自動(dòng)駕駛和自然語言如何結(jié)合?NuPrompt來了!
原標(biāo)題:Language Prompt for Autonomous Driving
論文鏈接:https://arxiv.org/pdf/2309.04379.pdf
作者單位:北京理工大學(xué) 澳門大學(xué) MEGVII Technology 北京人工智能研究院
代碼鏈接:https://github.com/wudongming97/Prompt4Drivinguunw

論文思路
計(jì)算機(jī)視覺領(lǐng)域的一個(gè)新趨勢是根據(jù)自然語言提示符表示的靈活的人類命令捕獲感興趣的目標(biāo)。然而,由于缺乏配對提示實(shí)例(prompt-instance)數(shù)據(jù),在駕駛場景中使用語言提示的進(jìn)展陷入了瓶頸。為了解決這個(gè)問題,本文提出了第一個(gè)以目標(biāo)為中心的語言提示集,用于3D、多視圖和多幀空間中的駕駛場景,名為NuPrompt。它擴(kuò)展了Nuscenes的數(shù)據(jù)集,構(gòu)造了總共35367個(gè)語言描述,每個(gè)描述平均引用5.3個(gè)目標(biāo)軌跡。基于新基準(zhǔn)中的目標(biāo)-文本對(object-text pairs),本文制定了一個(gè)新的基于提示的駕駛?cè)蝿?wù),即使用語言提示來預(yù)測所描述的目標(biāo)的跨視圖和幀的軌跡(trajectory)。此外,本文還提供了一個(gè)簡單的基于Transformer的端到端基線模型,名為PromptTrack。實(shí)驗(yàn)表明,本文的PromptTrack在NuPrompt上取得了令人印象深刻的性能。本文希望這項(xiàng)工作能為自動(dòng)駕駛社區(qū)提供更多新的見解。
主要貢獻(xiàn)
本文提出了一種新的大規(guī)模語言提示集(language prompt set),名為NuPrompt。據(jù)本文所知,它是第一個(gè)專門研究視頻領(lǐng)域多個(gè)感興趣的3D目標(biāo)的數(shù)據(jù)集。
本文構(gòu)造了一個(gè)新的基于提示的駕駛感知任務(wù),要求使用語言提示作為語義線索來預(yù)測目標(biāo)的軌跡。
本文開發(fā)了一個(gè)簡單的端到端基線模型,稱為PromptTrack,它有效地融合了新構(gòu)建的提示推理分支中的跨模態(tài)特征,以預(yù)測參考目標(biāo)(referent objects),顯示了令人印象深刻的性能。
網(wǎng)絡(luò)設(shè)計(jì)
為了推進(jìn)駕駛場景中提示學(xué)習(xí)的研究,本文提出了一種新的大規(guī)模基準(zhǔn),名為NuPrompt。基準(zhǔn)測試是建立在流行的多視圖3D目標(biāo)檢測數(shù)據(jù)集Nuscenes[2]上的。本文將語言提示分配給具有相同特征的目標(biāo)集合,以便為它們奠定基礎(chǔ)(for grounding them)。從本質(zhì)上講,這個(gè)基準(zhǔn)提供了許多3D實(shí)例-文本匹配,具有三個(gè)主要屬性:
1.真實(shí)駕駛描述。
與現(xiàn)有的基準(zhǔn)測試只表示來自模塊化圖像的2D目標(biāo)不同,本文數(shù)據(jù)集的提示描述了來自3D、環(huán)顧四周和長時(shí)間空間的各種與駕駛相關(guān)的目標(biāo)。圖1展示了一個(gè)典型的例子,即一輛車在多個(gè)視圖中從后面到前面超過了我們的車。
2.實(shí)例級提示標(biāo)注。
每個(gè)提示符都表示一個(gè)細(xì)粒度的、有區(qū)別的、以目標(biāo)為中心的描述,并允許它覆蓋任意數(shù)量的驅(qū)動(dòng)目標(biāo)。
3.大規(guī)模語言提示。
就提示符的數(shù)量而言,NuPrompt可以與當(dāng)前最大的數(shù)據(jù)集[7]相媲美,即包含35367個(gè)語言提示符。
與基準(zhǔn)一起,本文制定了一個(gè)新的基于提示的感知任務(wù),其主要目標(biāo)是使用給定的語言提示來預(yù)測和跟蹤駕駛環(huán)境中的多個(gè) 3D目標(biāo)。該任務(wù)的難點(diǎn)在于兩個(gè)方面:跨幀時(shí)間關(guān)聯(lián)和跨模態(tài)語義理解。為了解決這一挑戰(zhàn),本文提出了一種端到端的基線,它建立在camera-only 3D tracker PF-Track[24]上,命名為PromptTrack。請注意,PF-Track通過它的過去和未來推理分支展示了出色的時(shí)空建模。此外,本文增加了一個(gè)快速推理分支來進(jìn)行跨模態(tài)的融合和理解。具體來說,本文的提示推理涉及到提示嵌入和查詢特征之間的交叉注意力,這些特征來自過去的推理,進(jìn)一步預(yù)測 prompt-referred 目標(biāo)。
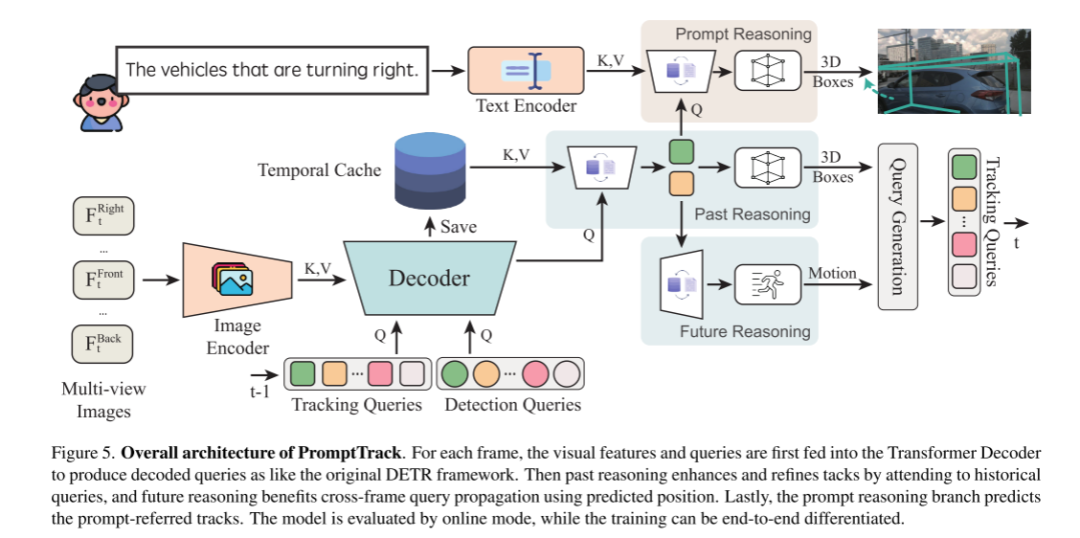
圖5。PromptTrack的總體架構(gòu)。對于每一幀,視覺特征和查詢首先被輸入到Transformer解碼器中,以產(chǎn)生類似于原始DETR框架的解碼查詢。然后,過去的推理通過處理歷史查詢來增強(qiáng)和改進(jìn)策略,而未來的推理則有利于使用預(yù)測位置進(jìn)行跨幀查詢傳播。最后,快速推理分支預(yù)測 prompt-referred 軌跡。該模型采用在線模式進(jìn)行評價(jià),訓(xùn)練可進(jìn)行端到端 differentiated。

圖2。語言提示標(biāo)注過程Pipeline,包括三個(gè)步驟:語言元素收集、語言元素組合、描述生成。首先,在語言元素收集階段,本文將每個(gè)語言標(biāo)簽與 referent objects 配對。然后,在語言元素組合階段,選擇并組合某些語言元素。最后,根據(jù)得到的組合,在描述生成階段采用大型語言模型(LLM)創(chuàng)建語言描述。

圖1。一個(gè)來自NuPrompt的典型例子。語言提示“正在超車的車輛”,在三維、多幀、多視圖空間內(nèi)精確注釋并匹配駕駛目標(biāo)。NuPrompt包含35367個(gè)目標(biāo)-提示符對。

圖3。NuPrompt的前100個(gè)單詞的詞云。它有大量的詞來描述駕駛物體的外觀,如“黑”、“白”、“紅”等,并涵蓋了許多運(yùn)動(dòng)場景,如“走”、“動(dòng)”、“過”等。
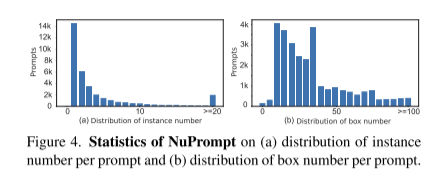
圖4。NuPrompt的統(tǒng)計(jì)信息:(a)每個(gè)提示符的實(shí)例數(shù)分布和(b)每個(gè)提示符的框數(shù)分布。
實(shí)驗(yàn)結(jié)果




引用
Wu, D., Han, W., Wang, T., Liu, Y., Zhang, X., & Shen, J. (2023). Language Prompt for Autonomous Driving. ArXiv. /abs/2309.04379