參數(shù)量僅為1/700,性能超越GPT-3.5!CMU+清華開源Prompt2Model框架
基于大型語言模型(LLM),開發(fā)者或用戶可以通過描述任務(wù),并給出幾個樣例來構(gòu)造自然語言提示,很輕松地就能實現(xiàn)指定的功能。
不過從某種程度上來說,相比傳統(tǒng)的、面向任務(wù)開發(fā)的NLP系統(tǒng),大型語言模型在計算資源需求等方面是一種極大的退步。
最近,卡內(nèi)基梅隆大學(xué)和清華大學(xué)的研究人員提出了一種通用的模型構(gòu)造方法Prompt2Model,開發(fā)者只需要構(gòu)造自然語言提示,就可以訓(xùn)練出一個可用于指定任務(wù)的模型,并易于部署。

論文鏈接:https://arxiv.org/abs/2308.12261
代碼鏈接:https://github.com/neulab/prompt2model
Prompt2Model框架包括檢索現(xiàn)有的數(shù)據(jù)集、生成訓(xùn)練數(shù)據(jù)、搜索與訓(xùn)練模型、微調(diào)訓(xùn)練、自動化評估和部署等多個步驟。
三個任務(wù)的實驗結(jié)果證明,給出相同的少樣本提示作為輸入,Prompt2Model可以訓(xùn)練出一個比大型語言模型更強(qiáng)的小模型,在參數(shù)量僅為gpt-3.5-turbo的1/700的情況下,實現(xiàn)了20%的性能提升。
Prompt2Model框架
Prompt2Model系統(tǒng)相當(dāng)于一個平臺,可以對機(jī)器學(xué)習(xí)管道中的組件進(jìn)行自動化:包括數(shù)據(jù)收集、模型訓(xùn)練、評估和部署。
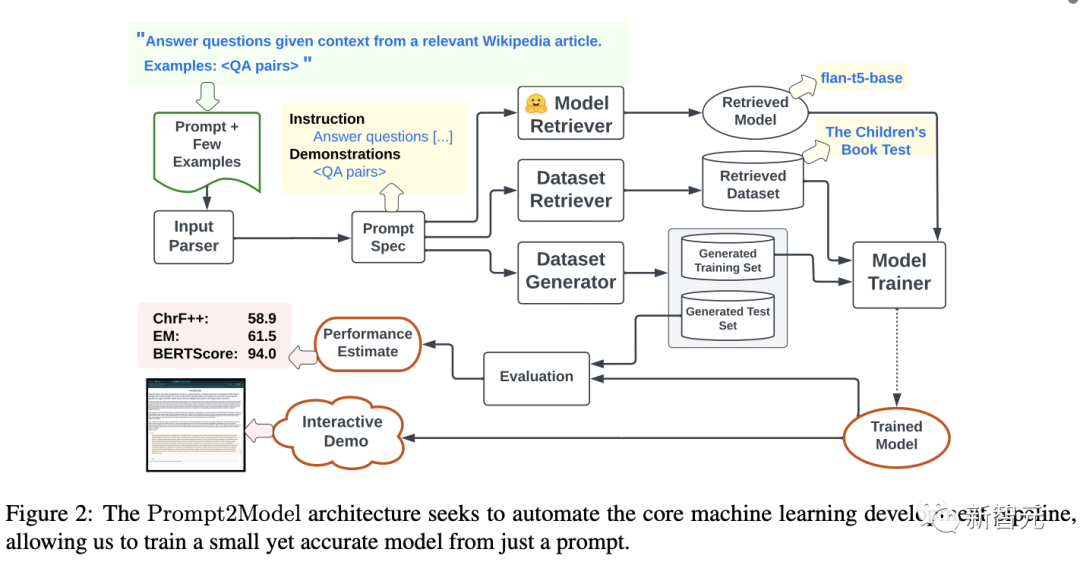
系統(tǒng)的核心是自動數(shù)據(jù)收集系統(tǒng),利用數(shù)據(jù)集檢索和基于LLM的數(shù)據(jù)集生成來獲取與用戶需求相關(guān)的標(biāo)注數(shù)據(jù);
然后檢索預(yù)訓(xùn)練模型,并在收集到的訓(xùn)練數(shù)據(jù)上進(jìn)行微調(diào);
最后使用相同數(shù)據(jù)集下的劃分測試集,對得到的模型進(jìn)行評估,也可以創(chuàng)建一個與模型交互web UI
Prompt2Model非常通用,設(shè)計上也遵循模塊化、可擴(kuò)展,每個組件都可以由開發(fā)者進(jìn)行重新實現(xiàn)或禁用。
下面介紹Prompt2Model各個組件的設(shè)計思路,以及文章作者給出的參考實現(xiàn)。
提示解析器(Prompt Parser)
作為系統(tǒng)的主要輸入,用戶需要提供類似LLMs使用的提示詞,包括指令,或是預(yù)期回復(fù)的幾個演示樣例。
開放式的接口(open-ended interface)對用戶來說很方便,并且端到端(end-to-end)機(jī)器學(xué)習(xí)管道也會從提示解析器中受益,例如將提示分割成指令、單獨的演示樣例,或是將指令翻譯成英語。
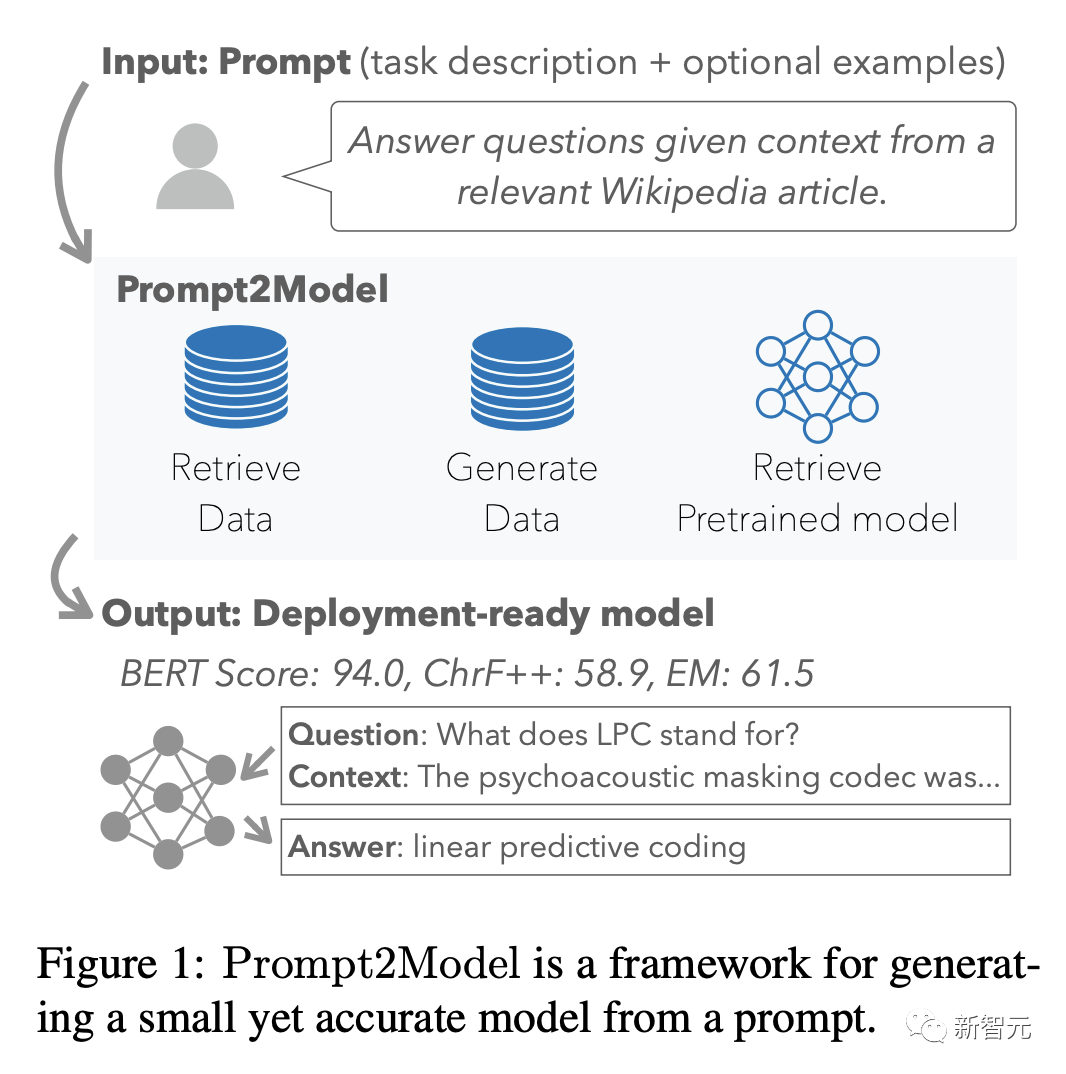
參考實現(xiàn):研究人員將提示解析為指令(instruction)和演示(demonstration),其中指令表示主要的任務(wù)或目標(biāo),演示代表模型的預(yù)期行為。
可以利用具有上下文學(xué)習(xí)能力的大型語言模型(OpenAI gpt-3.5-turbo-0613)對用戶提示進(jìn)行分割;如果用戶指令被識別為非英語,則使用DeepL API.2將其翻譯成英語。
數(shù)據(jù)集檢索器(Dataset Retriever)
用戶給出一個提示后,系統(tǒng)首先會進(jìn)行檢索,嘗試發(fā)現(xiàn)那些符合用戶描述,且已經(jīng)標(biāo)注好的數(shù)據(jù)集,主要包括三個決策:
1. 要搜索哪些數(shù)據(jù)集?
2. 如何對數(shù)據(jù)集索引以支持搜索?
3. 哪些數(shù)據(jù)集是用戶任務(wù)所需要的,哪些應(yīng)該被省略?
參考實現(xiàn):研究人員先在Huggingface上,為所有的數(shù)據(jù)集提取用戶描述,然后利用DataFinder的雙編碼檢索器對數(shù)據(jù)集進(jìn)行相關(guān)度排序。
然后系統(tǒng)會向用戶展示排名靠前的k(=25)個數(shù)據(jù)集,用戶可以選擇相關(guān)數(shù)據(jù)集,也可以聲明沒有適合目標(biāo)任務(wù)的數(shù)據(jù);如果存在可用數(shù)據(jù),用戶還需要從數(shù)據(jù)集的模式中指定輸入和輸出列。
數(shù)據(jù)集生成器(Dataset Generator)
并不是所有的用戶任務(wù)都有完美匹配的數(shù)據(jù)集,但有些數(shù)據(jù)與任務(wù)在一定程度上是相關(guān)的。
為了支持更廣泛的任務(wù),根據(jù)提示解析器得到的用戶要求,可以用數(shù)據(jù)集生成器來產(chǎn)生「合成訓(xùn)練集」,主要難點在于如何降低成本、提升生成速度、生成樣本多樣性以及質(zhì)量控制。
參考實現(xiàn)中,研究人員設(shè)計的策略包括:
1. 高多樣性的少樣本提示
使用自動化提示工程來生成多樣化的數(shù)據(jù)集,用先前生成的示例的隨機(jī)樣本來擴(kuò)充用戶提供的演示示例,以促進(jìn)多樣性并避免生成重復(fù)的示例。
生成200個問答樣本時,該策略可以將重復(fù)樣本從200降低到25個。
2. 溫度退火(Temperature Annealing)
根據(jù)已經(jīng)生成的示例數(shù)量,將采樣溫度從低(輸出結(jié)果更確定)調(diào)整到高(輸出更隨機(jī)),有助于保持輸出質(zhì)量,同時會促進(jìn)數(shù)據(jù)多樣化。
3. 自洽解碼(Self-Consistency Decoding)
鑒于LLM可能為相同的輸入產(chǎn)生非唯一或不正確的輸出,研究人員使用自洽過濾(self-consistency filtering)來選擇偽標(biāo)簽,具體來說,通過選擇最頻繁的答案,為每個唯一的輸入創(chuàng)建一個一致的輸出;在平局的情況下,啟發(fā)式地選擇最短的答案,可以提高生成數(shù)據(jù)集的準(zhǔn)確性,同時確保樣本的唯一性。
4. 異步批處理(Asynchronous Batching)
API請求使用zeno-build進(jìn)行并行化,引入額外的機(jī)制,如動態(tài)批大小和節(jié)流(throttling)來優(yōu)化API的用量。
模型檢索器(Model Retriever)
除了訓(xùn)練數(shù)據(jù)外,完成任務(wù)還需要確定一個合適的模型進(jìn)行微調(diào),研究人員認(rèn)為這也是一個檢索問題,每個模型可以由一段「用戶生成的描述」和「元數(shù)據(jù)」(如受歡迎度、支持的任務(wù)等)。
參考實現(xiàn):為了用統(tǒng)一的模型接口支持海量任務(wù),所以研究人員將系統(tǒng)限制在Huggingface上的編碼器解碼器架構(gòu),對于模型蒸餾來說數(shù)據(jù)效率更高。

然后使用用戶指令作為查詢,基于Huggingface上模型的文本描述進(jìn)行搜索,不過由于模型的描述通常很少,且包含大量模式化文本,通常只有幾個詞能表示模型的內(nèi)容。
遵照HyDE框架,先使用gpt-3.5-turbo根據(jù)用戶的指示創(chuàng)建一個假設(shè)模型描述(hypothetical model description)作為擴(kuò)展查詢,然后用BM25算法計算查詢模型的相似度分?jǐn)?shù)。
為了確保模型易于部署,用戶可以設(shè)定模型的尺寸閾值(默認(rèn)3GB),并過濾掉所有超過該閾值的模型。
一般來說,高下載量的模型可能質(zhì)量也更高,也可以把下載量當(dāng)作參數(shù)對模型進(jìn)行排序:
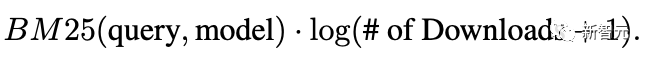
模型訓(xùn)練器(Model Trainer)
給定數(shù)據(jù)集和預(yù)訓(xùn)練模型后,就可以對模型進(jìn)行訓(xùn)練、微調(diào),其中所有的任務(wù)都可以當(dāng)作是文本到文本的生成任務(wù)。
參考實現(xiàn):在處理數(shù)據(jù)集時,研究人員會用到兩個數(shù)據(jù)集,一個是生成的,另一個是檢索到的,并將數(shù)據(jù)列文本化后與用戶指令合并到一起添加到模型輸入中。
在微調(diào)時,將兩個數(shù)據(jù)集組合起來后隨機(jī)打亂,然后訓(xùn)練學(xué)生模型。
在所有的任務(wù)中都使用相同的超參數(shù),使用AdamW優(yōu)化器,以學(xué)習(xí)率5e-5訓(xùn)練3個epoch,每個任務(wù)大約需要一小時。
模型評估器(Model Evaluator)
除去用作訓(xùn)練模型的數(shù)據(jù)后,其余數(shù)據(jù)可以用來評估模型的訓(xùn)練效果,主要難點在與如何在海量的目標(biāo)任務(wù)中選擇出合適的評估指標(biāo)。
參考實現(xiàn):研究人員選擇三個通用的指標(biāo),即精確匹配、ChrF++和BERScore對所有任務(wù)實現(xiàn)自動化評估。
精確匹配(EM)可以衡量模型輸出與參考答案之間完美匹配的程度;ChrF++可以平衡精確度和召回率來評估文本生成質(zhì)量;BERTScore可以通過比較嵌入空間中的模型輸出和引用來捕獲語義相似性。

使用XLM-R作為BERTScore的編碼器可以支持多語言任務(wù)的評估。
演示創(chuàng)建器(Demo Creator)
為了讓開發(fā)者可以將模型發(fā)布給普通用戶,可以在該模塊中創(chuàng)建一個圖形接口以供交互。
參考實現(xiàn):研究人員使用Gradio構(gòu)建了一個模型訪問界面。
實驗部分
實驗設(shè)置
作為概念驗證,研究人員測試了該系統(tǒng)在三項任務(wù)中學(xué)習(xí)模型的能力:
1. 機(jī)器閱讀問題回答:使用SQuAD作為基準(zhǔn)數(shù)據(jù)集來評估。
2. 日語NL-to-Code:從日語查詢中生成代碼是一個有難度的任務(wù),雖然之前有相關(guān)工作,但沒有可用的標(biāo)注數(shù)據(jù)或與訓(xùn)練模型,使用MCoNaLa進(jìn)行評估。
3. 時態(tài)表達(dá)式規(guī)范化(Temporal Expression Normalization):目前沒有任何類型的預(yù)訓(xùn)練模型或訓(xùn)練數(shù)據(jù)集可用,使用Temporal數(shù)據(jù)集作為基準(zhǔn)評估。
雖然Prompt2Model提供了自動模型評估的能力,在生成和檢索的數(shù)據(jù)測試上,但在這里使用真實的基準(zhǔn)數(shù)據(jù)集來衡量我們的管道訓(xùn)練準(zhǔn)確模型的能力。
在基線模型的選取上,由于該工作的主要目標(biāo)就是訓(xùn)練一個小模型可以與大型語言模型相匹配或是更強(qiáng),所以研究人員選擇gpt-3.5-turbo作為基準(zhǔn)數(shù)據(jù)集的對比基線。
實驗結(jié)果
在下游任務(wù)中的表現(xiàn)上,Prompt2Model在三個任務(wù)中的兩個都實現(xiàn)了遠(yuǎn)超gpt-3.5-turbo的性能。
值得注意的是,檢索到的SQuAD和Temporal模型是Flan-T5,僅有250M的參數(shù)量,比gpt-3.5-turbo(175B參數(shù))小700倍。
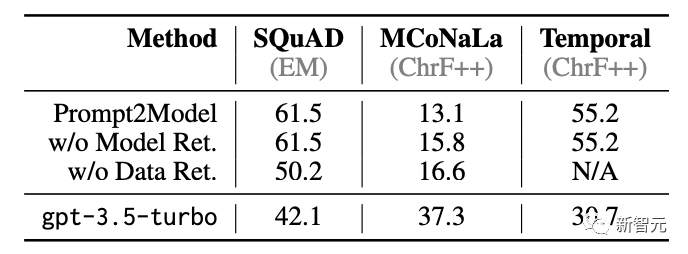
還可以觀察到,Prompt2Model在MCoNaLa的日語轉(zhuǎn)Python任務(wù)上的性能明顯比gpt-3.5-turbo差。
可能的解釋是,生成的日語查詢數(shù)據(jù)集多樣性相對較低:5000個樣本中有45個都是「在數(shù)字列表中找到最大值」的不同說法,而在其他數(shù)據(jù)集中沒有觀察到這種高的冗余度,表明gpt-3.5-turbo可能很難為非英語的語言生成多樣化的文本。
另一個原因可能是缺乏合適的學(xué)生模型,模型型檢索器找到的模型是在多種自然語言或代碼上訓(xùn)練的,沒有都是多語言的,導(dǎo)致預(yù)訓(xùn)練模型缺乏表征日語輸入、Python輸出相關(guān)的參數(shù)知識。