企業來說,模型是否可持續、生態是否豐富也同樣重要。
「我們沒有資源從頭訓練一個基座模型,選模型的第一個考量就是,它背后的機構能不能給模型很好的背書,能不能持續投入基座模型及其生態建設?為跟風、吃紅利而生的大模型不可持續。」這是華東理工大學 X-D Lab 核心成員顏鑫判斷模型是否可持續的一些標準。
顯然,在看過上半年的「百模大戰」之后,他也擔心自己選的模型會在這場競爭中淪為棄子。為了避免這種情況,他選擇了阿里云,因為這是國內大廠里唯一開源大模型的組織。而且,除了通義千問,國內一半以上的頭部大模型都跑在阿里云上,基礎設施建設的投入和可持續性毋庸置疑。
再加上,阿里云做大模型其實已經有些年頭了,2018 年就開始進行大模型研究,2023 年更是釋放出了「all in 大模型」的信號。這些信號對于關心大模型可持續性的開發者來說是一顆定心丸。顏鑫評價說,「阿里云能把通義千問 72B 這么大尺寸的模型都開源出來,說明在開源上是有決心、能持續投入的。」
在生態方面,顏鑫也說出了自己的考量,「我們希望選擇主流的、穩定的模型架構,它能最大限度發揮生態的力量,匹配上下游的環境。」
這其實也是通義千問開源模型的優勢所在。由于開源比較早,阿里云的開源生態其實已經初具規模,通義千問開源模型累計下載量已經超過 150 萬,催生出了幾十款新模型、新應用。這些開發者給通義千問提供了來自應用場景的充沛反饋,使得開發團隊能夠不斷優化開源基礎模型。
此外,社區內相關的配套服務也是一個有吸引力的點。陳俊波提到,「通義千問提供了非常方便的工具鏈,可以讓我們在自己的數據上快速去做 finetune 和各種各樣的實驗。而且通義千問的服務非常好,我們有任何需求都能快速響應。」這是當前大部分開源模型提供者所做不到的。
Yann LeCun:
開源對 AI 發展和社會發展都有好處
不知不覺,ChatGPT 已經發布一周年了,這也是開源模型奮力追趕的一年。在此期間,關于大模型應該開源還是閉源的爭論也一直不絕于耳。
在前段時間的一個采訪中,Meta 首席科學家、圖靈獎獲得者 Yann LeCun 透露了他一直以來致力于開源的理由。他認為,未來的 AI 將成為所有人類知識的存儲庫。而這個存儲庫需要所有人為其做貢獻,這是開源才能做到的事情。此外,他之前還表示,開源模型有助于讓更多的人和企業有能力利用最先進的技術,并彌補潛在的弱點,減少社會差距并改善競爭。
在發布會現場,阿里云 CTO 周靖人重申了他們對開源的重視,稱通義千問將堅持開源開放,希望打造「AI 時代最開放的大模型」。看來,更大的開源模型可以期待一波了。




























